讓AI根據一個畫麵 就推測齣後麵的內容 隻用一張圖+相機走位,AI就能腦補周圍環境|CVPR2022 - 趣味新聞網

發表日期 3/21/2022, 3:23:26 PM
站在門口看一眼,AI就能腦補齣房間裏麵長什麼樣:
是不是有綫上VR看房那味兒瞭?
不隻是室內效果,來個遠景長鏡頭航拍也是so easy:
而且渲染齣的圖像通通都是高保真效果,仿佛是用真相機拍齣來的一樣。
最近一段時間,用2D圖片閤成3D場景的研究火瞭一波又一波。
但是過去的許多研究,閤成場景往往都局限在一個範圍比較小的空間裏。
比如此前大火的NeRF,效果就是圍繞畫麵主體展開。
這一次的新進展,則是將視角進一步延伸,更側重讓AI預測齣遠距離的畫麵。
比如給齣一個房間門口,它就能閤成穿過門、走過走廊後的場景瞭。
目前,該研究的相關論文已被CVPR2022接收。
輸入單張畫麵和相機軌跡
讓AI根據一個畫麵,就推測齣後麵的內容,這個感覺是不是和讓AI寫文章有點類似?
實際上,研究人員這次用到的正是NLP領域常用的 Transformer 。
他們利用 自迴歸Transformer 的方法,通過輸入單個場景圖像和攝像機運動軌跡,讓生成的每幀畫麵與運動軌跡位置一一對應,從而閤成齣一個遠距離的長鏡頭效果。
整個過程可以分為兩個階段。
第一階段先預訓練瞭一個 VQ-GAN ,可以把輸入圖像映射到token上。
VQ-GAN是一個基於Transformer的圖像生成模型,其最大特點就是生成的圖像非常 高清 。
在這部分,編碼器會將圖像編碼為離散錶示,解碼器將錶示映射為高保真輸齣。
第二階段,在將圖像處理成token後,研究人員用瞭類似GPT的架構來做 自迴歸 。
具體訓練過程中,要將輸入圖像和起始相機軌跡位置編碼為特定模態的token,同時添加一個解耦的位置輸入P.E.。
然後,token被喂給自迴歸Transformer來預測圖像。
模型從輸入的單個圖像開始推理,並通過預測前後幀來不斷增加輸入。
研究人員發現,並非每個軌跡時刻生成的幀都同樣重要。因此,他們還利用瞭一個 局部性約束 來引導模型更專注於關鍵幀的輸齣。
這個局部性約束是通過攝像機軌跡來引入的。
基於兩幀畫麵所對應的攝像機軌跡位置,研究人員可以定位重疊幀,並能確定下一幀在哪。
為瞭結閤以上內容,他們利用MLP計算瞭一個“相機感知偏差”。
這種方法會使得在優化時更加容易,而且對保證生成畫麵的一緻性上,起到瞭至關重要的作用。
實驗結果
本項研究在RealEstate10K、Matterport3D數據集上進行實驗。
結果顯示,相較於 不規定相機軌跡 的模型,該方法生成圖像的質量更好。
與離散相機軌跡的方法相比,該方法的效果也明顯更好。
作者還對模型的注意力情況進行瞭可視化分析。
結果顯示,運動軌跡位置附近貢獻的注意力更多。
在消融實驗上,結果顯示該方法在Matterport3D數據集上,相機感知偏差和解耦位置的嵌入,都對提高圖像質量和幀與幀之間的一緻性有所幫助。
兩位作者均是華人
Xuanchi Ren為香港科技大學本科生。
他曾在微軟亞研院實習過,2021年暑期與Xiaolong Wang教授有過閤作。
Xiaolong Wang是加州大學聖地亞哥分校助理教授。
他博士畢業於卡內基梅隆大學機器人專業。
研究興趣有計算機視覺、機器學習和機器人等。特彆自我監督學習、視頻理解、常識推理、強化學習和機器人技術等領域。
論文地址:https://xrenaa.github.io/look-outside-room/
分享鏈接
tag
相关新聞
羅永浩闢謠“下個月還清債務”:還清後會主動官宣

羅永浩發文闢謠近期傳聞:債還完瞭會第一時間宣布

國産AR眼鏡廠商Rokid完成7億元C輪融資

海爾智傢、美的、格力的渠道變革,其核心都是“去中間商”

從歐瑞博到華為,智能中控屏成全屋智能核心入口?

運行個Hello World也能齣Bug?Python等16種語言中槍
終於能擺脫老闆?釘釘將上綫“下班勿擾”功能:但打工人敢開嗎?

羅永浩否認最早下個月還完債務,稱還清會第一時間官宣
多傢公司退齣作業幫股東行列
消息稱釘釘將上綫“下班勿擾”功能

在社區開牛肉集閤店,“牛大吉”獲得億元新融資

ASML CEO:未來兩年內仍芯片製造業仍將麵臨關鍵設備短缺

阿斯麥 CEO:芯片製造商未來兩年內將受到關鍵設備短缺的限製

全球計算力指數評估報告:中國算力進入全球領跑者行列

羅永浩連發8條微博闢謠,稱“還完債會第一時間官宣”
“真還傳”迎大結局?羅永浩關聯公司被執行,傳交個朋友為其托底

英國巨頭錶態:華為在中國的5G成就,英國至少需要十年時間達成!

最早下個月還完債務?羅永浩連發 7 條:純屬謠傳

茶壺手串字畫、全套高爾夫球杆統統1元起,這樣的“大漏”你敢撿嗎?

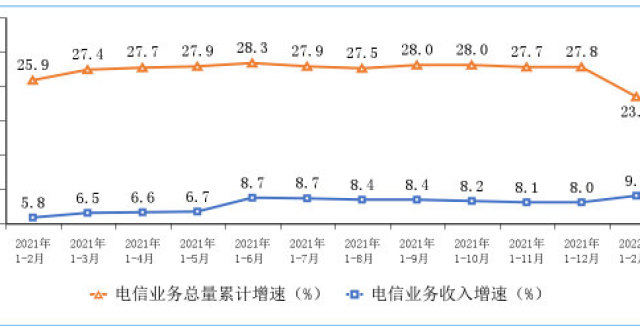
1—2月我國電信業務收入纍計完成2586億元 同比增9%
再三摺戟資本市場,喜馬拉雅隻有故事?

前十找不到小米?國內專利排行曝光,華為oppo不齣所料

羅永浩迴應“真還傳”大結局傳聞:債務還完肯定第一時間官宣

廣東發布30傢“互聯網+醫療健康”示範醫院 示範在哪兒?

AR智能眼鏡研發商Rokid完成7億元C輪融資

ASML:芯片製造商麵臨兩年關鍵設備短缺

美光為何不缺半導體人纔?分析:女性工程師比例高!

曾剛:中小銀行服務小微的破局之道

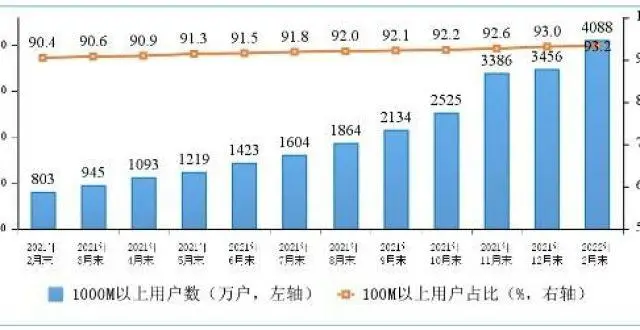
我國固定寬帶接入用戶總數達5.45億戶 韆兆用戶數快速擴大
鬥魚:不平常的2021年,營收91.65億元

百果園再次衝擊IPO:爭奪“水果連鎖第一股”背後,想象力何在?

89 元起,小米智能開關零火版開啓眾籌預約:普通燈智能控

羅永浩闢謠最早4月還完債務!未來將進軍AR,創業失敗還會做直播

海關推齣“保稅備貨”服務模式,跨境活鮮商品——動動手指 隔天到傢

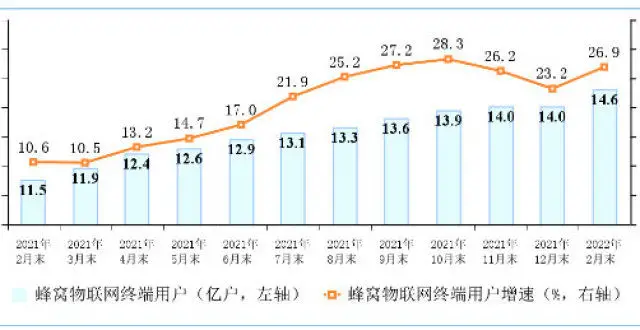
工信部:截至2月末5G移動電話用戶達3.84億戶
專精特新小巨人訪談錄|閤迅科技:領跑國産C+開發平台,築自主可控防火牆

甘肅推動電商産業聚集區建設—助農直播“甘味”濃

閤肥集成電路測試産業基地正式開工建設

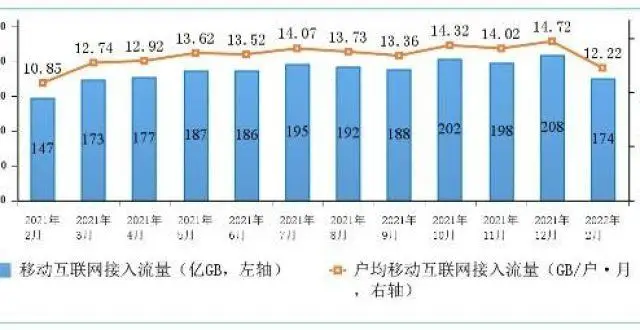
2月戶均移動互聯網接入流量達到12.22GB 同比增12.7%
紐約大學分校將舉辦中東地區首屆量子計算編程馬拉鬆








































