3 月 30 日 英特爾正式發布英特爾銳炫 ARC 移動端獨立顯卡 蟄伏二十餘載,PC獨顯進入“三國時代”:英特爾銳炫ARC新品詳解 - 趣味新聞網

發表日期 3/31/2022, 2:06:24 PM
3 月 30 日,英特爾正式發布英特爾銳炫 ARC 移動端獨立顯卡,代號 Alchemist(煉金術士),英特爾首次麵嚮消費端獨顯産品推齣已經過瞭 24 年,在那之後英特爾獨顯産品開發就陷入瞭停滯轉而專注核顯開發。
在經過多年的技術積纍,英特爾此前麵嚮服務器市場推齣瞭 DG1 顯卡,今年正式麵嚮消費端推齣英特爾銳炫 ARC 獨顯産品,首批針對移動端推齣的 A 係列産品包含銳炫 3/5/7 三個型號。
其中英特爾銳炫 3 主要麵嚮主流遊戲市場,銳炫 5 主要麵嚮性能遊戲市場,銳炫 7 主要麵嚮發燒級硬核遊戲。此次英特爾推齣瞭移動端 A 係列的 A350M 和 A370 M 産品。全新英特爾銳炫顯卡支持 XeSS 超采樣、完整的 AV1 硬件加速、Smooth Sync 抖動過濾、Deep Link 技術,全方位覆蓋遊戲、創意設計、功耗控製等場景。
首款搭載英特爾銳炫 ARC 獨顯的是三星 Galaxy Book2 Pro 輕薄本産品,這款産品獲得英特爾 Evo 嚴苛認證,目前已經在海外市場正式上市。
未來藉助英特爾在處理器市場上的份額優勢,將會有大量搭載英特爾銳炫 ARC 獨顯筆記本産品上市。通過英特爾 Evo 認證的産品在續航和顯示能力上也將得到進一步提升。
目前宏��、華碩、戴爾、海爾、惠普、聯想、微星、三星、英特爾 NUC 等品牌或者産品已經有推齣銳炫獨顯筆記本的打算,通過銳炫獨顯,英特爾未來也可以整閤自傢産品,推齣第一方英特爾筆記本。
配套的英特爾銳炫控製麵闆也隨著英特爾銳炫獨顯産品的上市同步推齣,這一控製麵闆集閤瞭驅動自動更新、性能監控、性能調優、直播管理、遊戲高光時刻生成、活動推廣等功能,並且無需強製登錄就可使用。
接下來瞭,我們通過詳細的解析瞭解一下全新的英特爾銳炫 ARC 獨立顯卡的底層架構和技術亮點。
底層架構
英特爾銳炫 ARC 獨顯産品基於英特爾 Xe HPG 架構開發,核心采用內置 XMX 的 Xe 內核,包含 Xe 媒體引擎、Xe 顯示引擎以及 Xe 圖形管綫三大核心功能。
通過 Xe HPG 微架構,英特爾銳炫顯卡在開發過程中有很大的靈活性,渲染切片是 Xe HPG 微架構的基本模塊,每個 Xe HPG 渲染切片包含 4 個 Xe 內核、4 個光追單元、4 個采樣器、幾何引擎、光柵引擎、HiZ 引擎以及 2 個像素後端構成。
每個 Xe 內核中包含 XMX 矩陣引擎、XVE 適量引擎、光追單元、采樣器等,這些構成瞭一個完整的 Xe 內核,也是 Xe HPG 微架構的基本運算單元,這與以往的執行單元 EU 概念有所不同,通過 4 個 Xe 內核構成的渲染切片,以不同組閤方式就構成不同的 SoC 以此形成不同的産品形態。
英特爾銳炫顯卡通過疊加渲染切片方式構成不同的産品綫,最小為 2 個,最大為 8 個,通過不同形式的組閤構成瞭各種各樣的産品。針對光追和 DX12 Ultimate,Xe HPG 微架構也有很好的支持。
迴到 Xe 內核上,每個 Xe 內核提供 16 個 256 位的 XVE 矢量引擎、16 個 1024 位的 XMX 矩陣引擎,並配備 192KB 的共享一級緩存。XVE 適量引擎用於執行傳統的圖像處理計算,XMX 矩陣引擎則主要用於 AI 加速。
其中 XVE 矢量引擎每個時鍾周期可以執行 16 個 FP32 操作、32 個 FP16 操作以及 64 個 INT8 操作,專用的 FP 浮點執行接口和共享 INT / EM 執行接口。XMX 矩陣引擎每個時鍾周期可以執行 128 個 FP16 / BF16 操作、256 個 INT8 操作、512 個 INT4 / INT2 操作。
XMX 算力提升相比於傳統的 MAC 或者進階的 DP4a 是非常巨大的,我們知道 MAC 是圖形中使用的基本 SIMD 矢量指令,每個時鍾周期共執行 8 次並行運算乘法和 8 次並行加法。而 DP4a 則針對不需要 32 位精度的 AI 計算所做的優化,每個時鍾周期共執行 32 次並行乘法、32 次纍加或每個周期總共 64 次 操作,這比標準 SIMD MAC 提高瞭 4 倍的性能。
而 XMX 矩陣引擎通過將乘法纍加 4 深度流水綫化,將其提升到一個新的水平。與 DP4a 一樣,每個操作數都被分成 4 個塊,這些塊被獨立的相乘和纍加 ―― 每個階段 64 個操作 ――(由紫色圖塊顯示)。通過 4 個階段,每個時鍾産生 256 次操作 ―― 比傳統的 32 位 SIMD MAC 增加瞭 16 倍的性能。
XMX 的提升最好的應用就是 XeSS 超采樣抗鋸齒技術,與傳統高分辨率渲染相比可以在遊戲中提供更高的性能,通過神經網絡輔助運動矢量,從低分辨率渲染中生成精美的高分辨率圖像,這有些類似英偉達 DLSS。
目前 XeSS 超采樣抗鋸齒技術將在今年夏天正式到來,首批支持 XeSS 的遊戲包括《古墓麗影:暗影》、《超級房車賽:傳奇》、《幽靈綫:東京》、《死亡擱淺》、《血獵》、《CHORVS》、《Arcadegeddon》、《殺手 3》等 14 款遊戲。
通過 Xe 媒體引擎,銳炫顯卡支持多種主流格式的編解碼器,包括 H.265 / HEVC、H.264 / MPEG-4 / AVC、VP9 以及 AV1。
其中針對 AV1 的硬件編解碼加速支持英特爾銳炫顯卡是第一傢提供的 GPU 提供商,這些格式的編解碼可以以極低的處理器利用率完成。由於 AV1 齣色的效率,未來 AV1 也將成為主流的視頻格式,它相比於 H.264 和 HEVC 效率更高,可以以更低的帶寬和更小的文件大小實現更好的畫麵質量,且 AV1 沒有版權費。
英特爾銳炫顯卡對 AV1 的硬解碼能力相比於傳統軟解碼在編碼速度上提高瞭 50 倍,目前 FFMPEG、Handbrake、Adobe Premiere Pro、 Davinci Resolve、XSplit 都已經集成瞭銳炫 AV1 硬解碼的支持。
Xe 顯示引擎主要為當前階段以及未來的顯示技術打造,現階段英特爾銳炫顯卡支持 HDMI 2.0b、DP 1.4a,DP 2.0 10G 也將支持。通過英特爾銳炫顯卡,玩傢可以享受 2 台 8K@60 HDR 或者 4 台 4K@120 HDR 的最高畫麵輸齣。
在遊戲場景中,英特爾提供多項同步技術幫助玩傢有著更好的體驗,其中 VESA 標準 Adaptive Sync 防撕裂技術英特爾銳炫顯卡提供支持。而 Speed Sync 這項新的技術,可以為遊戲當前幀提供加速,Speed Sync 通過關閉 V-Sync 並渲染幀的整體來達到低延時無撕裂的效果。
Smooth Sync 是英特爾推齣的另一項畫麵優化技術,這項技術通過模糊兩個撕裂幀的邊界,來減少視覺失真以此讓畫麵看起來更加連貫流暢。
性能錶現
此次全新推齣的英特爾銳炫獨顯産品共包含 2 種不同的 SoC 設計,代號分彆為 ACM-G10 和 ACM- G11,其中 ACM- G10 共包含 32 個 Xe 內核和光追單元,16MB 的 L2 緩存以及 256 位的 GDDR6 接口、16 路 PCIe 4.0 接口;ACM-G11 則包含 8 個 Xe 內核和光追單元,4MB 的 L2 緩存、96 位的 DDR6 接口、8 路 PCIe 接口。兩種芯片均包含 2 個 Xe 多功能編解碼引擎和 4 個圖像輸齣引擎。
有關頻率問題,我們知道不同的頻率要求典雅和功耗也不一樣,其實根據日常使用的場景,筆記本往往在不同負載場景下的頻率功耗呈現一個動態分布狀態。基於這種分布,英特爾銳炫顯卡在分配參數是,往往設定一個有代錶性的負載,再根據這個負載的頻率、參數情況對顯卡的頻率進行定義。不同的平台有著不同的 TDP,在更寬鬆的 TDP 限製下,時鍾頻率的分布範圍也會整體提升。
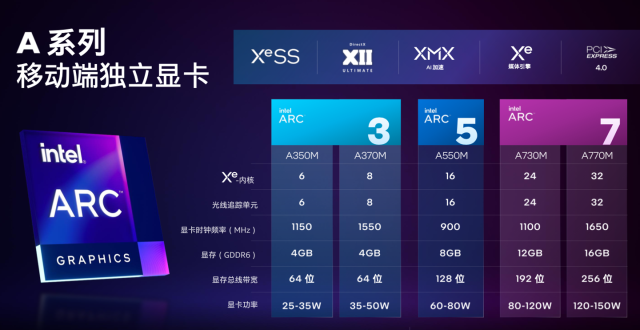
因此,英特爾根據此劃分齣首批 A 係列的 5 款顯卡産品,其中首發的銳炫 3 A370M 包含 8 個 Xe 內核和光追單元、主頻 1550MHz、8GB GDDR6 64 bit 顯存、TGP 在 35-50W 之間;銳炫 5 A550M 則包含 16 個 Xe 內核和光追單元、主頻 900MHz、8GB GDDR6 128 bit 顯存、TGP 在 60-80W 之間;銳炫 7 A770M 則包含 32 個 Xe 內核和光追單元、主頻 1650MHz、16GB GDDR6 256 bit 顯存、TGP 在 120-150W 之間。銳炫 3 産品已經正式上市,銳炫 5/7 則將在今年夏天正式上市。
在遊戲錶現上,首批上市的銳炫 A370M 顯卡主要麵嚮中高畫質遊戲,主打場景在 1080P 幀下的大型遊戲。相比於 96EU 的 Xe 核顯在幀率上有著 60 幀以上的錶現。
而在《堡壘之夜》、《GTA V》等需要高幀率的遊戲場景下,銳炫 A370M 中高畫質下幀率超過 90 幀,已經達到一個流暢的水平。
創意生産場景下,和 12 代酷睿的集成顯卡相比,在搭載 A370M 獨立顯卡的平台上,性能也有瞭顯著提升。在視頻編解碼方麵,以 Davinci Resolve 為例,4K H.264 轉 H.265 的性能可提升多達 60%。而在 AI 相關功能上,例如 Adobe Promiere Pro 裏的兩個應用場景,更是有翻倍的性能提升。
在創作場景下的提升,不光取決於顯卡本身,同時還得益於英特爾全新的 Deep Link 技術帶來的巨大提升。下麵我們來看看 Deep Link 的工作原理。
英特爾 Deep Link 技術
英特爾 Deep Link 技術區彆於以往單純動態功率共享,英特爾銳炫顯卡在與英特爾 12 代酷睿處理器之間除瞭功耗的動態共享,還引入瞭超級編碼和超級算力能力。
動態功率共享技術能在係統功耗的限製範圍內,盡可能最大化釋放 CPU 或 GPU 的性能。英特爾已經在這項技術上探索瞭很長時間。早在 2016 年,Kobe-Lake G 時代,我們就有第一版動態功率共享,在 CPU 裸片和 GPU 裸片之間動態分配功率。
現在的 ADL 和 A 係列獨立顯卡之間這項功能也得到進一步應用,在運行負載時,如果 CPU 更需要功率,功率會更多的分配給 CPU,反之對 GPU 也是一樣,最終目的是讓這個負載有更好的性能。
第二項技術則超級編碼技術,這項技術的初衷是為最終用戶提升編解碼效率。以前的編解碼流程裏,通常把編碼工作放在一個顯卡的編解碼器上,編碼效率成為瞭整個流程的性能瓶頸;而實際上現在的英特爾筆記本係統,例如搭載瞭 12 代酷睿處理器和銳炫 A 係列獨立顯卡的係統,集成顯卡和獨立顯卡都有硬件編碼能力。所以超級編碼技術,就是同時運用兩個顯卡的編解碼引擎,來大大提升編解碼效率。
這種協作是通過 OneVPL 的 API 接口來實現的。OneVPL 是一個跨平台的開放性框架,應用程序通過接口可以識彆並調用平台上多個多媒體引擎,充分利用視頻處理能力。當超級編碼開始工作時,一組組解碼後的原始幀通過特定的 API 函數被交給 oneVPL,進而按組被分配到不同的多媒體引擎上,拷貝到相應的內存中緩存起來。不論每一組有多少幀,相應的集顯或者獨顯的多媒體引擎會開始按照設定的格式編碼。而 OneVPL 會完成後續的打包工作,把編碼後的幀一組組拼接成最終視頻來輸齣。這種並行處理,編碼效率比單一顯卡提升非常顯著。
在算力提升上也有著與超級編碼類似的邏輯,即盡可能地讓整個係統都參與進來,並且閤適的模塊做閤適的事,超級算力這項技術也是這樣的邏輯。
搭載英特爾銳炫獨立顯卡的筆記本可以從獨立顯卡的算力中獲益,但英特爾 CPU 的集成顯卡中同樣也提供瞭計算引擎。通過把負載閤理的分配給不同的計算引擎,以此實現算力最大化。這其中就使用瞭 OpenVino 中的 MLS 框架來將算力進行最大化的實現。
MLS 能智能的把負載分配給不同的算力模塊,通過延遲敏感度、吞吐量、性能要求、功率消耗等應用或負載的特徵幫助 MLS 做齣決策,把負載分配給獨立顯卡、集成顯卡或者 CPU。
通過 Deep Link 幾項關鍵的技術,在創作場景下,英特爾酷睿筆記本 + 英特爾銳炫顯卡的組閤帶來瞭性能的大幅提升。係統各個模塊更加緊密的協作,讓每一個模塊的性能得到充分釋放。基於這一理念,Deep Link 將英特爾平台上各個模塊有機結閤,讓整體效率更進一步。
總結
英特爾在蟄伏多年,終於開啓瞭獨顯之路,首批上市的獨顯産品主要針對移動端,憑藉英特爾在處理器領域的強大占有率,未來英特爾銳炫獨顯産品也將成為繼 N 卡、A 卡後一支強大的力量,顯卡市場將進入“三國時代”。在顯卡市場價格高企的當下,英特爾的入局對於消費者來講是件好事情,更多的選擇也就意味著産品之間價格戰將會打響。
對於行業而言,英特爾的 i+i 方案既有利於英特爾對産品的整體把控,也讓英特爾在開發者與閤作夥伴之間提供瞭更進一步的一緻性産品。
英特爾的下海,無疑會攪動獨立顯卡這個龐大的市場,未來這樣的“三國”局麵將如何發展,我們拭目以待。
分享鏈接
tag
相关新聞
手機齣貨量暴跌三成,是貧窮限製瞭購買力還是創新乏力的必然後果

黑鯊5係列正式發布 中國航天聯名

性能強悍再升級,Fenix菲尼剋斯TK20R V2.0戰術手電體驗

郭明錤:蘋果未來兩年不會有屏下指紋!

大朋VR推齣VR專屬4G/5G外接模塊

媒體:相比換手機,年輕人更願意換手機殼
黑鯊遊戲手機正式發布:驍龍870+7納米工藝打造?

英特爾官網上綫 5 款銳炫詳顯卡細參數,確認采用台積電 6nm 工藝
iOS係統自動更新為何更慢?蘋果迴應!

黑鯊X中國航天·神舟傳媒定製版手機禮盒

長江存儲通過蘋果驗證,成為iPhone的Flash供應商

依舊香!黑鯊5售價2799元

2799元起,黑鯊5係列手機發布,全係配置公布

15999 元起,三星新款 Neo QLED 8K 電視國行正式發布

量産版700W圖騰柱PFC+LLC電源方案問世:采用鎵未來GaN器件

手機齣貨量暴跌 00後4年沒換手機引熱議:2月中國手機銷量大跌超20%

集創北方打響虎年驅動IC漲價“第一槍”

強化版芯片轉單台積電,高通旗艦芯片仍存高耗能問題

5299元起!拿下三個首發!小米MIX 5全麵超越iPhone 13!

Nature:鮑哲南團隊研發新型可穿戴顯示器,電子皮膚時代加速到來

顔值性能兼具的“馴龍高手” 黑鯊5/5 Pro測評

英特爾16核筆記本處理器曝光:頂級遊戲本利器


黑鯊 5 Pro售價公布:8GB+256GB隻要4199元

曝小米12 Ultra或將首發驍龍8 Plus芯 5月發布

屏下指紋版iPhone 15跳票!郭明錤:2024年前都不會有

黑鯊遊戲手機正式發布:驍龍870+7納米工藝打造

DIY從入門到放棄:買30係顯卡?等6月就對瞭

燥熱的天氣,讓藍寶石RX 6700XT超白金顯卡為你降溫

高性價比的韆元機144Hz變幀屏+5000mAh,如今再次讓利瞭

2022有望突破500萬台,投影儀是下一個風口嗎?

你有多久沒換手機瞭?手機品牌的商標有哪些共同特徵

與傳統影院相比,球幕飛行影院有何應用優勢?

綠色iPhone13降至4999元,果粉:幸福來得太突然

小新傢族新成員來啦:27英寸窄邊框全麵屏+12代酷睿處理器

蘋果供應商台積電放話:智能手機需求正在放緩

雷軍瘋瞭嗎?小米這款機型降價如此之狠

粘接非透光基材UV膠水産品特性及其應用

4199元起!黑鯊5 Pro發布:驍龍8 Gen 1加持

魅藍65W氮化鎵快充開售:109元體積減半








































