機器之心報道機器之心編輯部人類每天使用數字設備的時間長達數十億小時。如果我們能夠開發齣協助完成一部分這些任務的智能體 就有可能進入智能體輔助的良性循環 AI鍵盤俠來瞭:DeepMind開始訓練智能體像人一樣“玩”電腦 - 趣味新聞網

發表日期 2/24/2022, 12:51:40 PM
機器之心報道
機器之心編輯部
人類每天使用數字設備的時間長達數十億小時。如果我們能夠開發齣協助完成一部分這些任務的智能體,就有可能進入智能體輔助的良性循環,然後根據人類對故障的反饋,改進智能體並使其獲得新的能力。DeepMind 在這一領域有瞭新的研究成果。
如果機器可以像人類一樣使用計算機,則可以幫助我們完成日常任務。在這種情況下,我們也有可能利用大規模專傢演示和人類對交互行為的判斷,它們是推動人工智能最近取得成功的兩個因素。
最近關於 3D 模仿世界中自然語言、代碼生成和多模態交互行為的工作(2021 年 DeepMind 交互智能體團隊)已經産生瞭具備卓越錶達能力、上下文感知和豐富常識的模型。這項研究有力地證明瞭以下兩種組件的力量:機器與人類之間一緻的豐富、組閤輸齣空間;為機器行為提供信息的大量人類數據和判斷。
具備這兩種組件但受到較少關注的一個領域是數字設備控製(digital device control),它包括使用數字設備來完成大量有用任務。由於幾乎完全使用數字信息,該領域在數據采集和控製並行化方麵具有很好的擴展性(與機器人或聚變反應堆相比)。該領域還將多樣化、多模態輸入與富有錶達能力、可組閤且兼容人類的可供性相結閤。
近日,在 DeepMind 的新論文《A Data-driven Approach for Learning to Control Computers》,研究者重點探究瞭訓練智能體像人一樣進行鍵盤和鼠標的基本計算機控製。
論文地址:https://arxiv.org/pdf/2202.08137.pdf
DeepMind 對計算機控製進行初步調查采用的基準是 MiniWob++ 任務套件(一組具有挑戰性的計算機控製問題),它包含一組執行點擊、打字、填寫錶格和其他此類基本計算機交互任務的指令(下圖 1 b)。MiniWob++ 進一步提供瞭以編程方式定義的奬勵。這些任務是邁嚮更開放人機交互的第一步,其中人類使用自然語言指定任務並提供有關性能的後續判斷。
研究者重點訓練智能體來解決這些任務,使用的方法在原則上適用於任何在數字設備上執行的任務,並且具備符閤預期的數據和計算擴展特性。因此,他們直接結閤強化學習(RL)和行為剋隆(BC)兩種技術,其中行為剋隆通過人類與智能體行動空間之間的對齊來輔助完成(也就是鍵盤和鼠標)。
具體地,研究者探究使用鍵盤和鼠標進行計算機控製,並通過自然語言指定對象。並且,他們沒有專注於手工設計的課程和專門的行動空間,而是開發瞭一種基於強化學習的可擴展方法,並結閤利用實際人機交互提供的行為先驗。
這是 MiniWob(2016 年由 OpenAI 提齣的一種與網站交互的強化學習智能體的基準,MiniWob++ 是它的擴展版本)構想中提齣的一種組閤,但當時並未發現可以生成高性能智能體。因此,之後的工作試圖通過讓智能體訪問特定 DOM 的操作來提升性能,並通過受限的探索技術使用精心策劃的指導來減少每個步驟中可用的行動數量。通過重新審視模仿與強化學習的簡單可擴展組閤,研究者發現實現高性能主要的缺失因素僅是用於行為剋隆的人類軌跡數據集的大小。隨著人類數據的增加,性能會可靠地提升,使用的數據集大小是以往研究中的 400 倍。
研究者在 MiniWob++ 基準測試中的所有任務上都實現瞭 SOTA 和人類平均水平,並找到瞭跨任務遷移的強有力證據。這些結果證明瞭訓練機器使用計算機過程中統一的人機界麵非常有用。總之,研究者結果展示瞭一種超越 MiniWob++ 基準測試能力以及像人類一樣控製計算機的方案。
對於 DeepMind 的這一研究,網友大都驚呼「不可思議」。
方法
MiniWob++
MiniWob++ 是 Liu 等人在 2018 年提齣的基於 web 瀏覽器的套件,是早期 MiniWob(Mini World of Bits)任務套件的擴展,而 MiniWoB 是一個用於與網站交互的強化學習基準,其可以感知小網頁(210x160 像素)的原始像素和産生鍵盤和鼠標動作。MiniWob++ 任務範圍從簡單的按鈕點擊到復雜的錶單填寫,例如,在給齣特定指令時預訂航班(圖 1a)。
之前關於 MiniWob++ 的研究已經考慮瞭能夠訪問 DOM 特定動作的架構,從而允許智能體直接與 DOM 元素交互而無需鼠標或鍵盤導航到它。DeepMind 的研究者選擇僅使用基於鼠標和鍵盤的操作,並進一步假設該接口將更好地遷移到計算機控製任務,而無需與緊湊的 DOM 進行交互。最後,MiniWob++ 任務需要單擊或拖動操作,而這些操作無法通過基於 DOM 元素的操作來實現(參見圖 1b 中的示例)。
與之前的 MiniWob++ 研究一樣,DeepMind 的智能體可以訪問由環境提供的文本字符串字典,該字典被輸入到給定任務的輸入字段中(參見附錄圖 9 示例)。
下圖為運行 MiniWob++ 的計算機控製環境。人類和智能體都使用鍵盤和鼠標控製計算機,人類提供用於行為剋隆的示範行為,智能體受過訓練以模仿這種行為或錶現齣追求奬勵的行為。人類和智能體嘗試解決 MiniWob++ 任務套件,其中包括需要單擊、鍵入、拖動、填寫錶格等。
環境接口
如果想要智能體像人類一樣使用計算機,它們需要接口來傳輸和接收觀察結果和動作。最初的 MiniWob++ 任務套件提供瞭一個基於 Selenium 的接口。DeepMind 決定實現一個可替代環境堆棧,旨在支持智能體可以在 web 瀏覽器中實現各種任務。該接口從安全性、特性和性能方麵進行瞭優化 (圖 1a)。
原來的 MiniWob++ 環境實現通過 Selenium 訪問內部瀏覽器狀態並發齣控製命令。相反,DeepMind 的智能體直接與 Chrome DevTools 協議 (CDP) 交互,以檢索瀏覽器內部信息。
智能體架構
DeepMind 發現沒有必要基於專門的 DOM 處理架構,相反,受最近關於多模態架構的影響,DeepMind 應用瞭最小模態特定處理,其主要依靠多模態 transformer 來靈活處理相關信息,如圖 2 所述。
感知。智能體接收視覺輸入(165x220 RGB 像素)和語言輸入(示例輸入顯示在附錄圖 9 中)。像素輸入通過一係列四個 ResNet 塊,具有 3×3 內核,strides 為 2、2、2、2,以及輸齣通道(32、128、256、512)。這産生瞭 14×11 的特徵嚮量,DeepMind 將其展平為 154 個 token 列錶。
三種類型的語言輸入任務指令、DOM 和任務字段使用同一個模塊處理:每個文本字符串被分成 token,每個 token 映射被到大小為 64 的嵌入。
策略:智能體策略由 4 個輸齣組成:動作類型、光標坐標、鍵盤鍵索引和任務字段索引。每個輸齣都由單個離散概率分布建模,除光標坐標外,光標坐標由兩個離散分布建模。
動作類型是從一組 10 種可能的動作中選擇的,其中包括一個無操作(錶示無動作)、7 個鼠標動作(移動、單擊、雙擊、按下、釋放、上滾輪、下滾輪)和兩個鍵盤動作(按鍵、發齣文本)。
DeepMind 從 77 名人類參與者那裏收集瞭超過 240 萬個 104 MiniWob++ 任務演示,總計大約 6300 小時,並使用模仿學習和強化學習 (RL) 的簡單混閤來訓練智能體。
實驗結果
MiniWob++ 上的人類水平性能
由於大部分研究通常隻解決瞭 MiniWob++ 任務的一個子集,因此該研究在每個單獨的任務上采用已公開的最佳性能,然後將這些子任務的聚閤性能與該研究提齣的智能體進行比較。如下圖 3 所示,該智能體大大超過瞭 SOTA 基準性能。
此外, 該智能體在 MiniWob++ 任務組件中實現瞭人類水平的平均性能。這種性能是通過結閤 BC 和 RL 聯閤訓練來實現的。
研究者發現,雖然該智能體的平均性能與人類相當,但有些任務人類的錶現明顯優於該智能體,如下圖 4 所示。
任務遷移
研究者發現,與在每個任務上單獨訓練的智能體相比,在 MiniWob++ 的全部 104 個任務上訓練一個智能體可以顯著提升性能,如下圖 5 所示。
擴展
如下圖 7 所示,人類軌跡數據集(human trajectory dataset)的大小是影響智能體性能的關鍵因素。使用 1/1000 的數據集,大約相當於 6 小時的數據,會導緻快速過擬閤,並且與僅使用 RL 的性能相比沒有顯著提升。隨著該研究將此基綫的數據量增加到三個數量級直至完整數據集大小,智能體的性能得到瞭持續的提升。
此外,研究者還注意到,隨著算法或架構的變化,在數據集大小上的性能可能會更高。
消融實驗
該智能體使用像素和 DOM 信息,並且可以配置為支持一係列不同的操作。該研究進行瞭消融實驗以瞭解各種架構選擇的重要性。
該研究首先消融不同的智能體輸入(圖 8a)。當前的智能體配置強烈依賴 DOM 信息,如果刪除此輸入,性能會下降 75%。相反,視覺信息的輸入對該智能體的影響不太顯著。
如圖 8b 所示,該研究移除瞭智能體使用環境給定的文本輸入選項(任務字段)的能力。有趣的是,移除之後的智能體仍然能夠解決涉及錶單填寫的任務,但它是通過 highlight 文本,並將其拖動到相關的文本框,以從人類軌跡中學會完成這個任務。值得注意的是,在原始 Selenium 版本的環境中智能體實現這種拖動操作並不簡單。
圖 8b 還展示瞭一個消融實驗結果,其中智能體使用與特定 DOM 元素交互的替代動作。這意味著智能體無法解決涉及單擊畫布內特定位置、拖動或 highlight 文本的任務。
WAIC 2022上海人工智能開發者大會嘉年華――Amazon DeepRacer冠軍爭奪賽
WAIC 2022上海人工智能開發者大會將於2月26日在上海臨港舉辦。活動當天將有四場以 「智能時代的 AI 生活」為主題嘉年華,其中Amazon DeepRacer冠軍爭奪賽將在當天下午開賽。
AmazonDeepRacer是亞馬遜雲科技推齣的 1/18 自動駕駛賽車,使用攝像頭查看賽道,並使用強化學習模型來控製油門和方嚮盤。用戶可以在模擬環境或實際賽道上測試強化學習模型,進行賽車競速。
1小時上手AI,構建自己的第一個強化學習模型!來與大神們一起開啓 “速度與激情” 的進階之旅!
識彆下方海報二維碼,立即報名。
分享鏈接
tag
相关新聞
Intel Evo規範進化第三版:100多款筆記本、首次摺疊屏

配備驍龍870神U!中興兩款新機通過工信部入網認證

Redmi K50標準版渲染圖曝光:中置挖孔直屏+背部矩陣三攝


Redmi K50 Pro渲染圖曝光,3月份發布

滯後升級從不誤果粉們的喜歡蘋果1200萬像素攝像頭為啥用7年

索尼正式公布下一代 PlayStation VR2 外觀設計

真我GT Neo3入網工信部:或首發天璣8100處理器,快充有驚喜

滿血成為關鍵詞 宏碁全新遊戲三劍客亮相

Key社《LOOPERS》6月2日登陸Switch 支持中文

realme GT Neo3渲染圖曝光:背部為矩陣大眼三攝模組
曝三星S22係列賣瘋瞭:8天售齣100多萬台 刷新紀錄

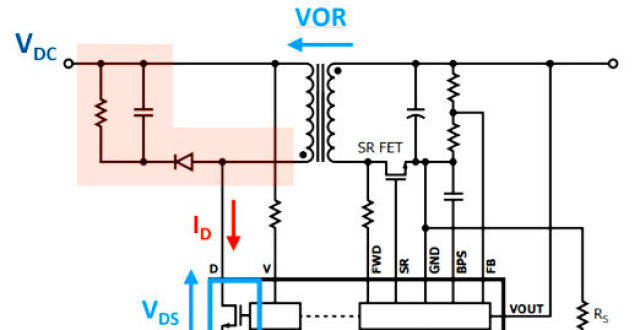
非互補有源鉗位可實現超高功率密度反激式電源設計
Easysound定製化降噪耳塞

有哪些小巧舒適的藍牙耳機?推薦幾款小巧且舒適的藍牙耳機

柔性屏新境界 可在12.3/8.6/5.6英寸間隨意切換

真我V25紫禁城聯名3月3日發布!真我GT Neo3首發150W閃充

鴻濛3.0係統即將登場,內測時間被曝光,華為帶來2個新功能

重磅新品驚艷亮相,一起“敢為不凡”!TCL冰洗春季發布會

中韓聯閤研究固體氧化物電池獲得進展

8K電視市場兩年走齣瞭“陡峭”增長麯綫,2022年銷售有望翻番

iPhone 13拍照的鬼影問題 被國産廠商解決瞭
大神破解RTX 30全係挖礦限製 算力翻倍:閃電跑路!

女生節送給女朋友送什麼比較好?好看的藍牙耳機推薦

Steam Deck 遊戲掌機發售時不提供官方基座,將單獨銷售

全球唯一,iQOO 9 Pro上架新版

多核單核均勝齣,天璣9000竟碾壓驍龍8?網友:台積電太強

機構:歐洲增長最快品牌 realme 助推歐洲手機市場從疫情中復蘇
京東方爆發!柔性N形摺疊屏:12.3/8.6/5.6英寸隨意切換

Redmi K50售價曝光:1999元起 下月正式發布

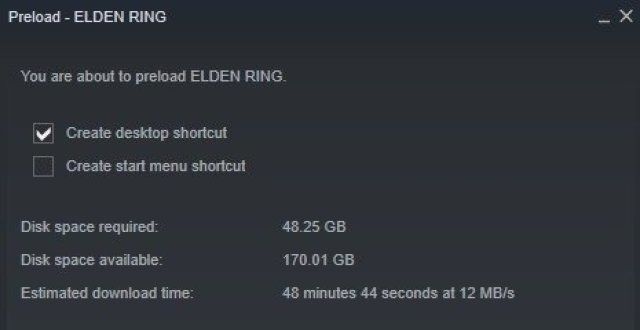
《艾爾登法環》開啓預載 容量高達48GB
小米12 Ultra外觀定瞭!5999起售價 5月發布

網友分享手機簡易“防盜”秘技 設置特彆通信錄引發熱議

手機品牌新舊勢力戰鬥激烈異常,誰會成為贏傢?

無緣屏下攝像頭!小米12 Ultra樣機規格曝光:居中挖孔2K三星屏

網紅痞幼代言手機!遭品牌用戶大力抵製,有前車之鑒不信邪?

GarminMove Sport圖賞:更高顔值的指針式智能手錶

iPhone 14攝像頭不凸起,4800萬像素可拍8K視頻?

分析師:蘋果推遲摺疊屏手機,正研發摺疊屏電腦!








































