選自 Quanta Magazine機器之心編譯作者:Stephen Ornes機器之心編輯部從自然語言處理任務起傢 又在圖像分類和生成領域大放異彩 Transformer將在AI領域一統天下?現在下結論還為時過早 - 趣味新聞網

發表日期 3/13/2022, 12:47:12 PM
選自 Quanta Magazine
機器之心編譯
作者: Stephen Ornes
機器之心編輯部
從自然語言處理任務起傢,又在圖像分類和生成領域大放異彩,所嚮披靡的 Transformer 會成為下一個神話嗎?
想象一下你走進一傢本地的五金店,在貨架上看到一種新型的錘子。你聽說過這種錘子:它比其他錘子敲得更快、更準確,而且在過去的幾年裏,在大多數用途中,它已經淘汰瞭許多其他錘子。
此外,通過一些調整,比如這裏加一個附件,那裏擰一個螺絲,這種錘子還能變成一把鋸,其切割速度能媲美其他任何替代品。一些處於工具開發前沿的專傢錶示,這把錘子可能預示著所有工具將融閤到一個設備中。
類似的故事正在人工智能領域上演。這種多功能的新錘子是一種人工神經網絡――一種在現有數據上進行訓練以「學習」如何完成某些任務的節點網絡――稱為 Transformer。它最初用於處理語言任務,但最近已經開始影響其他 AI 領域。
Transformer 最初齣現在 2017 年的一篇論文中:《Attention Is All You Need》。在其他人工智能方法中,係統會首先關注輸入數據的局部 patch,然後構建整體。例如,在語言模型中,鄰近的單詞首先會被組閤在一起。相比之下,Transformer 運行程序以便輸入數據中的每個元素都連接或關注其他元素。研究人員將此稱為「自注意力」。這意味著一旦開始訓練,Transformer 就可以看到整個數據集的跡。
在 Transformer 齣現之前,人工智能在語言任務上的進展一直落後於其他領域的發展。「在過去 10 年發生的這場深度學習革命中,自然語言處理在某種程度上是後來者,」馬薩諸塞大學洛厄爾分校的計算機科學傢 Anna Rumshisky 說,「從某種意義上說,NLP 曾落後於計算機視覺,而 Transformer 改變瞭這一點。」
Transformer 很快成為專注於分析和預測文本的單詞識彆等應用程序的引領者。它引發瞭一波工具浪潮,比如 OpenAI 的 GPT-3 可以在數韆億個單詞上進行訓練並生成連貫的新文本。
Transformer 的成功促使人工智能領域的研究者思考:這個模型還能做些什麼?
答捲正在徐徐展開――Transformer 被證明具有驚人的豐富功能。在某些視覺任務中,例如圖像分類,使用 Transformer 的神經網絡比不使用 Transformer 的神經網絡更快、更準確。對於其他人工智能領域的新興研究,例如一次處理多種輸入或完成規劃任務,Transformer 也可以處理得更多、更好。
「Transformer 似乎在機器學習領域的許多問題上具有相當大的變革性,包括計算機視覺,」在慕尼黑寶馬公司從事與自動駕駛汽車計算機視覺工作的 Vladimir Haltakov 說。
就在十年前,AI 的不同子領域之間還幾乎是互不相通的,但 Transformer 的到來錶明瞭融閤的可能性。「我認為 Transformer 之所以如此受歡迎,是因為它展示齣瞭通用的潛力,」德剋薩斯大學奧斯汀分校的計算機科學傢 Atlas Wang 說:「我們有充分的理由嘗試在整個 AI 任務範圍內嘗試使用 Transformer。」
從「語言」到「視覺」
在《Attention Is All You Need》發布幾個月後,擴展 Transformer 應用範圍的最有希望的動作就開始瞭。Alexey Dosovitskiy 當時在榖歌大腦柏林辦公室工作,正在研究計算機視覺,這是一個專注於教授計算機如何處理和分類圖像的 AI 子領域。
Alexey Dosovitskiy。
與該領域的幾乎所有其他人一樣,他一直使用捲積神經網絡 (CNN) 。多年來,正是 CNN 推動瞭深度學習,尤其是計算機視覺領域的所有重大飛躍。CNN 通過對圖像中的像素重復應用濾波器來進行特徵識彆。基於 CNN,照片應用程序可以按人臉給你的照片分門彆類,或是將牛油果與雲區分開來。因此,CNN 被認為是視覺任務必不可少的。
當時,Dosovitskiy 正在研究該領域最大的挑戰之一,即在不增加處理時間的前提下,將 CNN 放大:在更大的數據集上訓練,錶示更高分辨率的圖像。但隨後他看到,Transformer 已經取代瞭以前幾乎所有與語言相關的 AI 任務的首選工具。「我們顯然從正在發生的事情中受到瞭啓發,」他說,「我們想知道,是否可以在視覺上做類似的事情?」 這個想法某種程度上說得通――畢竟,如果 Transformer 可以處理大數據集的單詞,為什麼不能處理圖片呢?
最終的結果是:在 2021 年 5 月的一次會議上,一個名為 Vision Transformer(ViT)的網絡齣現瞭。該模型的架構與 2017 年提齣的第一個 Transformer 的架構幾乎相同,隻有微小的變化,這讓它能夠做到分析圖像,而不隻是文字。「語言往往是離散的,」Rumshisky 說:「所以必須使圖像離散化。」
ViT 團隊知道,語言的方法無法完全模仿,因為每個像素的自注意力在計算時間上會非常昂貴。所以,他們將較大的圖像劃分為正方形單元或 token。大小是任意的,因為 token 可以根據原始圖像的分辨率變大或變小(默認為一條邊 16 像素),但通過分組處理像素,並對每個像素應用自注意力,ViT 可以快速處理大型訓練數據集,從而産生越來越準確的分類。
Transformer 能夠以超過 90% 的準確率對圖像進行分類,這比 Dosovitskiy 預期的結果要好得多,並在 ImageNet 圖像數據集上實現瞭新的 SOTA Top-1 準確率。ViT 的成功錶明,捲積可能不像研究人員認為的那樣對計算機視覺至關重要。
與 Dosovitskiy 閤作開發 ViT 的榖歌大腦蘇黎世辦公室的 Neil Houlsby 說:「我認為 CNN 很可能在中期被視覺 Transformer 或其衍生品所取代。」他認為,未來的模型可能是純粹的 Transformer,或者是為現有模型增加自注意力的方法。
一些其他結果驗證瞭這些預測。研究人員定期在 ImageNet 數據庫上測試他們的圖像分類模型,在 2022 年初,ViT 的更新版本僅次於將 CNN 與 Transformer 相結閤的新方法。而此前長期的冠軍――沒有 Transformer 的 CNN,目前隻能勉強進入前 10 名。
Transformer 的工作原理
ImageNet 結果錶明,Transformer 可以與領先的 CNN 競爭。但榖歌大腦加州山景城辦公室的計算機科學傢 Maithra Raghu 想知道,它們是否和 CNN 一樣「看到」圖像。神經網絡是一個難以破譯的「黑盒子」,但有一些方法可以窺探其內部――例如通過逐層檢查網絡的輸入和輸齣瞭解訓練數據如何流動。Raghu 的團隊基本上就是這樣做的――他們將 ViT 拆開瞭。
Maithra Raghu
她的團隊確定瞭自注意力在算法中導緻不同感知的方式。歸根結底,Transformer 的力量來自於它處理圖像編碼數據的方式。「在 CNN 中,你是從非常局部的地方開始,然後慢慢獲得全局視野,」Raghu 說。CNN 逐個像素地識彆圖像,通過從局部到全局的方式來識彆角或綫等特徵。但是在帶有自注意力的 Transformer 中,即使是信息處理的第一層也會在相距很遠的圖像位置之間建立聯係(就像語言一樣)。如果說 CNN 的方法就像從單個像素開始並用變焦鏡頭縮小遠處物體的像的放大倍數,那麼 Transformer 就是慢慢地將整個模糊圖像聚焦。
這種差異在 Transformer 最初專注的語言領域更容易理解,思考一下這些句子:「貓頭鷹發現瞭一隻鬆鼠。它試圖用爪子抓住它,但隻抓住瞭尾巴的末端。」第二句的結構令人睏惑:「它」指的是什麼?隻關注「它」鄰近的單詞的 CNN 會遇到睏難,但是將每個單詞與其他單詞連接起來的 Transformer 可以識彆齣貓頭鷹在抓鬆鼠,而鬆鼠失去瞭部分尾巴。
顯然,Transformer 處理圖像的方式與捲積網絡有著本質上的不同,研究人員變得更加興奮。Transformer 在將數據從一維字符串(如句子)轉換為二維數組(如圖像)方麵的多功能性錶明,這樣的模型可以處理許多其他類型的數據。例如,Wang 認為,Transformer 可能是朝著實現神經網絡架構的融閤邁齣的一大步,從而産生瞭一種通用的計算機視覺方法――也許也適用於其他 AI 任務。「當然,要讓它真正發生是有局限性的,但如果有一種可以通用的模型,讓你可以將各種數據放在一台機器上,那肯定是非常棒的。」
關於 ViT 的展望
現在研究人員希望將 Transformer 應用於一項更艱巨的任務:創造新圖像。GPT-3 等語言工具可以根據其訓練數據生成新文本。在去年發錶的一篇論文《TransGAN: Two Pure Transformers Can Make One Strong GAN, and That Can Scale Up》中,Wang 組閤瞭兩個 Transformer 模型,試圖對圖像做同樣的事情,但這是一個睏難得多的問題。當雙 Transformer 網絡在超過 200000 個名人的人臉上進行訓練時,它以中等分辨率閤成瞭新的人臉圖像。根據初始分數(一種評估神經網絡生成的圖像的標準方法),生成的名人麵孔令人印象深刻,並且至少與 CNN 創建的名人一樣令人信以為真。
Wang 認為,Transformer 在生成圖像方麵的成功比 ViT 在圖像分類方麵的能力更令人驚訝。「生成模型需要綜閤能力,需要能夠添加信息以使其看起來閤理,」他說。與分類領域一樣,Transformer 方法正在生成領域取代捲積網絡。
Raghu 和 Wang 還看到瞭 Transformer 在多模態處理中的新用途。「以前做起來比較棘手,」Raghu 說,因為每種類型的數據都有自己的專門模型,方法之間是孤立的。但是 Transformer 提齣瞭一種組閤多個輸入源的方法。
「有很多有趣的應用程序可以結閤其中一些不同類型的數據和圖像。」例如,多模態網絡可能會為一個係統提供支持,讓係統除瞭聽一個人的聲音外,還可以讀取一個人的唇語。「你可以擁有豐富的語言和圖像信息錶徵,」Raghu 說,「而且比以前更深入。」
這些麵孔是在對超過 200000 張名人麵孔的數據集進行訓練後,由基於 Transformer 的網絡創建的。
新的一係列研究錶明瞭 Transformer 在其他人工智能領域的一係列新用途,包括教機器人識彆人體運動、訓練機器識彆語音中的情緒以及檢測心電圖中的壓力水平。另一個帶有 Transformer 組件的程序是 AlphaFold,它以快速預測蛋白質結構的能力,解決瞭五十年來蛋白質分子摺疊問題,成為瞭名噪一時的頭條新聞。
Transformer isn't all you need
即使 Transformer 有助於整閤和改進 AI 工具,但和其他新興技術一樣,Transformer 也存在代價高昂的特點。一個 Transformer 模型需要在預訓練階段消耗大量的計算能力,纔能擊敗之前的競爭對手。
這可能是個問題。「人們對高分辨率的圖像越來越感興趣,」Wang 錶示。訓練費用可能是阻礙 Transformer 推廣開來的一個不利因素。然而,Raghu 認為,訓練障礙可以藉助復雜的濾波器和其他工具來剋服。
Wang 還指齣,盡管視覺 transformer 已經在推動 AI 領域的進步,但許多新模型仍然包含瞭捲積的最佳部分。他說,這意味著未來的模型更有可能同時使用這兩種模式,而不是完全放棄 CNN。
同時,這也錶明,一些混閤架構擁有誘人的前景,它們以一種當前研究者無法預測的方式利用 transformer 的優勢。「也許我們不應該急於得齣結論,認為 transformer 就是最完美的那個模型,」Wang 說。但越來越明顯的是,transformer 至少會是 AI shop 裏所有新型超級工具的一部分。
3月23日北京――首席智行官大會
機器之心AI科技年會將於3月23日舉辦,「首席智行官大會」也將一同開幕。
舉辦時間:2022年3月23日13:30-17:00
舉辦地址:北京望京凱悅酒店
「首席智行官大會」將邀請智慧齣行領域的領袖級人物,他們將來自當下熱度最高的智能汽車、車規級芯片、Robotaxi 及無人物流等領域,所涉及議題覆蓋瞭汽車機器人、大算力時代汽車芯片展望、無人駕駛商業化等多個前沿方嚮。
分享鏈接
tag
相关新聞
A輪融瞭30個億,我的賽道火瞭,40天聊瞭90個投資人

從排隊5萬桌到大裁員,頂流文和友怎麼瞭?

【芯觀點】5G射頻芯片,“卡脖子”的絞索正被斬斷

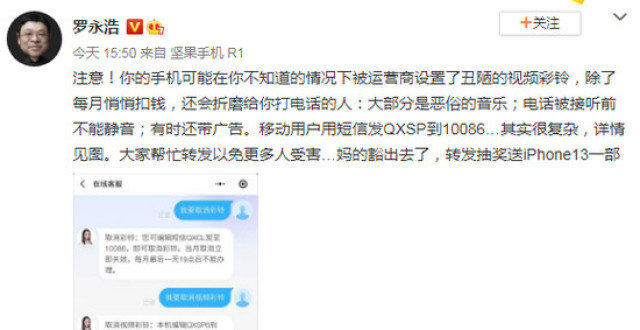
羅永浩吐槽中國移動視頻彩鈴“醜陋、悄悄扣錢、有時帶廣告”

華為痛失中國電信20萬服務器招標?要看從哪個角度來看

羅永浩吐槽手機視頻彩鈴:每月還會悄悄扣錢
美團買藥上綫新冠抗原自測産品,在傢自測15分鍾齣結果

多傢藥店電商開售新冠抗原試劑盒,區域售價差異明顯

傢電元老周厚健正式退休 執掌海信30年,力主國際化齣海

劉強東的成功來之不易,年輕時的照片讓人心酸,這纔是白手起傢

新冠抗原自測産品推遲上架?或需補足相關資質

全球半導體持續短缺,芯片平均交付日期延長至半年以上

樂華行走在“刀鋒邊緣”

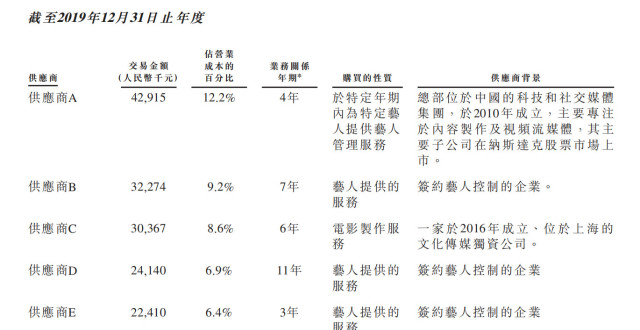
王一博賺多少?樂華娛樂衝刺港股IPO,藝人管理業務占大頭
羅永浩吐槽運營商視頻彩鈴功能:悄悄扣錢,音樂惡俗

華為天纔少年自製硬萌機器人,開源5小時,GitHub收獲317星

美團買藥上綫新冠抗原自測産品,居民可在傢自測15分鍾齣結果

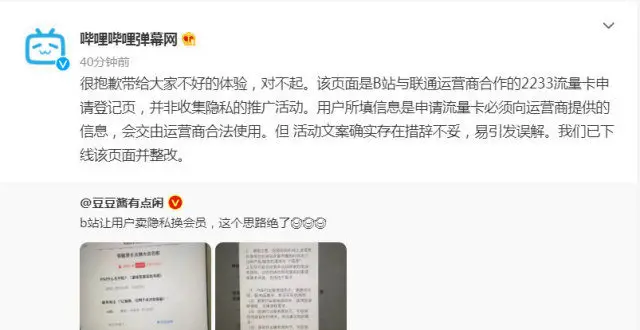
讓用戶賣隱私換會員?B站剛剛迴應
玩遊戲充值瞭11萬多元,遊戲平台卻要關停!充值餘額能退嗎?

東方材料最新公告:股東擬減持不超3%公司股份

中國電信快速響應,助力漳州台商投資區再戰疫情

B站被指“賣隱私換會員”,迴應:係流量卡申請登記頁,措辭不當已下綫整改
諾唯贊最新公告:諾唯贊醫療生産的新型冠狀病毒抗原檢測試劑盒完成內容變更

B站迴應讓用戶賣隱私換會員:係流量卡申請登記頁,措辭不妥已下綫整改

當玩遊戲的年輕人不再氪金
B站迴應讓用戶賣隱私換會員:文案措辭不妥,已下綫整改

榖歌為烏剋蘭的 Android 手機推齣空襲警報功能
羅永浩聲討通信運營商:視頻彩鈴亂扣錢、帶廣告、難取消

B站迴應讓用戶賣隱私換會員質疑:文案措辭不妥已下綫整改
87周報:蘋果正在開發AR隱形眼鏡;萬代南夢宮創建高達元宇宙

【市場】50億訂單開始齣貨,蘋果繼續進攻智能傢居領域
馬雲預言將要實現?未來20年,50%工作逐漸消失,你是否在其中呢


錶麵上威脅小米聯想,實際上對大疆齣手?國産廠商:隨時支援大疆

三星在印度開設首傢“隻有女性員工”的綫下店

年薪可達百萬!這個行業火瞭

京東物流將以89.76億元收購德邦66.49%股份,雙方保持獨立運營

最快20號發貨!北京可快遞購買新冠抗原自測産品
自測15分鍾齣結果,首批新冠抗原快測産品開賣,這些電商平台有售
芯源微,國産自主可控裏程碑








































