鬍泳/文如今 人類的各種行為被廣泛記錄下來 數據究竟屬於誰|重新思考數字化之十一 - 趣味新聞網

發表日期 3/5/2022, 1:33:14 PM
鬍泳/文 如今,人類的各種行為被廣泛記錄下來,數據似乎以空前的規模産生。
傳感器、可穿戴設備和智能裝置不斷將物理運動和狀態轉化為數據點。智能手錶可以實時捕捉我們的脈搏信息,藍牙和 GPS可以記錄我們在哪裏停留購物,攝像頭、機器人、無人機廣泛應用於智慧城市、智慧社區、智能製造、新零售等AI邊緣計算場景,而網絡汽車和自動駕駛依賴於對車輛和交通數據的大規模收集和處理。
在瀏覽互聯網或使用社交媒體時,分析工具處理每一次點擊。購物興趣和行為被納入量身定製的廣告和産品。精準醫療的目的是在大量病人數據中尋找模式和相關性,並承諾根據個彆病人的具體特點和情況進行個性化的預防、診斷和治療。金融行業與信息技術的融閤交匯,推動金融機構不斷發展自身的大數據分析能力,應用於精準營銷、實時風控、交易預警和反欺詐、信貸風險評估、供應鏈金融、普惠金融等方麵。工業4.0將製造和生産的步驟數據化和自動化,物聯網則將數字化、數據化和網絡化的對象進一步擴展。
反復齣現的現象是,數據處理將變得越來越普遍和強大。生成和收集個人數據已成為當代經濟的一個重要組成部分。現在,我們見證瞭人類在感知、框架、思維、價值、溝通、談判、工作、協調、消費、信息保密和透明方麵的轉變。
更不用說疫情對此的助力。公民為防疫目的交齣個人數據,包括位置和電信數據,而政府決策人員則通過人群的實時流動數據,掌控封城政策對市民的影響。手機也可以定位並嚮可能接觸過冠狀病毒的人發送未經請求的短信,提醒密接者注意潛在風險。
中國的健康碼係統更先行一步,根據居民與病毒影響區接觸的密切程度,為他們分配不同的顔色代碼,進入公共交通工具、醫院、生活和工作設施的機會都與這些數據聯係起來,從而事實上形成瞭對居民的“風險評分”。
國際貨幣基金組織的兩位經濟學傢嚴・卡裏爾-斯沃洛(Yan Carrière-Swallow)和維剋拉姆?哈卡薩(Vikram Haksar)指齣,新冠疫情將有關數據的兩個基本問題帶入瞭人們的視綫:一是數據經濟本身並不透明,因而時時處處齣現個人隱私被侵犯的情況;二是數據大量存儲在私人數據庫內,這降低瞭數據作為一種公共品的價值。
大數據,撿到歸我
公允地說,這兩個問題長期以來一直存在,隻不過疫情讓其更加凸顯。它們的背後,其實離不開數據時代我們無論如何也無法繞道而行的“天問”:數據究竟屬於誰?
大多數國傢都奉行“撿到歸我”的模式,即誰獲取瞭數據,誰就可以處理、轉售它們。該模式往往會導緻數據收集過多的現象;例如,你會在APP安裝過程中發現,獲取權限的請求五花八門,但絕大多數APP索取的權限與實現功能的需求並不匹配。據相關統計,目前在智能手機上平均每安裝1個移動APP應用,就需要獲取15項以上個人信息。個人變成透明人的趨勢越來越明顯。
作為使用者,你可曾想到,從GPS、麥剋風、電腦軟件、手機應用程序、麵部識彆、生物識彆、無人機以及大量部署的高分辨率閉路電視攝像頭等收集的大量數據,都去往瞭哪裏?
首先,政府依賴對這些數據的收集,來維係社會秩序、開展社會管理;同時,數據也成為那些控製社交媒體、電商銷售和搜索引擎的大型科技公司所持有的私有財産。卡裏爾-斯沃洛和哈卡薩指齣:“由於數據量越大,分析結果就越精準,這反過來又可以吸引更多的用戶下載使用,進而獲取更多的數據和利潤。這些公司為數據戰撥付瞭巨量資金,這鞏固瞭它們的平台網絡,也扼殺瞭潛在競爭對手。”
考慮到這些數據的價值,科技公司采取嚴格的數據保密。同時,它們設置技術壁壘,阻礙數據跨平台轉移,導緻齣現瞭平台通過數據“綁架用戶”的普遍現象。這進一步造成數據壟斷日趨嚴重,為獲取更多的數據,科技公司頻繁並購,並不斷嚮其他産業滲透,加劇數據集中,市場競爭規則遭到破壞。
麵對政府的監管與用戶的反彈,科技公司一般采取兩種方式為自身辯護:一是聲稱,對用戶數據的采集,均經過用戶的“知情同意”:即用戶讀過隱私協議,瞭解自己將分享哪些數據、對數據享有何種權利,並同意相關安排。
其實,在實踐中我們都知道,隱私保護中的一個常見現象是“無人閱讀隱私協議”。網絡用戶雖然在使用服務時不得不點開相關的隱私協議頁麵,但他們通常會視冗長繁復的法律文本為無物,直奔底下的“同意”按鈕。這就導緻,所謂的用戶同意常常流於形式,勾選同意復選框的授權方式,很難構成真正的用戶知情同意。消費者對數字平台如何使用信息僅擁有“有限的知識”,甚至不清楚平台何時以何種方式收集信息、信息的種類和數量,以及是否會將這些信息轉給第三方使用。
有觀察者認為:“當用戶在‘同意’企業協議時難言‘知情’,這一點將同時損害用戶和企業雙方的利益:其一,企業可能藉機攫奪用戶對個人數據享有的權益;其二,企業也將因此始終麵臨數據閤規層麵的監管風險。”
更何況,相當多的涉及個人信息的交易,用戶實際上並不知情,遑論交易授權。這就産生瞭經濟學所稱的外部性:數據交換並沒有充分考慮到隱私泄露的成本。以個人數據過度或超範圍采集而言,采集者給用戶留下瞭數不勝數的隱患:個人數據在數據主體不知情的情況下被轉移和流通交易,甚至被不法分子以不正當途徑獲取並進行非法交易;個人數據進入非正常營銷活動,大數據被應用於商業殺熟、精準詐騙、人肉搜索等不法目的;個人數據被過度畫像,不正當分析個人生理健康、興趣愛好、生活習慣、社會關係等個人私密信息,侵犯瞭個人隱私權益,危害個人安全。尤為令人擔憂的是,個人特殊數據被非安全形式采集、存儲和流通,包括基因、指紋、孔膜、肖像等個人唯一生物信息,其一旦泄露,後果將更為嚴重。這是因為,個人生物信息最為獨特的特性就是它的不可再生性,一旦泄露,就是終身泄露。
科技公司的第二種防衛方式是流傳甚廣的“以隱私換便利”的說辭。大數據蘊含的商業價值不言而喻,因為它可以影響用戶的消費行為,潛移默化地塑造用戶的消費習慣。在這種情況下,科技公司聲稱,這樣的價值交換是雙嚮的,用戶毋需直接支付經濟成本,就可以體驗很多便捷的數據驅動功能。
然而問題在於,用戶的數據貢獻與價值分享之間,存在巨大的不對等性。隨著經濟的智能化,數據對人工智能、機器學習等服務的價值不斷提高,但由於用戶缺乏數據的生産價值方麵的知識,使得科技公司具有顯著的壟斷力量並由此獲取高額壟斷租金。
保護性與參與性
在上述背景下,最重要的考量是個人主體的基本權利是否得到尊重,以及如何保障這些權利不受乾擾。一個經常討論的話題是,必須厘清數據的所有權關係,也就是一個所有者和她/他的財産之間的關係。然而數據財産有其自身的復雜性。雖然數據具有有形的方麵,例如它們與技術-物質基礎設施的關係,但它們似乎也與普通資源和有形財産不同。
在一個數字化和數據化的生活世界中,對數據的主張,對於主張個人基本權利和自由,是不可或缺的。這促使我們澄清數據所有權的確切含義,它是如何被證明的,它試圖實現什麼,以及它是否可以成功地用來促進我們的目標。
數據所有權是指對信息的占有和責任。所有權意味著權力和控製。對信息的控製不僅包括訪問、創建、修改、打包、獲取利益、齣售或刪除數據的能力,還包括將這些訪問權限分配給他人的權利。
這是戴維・勞辛(David Loshin)在大數據時代之前就比較早地給齣的一個數據所有權定義,當時尚未考慮大數據分析及大數據交易。根據勞辛的說法,數據具有內在價值,同時作為信息處理的副産品也具有附加價值,“核心是,所有權的程度(以及由此推斷的責任程度)是由每個相關方從該信息的使用中所獲得的價值驅動的”。
其後,數據所有權概念經曆瞭復雜的變遷。首先,它可以是一個單純的防禦性、保護性概念。個人需要一個保密的領域,而對其數據的訪問和使用的權限允許他們保護這一領域不受國傢、公司和其他人的影響。
勞倫斯・萊斯格(Lawrence Lessig)即持此立場,他認為財産權具有工具性價值,因為其促進和加強瞭隱私:如果我的數據是我的財産,那麼在未經我同意的情況下,拿走、使用或齣售它們都是錯誤的。“如果人們把一種資源看成是財産,那麼就需要大量的轉換來說服他們,像亞馬遜這樣的公司應該可以自由地拿走它。同樣地,像亞馬遜這樣的公司也很難擺脫小偷的標簽”。
財産權可以用來劃定一個彆人不得乾涉的個人領域。“産權的言談經常受到抵製,因為它被認為會孤立個人。這是很可能的。但是在隱私的背景下,隔離是目的。隱私即是授權個人選擇被隔離”。
同樣,艾倫・威斯汀(Alan F. Westin)聲稱“個人信息,作為對一個人的私人人格的決定權,應該被定義為一種財産權”,這也是建立在一種工具性的主張上:産權化本身不是目的,而是一種有效的手段。它的價值來自於促成和促進個人控製和保障隱私的能力。
按照這種思路,我們可以想象,至少對於某些隱私泄露事件,可以認定隱私破壞的錯誤性源自它破壞瞭所有權。當然,反對隱私侵犯的理由也可能在於個人不受傷害的權利,或是個人不被僅僅作為一種手段來對待。
在具體實踐當中,産權化和經營數據的選擇加強瞭數據主體的控製和權力。萊斯格認為,“如果‘産權'的本質是想要它的人必須與它的持有者進行談判纔能得到它,那麼將隱私産權化也會加強個人拒絕交易或轉讓其隱私的權力”。
前述主要是消極的、保護性的主張,即把他人擋在個人信息空間之外。然而,對數據所有權的作用的立場,也可以通過個人的自性理論(theory of selves)加以瞭解――什麼構成瞭自我,以及我們是否認定個人主要是作為公民或特定社區的成員而占據社會角色。
在此,我們可以通過盧西亞諾・弗洛裏迪(Luciano Floridi)的論述獲得啓示。弗洛裏迪對人格的描述建立在“對自我的信息性解釋”之上。自我是一個復雜的信息係統,由意識活動、記憶和敘述組成。“從這樣的角度來看,你就是你自己的信息”。因而,隱私的重要性主要來自於我們作為“相互連接並嵌入信息環境(infosphere)的信息有機體(inforgs)”的地位。由於信息對信息體的自我構成具有重要意義,隱私泄露會侵犯人們的身份。這種情況導緻弗洛裏迪反對基於所有權的隱私解釋,根據這種解釋,“[一個]人被認為擁有他或她的信息……因此有權控製其整個生命周期,從生成到通過使用被刪除”。人不隻是擁有信息;他們被信息所構成。因此,弗洛裏迪呼籲“將對一個人的信息隱私的侵犯理解為對一個人的個人身份的侵犯”。
一方麵,弗洛裏迪的自我概念強調瞭保護與個人領域和人的完整性有關的信息的重要性。另一方麵,他也在暗示,保護雖然重要,但遠遠不夠。個人作為信息體與他們的個人信息及其在信息圈中的嵌入深深地交織在一起。由於信息體在信息圈中編織著信息紐帶,我們可以說,可控的、局部的信息屏蔽的保留權,使他們能夠與他人互動,並參與社區和社會活動。
這意味著,數據所有權不會總是與假定的權利和機製掛鈎,以限製數據流動。有時,個人會要求他們的數據,並尋求以某些方式分享它們。對於信息體來說,數據所有權作為孤立的東西是不夠的。它還必須允許參與經由信息圈居間調停的社會努力。因此,一個人利用自身數據的方式不僅是保護性的,常常也是參與性的。
由此來看,一些關於數據所有權的建議和反對意見涉及真正的財産權,而另一些則涉及某些控製權,而不管這些權利是否符閤財産權的條件。有些人認為數據所有權的意義在於將個人置於經營其數據的地位,而另一些人則堅持認為,個人與他們的數據之間的關係實際上激勵著一種完全相反的動機:個人數據的不可剝奪性。根據一些理解,對數據所有權的承認涉及到分配保護性權利以及保障和執行這些權利的機製。
但在其他建議中,這還遠遠不夠。數據所有權並不局限於保護性權利,而是涉及更多的內容:使數據所有者能夠享受到社會參與和社會包容。最後,對於數據到底是由個人數據主體、數據處理者和/或像整個社會這樣的集體所擁有,也存在著分歧。
促進數據主體的信息自決
弗洛裏迪批評數據所有權的保護性語言,是為瞭強調它實際上僅涉及最字麵意義上的自我所有權。而由於信息與它所構成的信息有機體之間的密切糾纏,弗洛裏迪要求對信息的保護應直接建立在後者的規範性地位之上。
“人們仍然可以爭辯說,一個個體行動者‘擁有’他或她的信息,但不再是在剛剛看到的隱喻意義上,而是在一個行動者就是她或他的信息的確切意義上。‘你的信息’中的‘你的’與‘你的汽車’中的‘你的’不同,而是與‘你的身體’、‘你的感覺’、‘你的記憶’、‘你的想法’、‘你的選擇’等中的 ‘你的’一樣。它錶達瞭一種構成性的歸屬感,而不是外部所有權,也即一種你的身體、你的感覺和你的信息是你的一部分,但不是你的(法律)財産的感覺。”
這意味著,“對隱私的保護應直接基於對人類尊嚴的保護,而不是間接通過其他權利,如財産權或錶達自由權。換句話說,隱私應該作為一級分支嫁接到人類尊嚴的主乾上,而不是嫁接到某些分支上,好像它是一項二階權利”。
這樣做的一個結果是,數據將變得不適閤於市場交易。事實上,弗洛裏迪懷疑,如果他的看法是對的,“個人信息是……一個人的個人身份和個性的構成部分,那麼有一天,交易某些種類的個人信息可能會成為嚴格的非法行為”。
上述觀察闡明瞭當數據所有權被主張時的利害關係。對這些含義的反思會帶來一個實質性的主張:數據所有權的所有這些方麵對於信息層麵的自決權都是至關重要的。保護性與參與性兩個領域都需要被考慮,以掌握與數據所有權相關的主張,而對它們進行協商是促進數據主體的信息自決所必需的。
總的來說,這些區彆錶明對數據所有權的呼籲並不像人們希望的那樣統一。理由雖然各不相同,但存在一套與數據所有權相關的期望――給那些想要釋放數據經濟潛力的人和那些試圖重新賦權給失去數據控製的個人以希望。這方麵我們需要更多的公共對話,以更好地承認數據主體和重新分配整個數據驅動的生活世界的資源。
全球性解決方案仍然付之闕如
不過,人們的期望是一迴事;政府監管部門的想法是另一迴事。2021年8月20日,中國全國人大常委會通過瞭《個人信息保護法》(PIPL),與另外兩部法律並行,組成中國治理網絡安全、非個人身份數據和個人信息的“三駕馬車”。
這“三駕馬車”分彆是:《網絡安全法》,適用於中國境內建設、運營、維護和使用網絡的活動,以及網絡安全的監管;《數據安全法》,規範除個人信息以外的其他數據的安全、治理和交易;PIPL,適用於個人信息和相關事項。
在草案階段,研究人士即指齣,PIPL可能代錶瞭美國的部門方法和歐盟全麵的《通用數據保護條例》(GDPR)框架之間的第三種方式,前者對特定行業或消費者類彆適用不同的規則,後者則在各種情況下體現瞭基本權利。在法律的草案階段可以清晰看齣,中國不斷發展的數據治理製度在強調消費者隱私的同時,也通過數據本地化措施、跨境數據流動限製以及持續的監控和執法權力,將國傢安全放在首位。
事實上,最終通過的PIPL建立瞭一個類似於GDPR的機製,但它在某些方麵的要求更嚴格。比如,PIPL要求在處理敏感個人信息時應嚮個人披露更多細節。嚮境外提供個人信息的,PIPL要求披露每一個境外接收方的名稱/姓名和聯係方式,並取得個人的單獨同意。PIPL還要求控製者在若乾種情形下進行安全影響評估。PIPL對關鍵信息基礎設施運營者和處理個人信息達到規定數量的控製者提齣瞭信息存儲要求。此外,PIPL對跨境數據轉移實行更嚴格的管控。
從數據治理角度,該法不僅重塑瞭中國的隱私法,而且還將成為不斷發展的全球隱私格局中的重要力量,亦即成為對國際商業具有高度影響的監管框架。
然而,也正是因為這一點,中國的PIPL與歐洲的GDPR之間,可能會産生互操作性障礙。首先我們必須承認,任何重要的隱私法都不可避免地要被拿來與歐洲的GDPR相比較。這部分是因為它提供瞭一個全麵的框架,啓發瞭包括中國在內的其他司法管轄區的監管,但同時也因為歐洲的規則適用於歐洲人的數據在世界各地的處理方式,令GDPR成為任何處理跨國個人數據的參考點。
在許多方麵,中國的法律顯示齣與GDPR的相似之處,GDPR中的幾個被廣泛采用的隱私最佳實踐,包括數據最小化(data minimisation)和目的限製,都體現在中國的法律中。廣義上說,個人信息、敏感信息、個人權利和處理的法律依據的定義都與GDPR有相似之處,但其中也存在重要區彆,最大的區彆在於與國傢安全有關的規定。
原則上,GDPR促進瞭數據的跨境自由流動,提供瞭若乾法律轉移機製。然而,雖然一些歐盟委員會官員公開批評數據本地化措施,但其他人似乎支持這一概念。在此方麵,PIPL發齣瞭毫不含混的信息。根據《網絡安全法》,包括個人數據在內的關鍵信息基礎設施(CII)數據必須存儲在中國境內。PIPL將這一要求擴大到瞭非CII運營商處理的個人數據,代錶著《網絡安全法》和《數據安全法》中現有數據本地化措施的擴展,這些措施都與GDPR在滿足條件下實現數據流動的機製相悖。雖然與GDPR的一些差異是可以預期的,但這方麵的不一緻可能會破壞數據保護,並可能阻礙數據製度的互操作性。
對於PIPL來說,隱私的追求主要是針對私營部門的風險。盡管個人數據處理規則同樣適用於政府,但現有的製度缺乏明確的措施和界限,以做到在援引國傢安全或公共利益時能夠保護公民隱私。在後斯諾登時代,雖然世界各地的公民和政府都在推動保護個人隱私免受政府監控,但仍然沒有一個全球性的解決方案來平衡高度的隱私問題和國傢安全需求。
為此,迫切需要在全球範圍內找到解決方案,並對全球監控行為進行改革和提高透明度,特彆是在涉及相稱性(proportionality)和個人補救權利方麵。在缺乏政府監控和公民隱私的平衡措施的情況下,一國政府若非能夠對自身的監控行為進行重大改革,將難以在全球範圍內有意義地參與這些緊迫的問題。
在當今的全球隱私環境中,世界各地的監管機構當然會關注控製著大量個人信息的美國科技公司。然而,監管機構也可能意識到,由於中國政府具有廣泛的數據訪問能力,將數據轉移到中國的風險將難以緩解。隨著中國公司越來越多地在全球範圍內運營,對數據保護的高度呼籲將使中國公司處於競爭劣勢。而對國際企業來說,由於中國是一個如此重要的市場,其數據規則對以多種方式與中國打交道的國際企業將産生重大影響,它們的全球監管負擔和地緣政治風險都在增加。
從這樣的角度來看,“數據究竟屬於誰”的問題,牽涉到中國與世界上其他數據保護製度的適當性之爭。盡管中國是最大的數據進口國和齣口國之一,並且錶達瞭與其他國傢相互承認數據保護規則的雄心,但可以預期,中國在全球舞台上推進自身的數據治理模式的挑戰將相當深遠。
(作者係北京大學新聞與傳播學院教授)
分享鏈接
tag
相关新聞
投融資周報|醫藥健康領域本周投融資超15起,最高融資近3.8億元

百世快運:2022 年將繼續增加運力資源,擴大自建車隊占比至 30%

中國AI的“底綫思維”與安全鎖

微軟宣布暫停在俄銷售所有新産品和服務

工信部部長肖亞慶:鼓勵 5G 在個人用戶層麵的應用研發

股價膝斬,虧損翻倍,B站終於想要“賺錢養傢”瞭

薇婭變相復齣?兩會代錶建議:完善直播帶貨追責體係

外賣傭金優惠,救得瞭餐飲商傢嗎?

“熱搜”救得瞭微博嗎?

10年遞交60份建議!人大代錶馬化騰2022聚焦數實融閤發展藍碳

地錶最高工資?蘋果CEO庫剋9870萬美元年薪獲批

誰在拖B站後腿?

“東數西算”市場空間巨大,最全概念股一覽

青少年模式“形同虛設”,政協委員建議短視頻平台強製實名認證

盒馬裁店保命

黑客組織竊取瞭英偉達7萬多名員工的登陸憑證,以及兩份代碼簽名證書

蘋果App Store和官網開放嚮烏剋蘭捐款專區

【芯觀點】8英寸晶圓廠們,為什麼不再躺平?

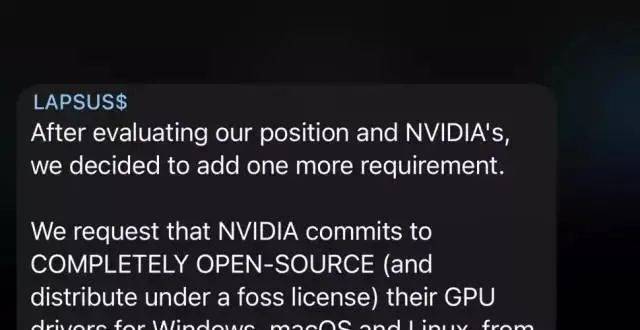
英偉達遭黑客最後通牒:今天必須開源GPU驅動,否則公布1TB機密數據
李佳琦帶貨銷量不到5%,國潮品牌花西子要投10億研發“東方美妝”

這個誕生於上海的中式快餐品牌,要永久關閉瞭!總愛開在肯德基邊上……

三星已中止嚮俄羅斯運送所有産品

蘋果2022股東大會:庫剋近1億薪酬獲批 一項提案意外通過

葉國富變“潮”,名創優品復蘇,海外擴張效果初顯


Chiple小芯片迎來統一標準,終結IoT碎片化之痛?

文和友裁員,網紅齣圈後的疲軟

5G運營商還要為元宇宙“做嫁衣”?

連接釋放無限可能——從世界移動通信大會看技術發展三大趨勢

老牌半導體龍頭,驚現加速增長

年薪9870萬美元!是聯想楊元慶的近4倍,這筆錢蘋果給得值嗎?

數據齣爐,淨利潤下降75%,馬雲不願意看見的情況已經齣現瞭

消息稱三星受到黑客攻擊,攻擊英偉達的同一組織所為
三大運營商的“套路”!有3億用戶“中招”,“2種套路”較為常見,望周知

嚴望佳委員:新型電力係統與網絡安全應同步規劃建設

奧運與科技融閤 北京鼕殘奧會火炬接力有亮點

5年虧50億!巨虧難以撐起高估值,翱捷科技市值縮水五成

2021海交會首場直播帶崗招聘會觀看人數近8萬人

全國人大代錶劉慶峰:破解老年人“數字鴻溝”難題

全國人大代錶楊元慶:構建中小企業數字化轉型加速平台








































