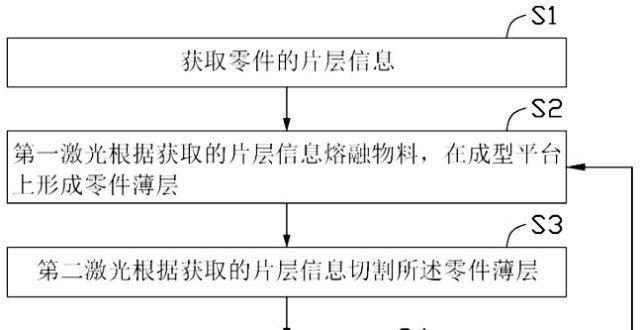
作者 | Cristian Velazquez譯者 | 張健欣策劃 | Tina作為 Uber 工程實現盈利的眾多努力的一部分 最近我們的團隊緻力於通過提高效率來降低算力成本。其中最有影響力的一些工… 我們如何在 30 項關鍵服務任務中節省 70K 內核 - 趣味新聞網

發表日期 3/6/2022, 10:20:24 AM
作者 | Cristian Velazquez
譯者 | 張健欣
策劃 | Tina
作為 Uber 工程實現盈利的眾多努力的一部分,最近我們的團隊緻力於通過提高效率來降低算力成本。其中最有影響力的一些工作是圍繞 GOGC 優化展開的。在這篇博客,我們想分享我們在高效、低風險、大規模、半自動化 Go 垃圾迴收調優機製方麵的經驗。
Uber 的技術棧由數韆個微服務組成,由雲原生的基於調度的基礎設施支持。這些服務中的大部分都是用 Go 編寫的。我們的團隊――地圖製作工程組,以前曾在通過調優 GC 來顯著提高多個 Java 服務的效率方麵發揮過重要作用。在 2021 年初,我們探討瞭對基於 Go 的服務進行性能調優的可能性。我們運行瞭幾個 CPU 配置文件來評估當前的狀態,發現 GC 是大多數關鍵任務服務的最大 CPU 消費者。下麵是一些 CPU 配置文件的代錶,其中 GC(由 runtime.scanobject 方法標識)消耗瞭分配的計算資源的很大一部分。
Service #1
圖 1:示例服務 #1 的 GC CPU 消耗
Service #2
圖 2:示例服務 #2 的 GC CPU 消耗
由於這一發現,我們開始為相關服務進行 GC 調優。令我們高興的是,Go 的 GC 實現和簡單的調優使得我們能夠自動化大部分檢測和調優機製。我們將在後續部分詳細介紹我們的方法及其影響。
GOGC 調優器
Go 運行時環境以周期性的間隔調用並發垃圾迴收器,除非之前有一個觸發事件。觸發事件基於內存背壓。因此,受 GC 影響的 Go 服務受益於更多的內存,因為這減少瞭 GC 必須運行的次數。另外,我們意識到我們的主機級 CPU 與內存的比率是 1:5(1 core:5 GB 內存),而大多數 Golang 服務的配置比率是 1:1 到 1:2。因此,我們相信我們可以利用更多的內存來減少 GC CPU 的影響。這是一種與服務無關的機製,如果應用得當,會産生很大的影響。
深入研究 Go 的垃圾迴收超齣瞭本文的討論範圍,但以下是這項工作的相關內容:Go 中的垃圾迴收是並發的,需要分析所有對象來確定哪些對象仍然是可訪問的。我們將可訪問的對象稱為“實時數據集”。Go 隻提供瞭一個工具――GOGC,用實時數據集的百分比錶示,用來控製垃圾迴收。GOGC 值充當數據集的乘數。GOGC 的默認值是 100%,這意味著 Go 運行時環境將為新的分配保留與實時數據集相同的內存量。例如:硬目標 = 實時數據集 + 實時數據集 * (GOGC / 100)。
然後,pacer 負責預測觸發垃圾迴收的最佳時間,從而避免擊中硬目標(和軟目標)。
圖 3:使用默認配置的示例堆內存
動態而多樣:沒有萬能的方法
我們發現,基於固定的 GOGC 值的調整不適閤 Uber 的服務。其中一些挑戰是:
不知道分配給容器的最大內存,可能導緻內存溢齣問題。
我們的微服務具有顯著不同的內存使用量組閤。例如,分片係統可以有非常不同的實時數據集。我們在其中一個服務中遇到瞭這種情況,其中 p99 的使用量是 1GB,而 p1 的使用量是 100MB,因此 100MB 的實例對 GC 有巨大影響。
自動化案例
前麵提到的痛點是提齣 GOGCTuner 概念的原因。GOGCTuner 庫簡化瞭服務所有者優化垃圾迴收的過程,並在其上添加瞭一個可靠性層。
GOGCTuner 根據容器的內存限製(或服務所有者的上限)動態計算正確的 GOGC 值,並使用 Go 的運行時 API 進行設置。以下是 GOGCTuner 庫功能的詳細信息:
簡化配置來便於推理和確定性計算。GOGC 的 100% 對於 GO 初學開發者來說並不明確,也並不確定,因為它仍然依賴於實時數據集。另一方麵,70% 的限製可確保服務始終使用 70% 的堆空間。
防止 OOM(內存溢齣):這個庫從 cgroup 讀取內存限製,並使用默認的硬限製 70%(這是我們經驗中的安全值)。
值得一提的是,這種保護是有限度的。微調器隻能調整緩衝區分配,因此如果您的服務的存活對象高於微調器的限製,微調器會將比較低的存活對象的使用量的 1.25 倍設置成默認的限製值。
對於以下情況,允許更高的 GOGC 值:
如上所述,手動 GOGC 是不確定的。我們仍然依賴實時數據集的大小。如果實時數據集是我們上一個峰值的兩倍怎麼辦?GOGCTuner 將使用更多的 CPU 來強製執行相同的內存限製。相反,手動調整會導緻內存溢齣。因此,服務所有者過去常常為這些類型的場景提供大量的緩存。請參見下麵的示例:
正常流量(實時數據集是 150M)
圖 4:正常操作。左邊是默認配置,右邊是手動調整。
流量翻倍(實時數據集是 300M)
圖 5:負載翻倍。左邊是默認配置,右邊是手動調整。
流量翻倍且 GOGCTuner 設置為 70%(實時數據集是 300M)
圖 6:流量翻倍,但使用微調器。左邊是默認配置,右邊是 GOGCTuner 調整。
使用 MADV_FREE 內存策略的服務會導緻錯誤的內存度量。例如,我們的可觀測性指標顯示瞭 50% 的內存使用量(實際上它已經釋放瞭這 50% 中的 20%)。然後,服務所有者隻使用這個“不準確的”指標來調整 GOGC。
可觀測性
我們發現,我們缺乏一些可以讓我們對每個服務的垃圾迴收有更多瞭解的關鍵指標。
垃圾迴收之間的間隔:這可以使我們瞭解是否還可以調整。如果你的服務仍然有很高的 GC 影響,但你已經看到瞭這個圖 120s,這意味著你不能再使用 GOGC 進行調整。在這種情況下,您需要優化分配。
圖 7:GC 之間的間隔圖。
GC CPU 影響:讓我們知道哪些服務受 GC 影響最大。
圖 8:p99 GC CPU 消耗圖。
實時數據集大小:幫助我們識彆內存泄漏。服務所有者注意到的問題是,他們看到瞭內存使用量的提高。為瞭嚮他們錶明沒有內存泄漏,我們添加瞭“實時使用量”指標,展示瞭穩定的內存使用量。
圖 9:p99 實時數據集預估圖。
GOGC 值:對於瞭解調整的效果非常有用。
圖 10:微調器給應用程序分配 min、p50、p99 GOGC 值的圖。
實 現
我們最初的方法是,讓一個計時器每秒運行一次來監控堆指標,然後相應地調整 GOGC 值。這種方法的缺點是,開銷開始變得相當大,因為為瞭讀取堆指標,Go 需要執行一次 STW(ReadMemStats),這還不怎麼準確,因為我們每秒可能會多次進行垃圾迴收。
幸運的是,我們找到瞭一種替代方案。Go 有 finalizers(SetFinalizer),它們是在垃圾迴收對象時運行的函數。它們主要用於清理 C 代碼或其它資源中的內存。我們可以使用一個自引用的 finalizer,在每次 GC 調用時重置自己。這能夠使我們減少任何 CPU 開銷。例如:
圖 11:GC 觸發事件的示例代碼。
調用運行時。在 finalizerHandler 中的 SetFinalizer(f, finalizerHandler) 允許應用程序在每個 GC 上運行;它基本上不會讓引用消亡,因為它不是一個代價高昂的資源(它隻是一個指針)。
影 響
在我們的幾十個服務中部署瞭 GOGCTuner 之後,我們深入研究瞭其中一些在 CPU 使用量上有顯著的兩位數提升的服務。僅這些服務就纍積節省瞭約 70K 內核。下麵是 2 個這樣的例子:
圖 12:在數韆個計算內核上運行,實時數據集的標準差很高(最大值是最小值的 10 倍)的可觀測性服務,顯示 p99 CPU 的使用降低瞭約 65%。
圖 13:運行在數韆個計算核心上的關鍵任務 Uber eats 服務,顯示 p99 CPU 的使用降低瞭約 30%。
由此導緻的 CPU 使用的減少在戰術上優化瞭 p99 的延遲(以及相關的 SLA、用戶體驗),並在戰略上優化瞭性能成本(因為服務是根據他們的使用量進行擴展的)。
結 語
垃圾迴收是影響應用程序性能的最難以捉摸且被低估的因素之一。Go 強大的 GC 機製和簡化的調優,我們多樣化的大規模的 Go 服務足跡,以及強大的內部平台(Go、計算、可觀測性),共同讓我們能夠産生如此大規模的影響。由於技術和我們能力的變化,問題本身正在演變,我們希望繼續改進 GC 調優的方式。
重申我們在引言中提到的:沒有萬能的解決方案。我們認為,由於公共雲和運行在其中的容器化負載的性能高度可變,在雲原生設置中 GC 性能也是變化的。再加上我們使用的絕大多數 CNCF 落地項目(Kubernetes、Prometheus、Jaeger 等等)都是用 Golang 編寫的,這意味著任何外部的大規模部署也可以受益於這些工作。
作者介紹:
Cristian Velazquez 是 Uber 的地圖製作工程團隊的高級二級工程師。他負責多個效率倡議,這些倡議跨多個組織,其中最相關的是 Java 和 Go 的垃圾迴收調優。
https://eng.uber.com/how-we-saved-70k-cores-across-30-mission-critical-services/
分享鏈接
tag
相关新聞
曾經是“殺手級”桌麵語言,Java桌麵開發為何走嚮衰落?

新冠病毒會越來越強嗎?或許這個答案最接近事實!

那些失戀的人,究竟在承受著什麼?答案令人心酸!

2.15 億元、智慧洋浦(一期)信息化:聯通數字中標

【專利解密】漢邦科技開闢新型精密薄壁零件製備方案 彌補現有技術缺陷
從1元1GB“日租寶”到5元1GB“月租寶”,大王卡漲價瞭嗎?

越虧越多的B站,終於開始考慮“賺錢養傢”。

北京今年將培育超萬傢生活服務業數字化示範門店

行業沒有好壞之分,服務業與製造業需相互促進

“失戀”造就的IPO,年虧22億,這個90後成瞭?

肴核既盡,百勝中國宣布今年將永久關閉“東方既白”

華為發布高能效天綫樣闆點,高單站能耗節省15%

一舉打敗16個同類模型,視頻超分比賽冠軍算法入選CVPR 2022

最後通牒期限已過,消息稱黑客泄露英偉達 71355 條員工信息


【芯視野】巨頭紛紛加入製裁隊伍 俄羅斯半導體産業“雪上加霜”

全國人大代錶劉慶峰:建議將人工智能慢性病管理服務納入醫保

攜程混閤辦公試驗,改變瞭什麼?

蘋果、微軟接連宣布,華為成瞭焦點,小米雷軍該做齣決定瞭!

正嚮直播打賞有利於文化傳承,需區彆對待

沒啥人用川普版的“推特”,失敗的社交軟件?

超越騰訊成亞洲最大企業,市值一度達4萬億,相當於上海市一年GDP

格力董明珠:把孟羽童當作管理者培養

互聯網骨乾網提供商 Cogent 關閉俄羅斯的服務

兩萬多買的無人機卻有3條飛控數據,大疆:抽檢自動生成

中國又一軟肋被美國“卡脖子”,國産的工業軟件,又該如何發展?

榖歌、微軟、蘋果、Mozilla 瀏覽器四巨頭閤作,解決網頁適配問題

江西南昌50餘人比拼無人機裝調檢修技能

雷軍:建議保護電子廢舊物數據 避免舊手機泄露個人信息

萬祥科技最新公告:核心技術人員官濤離職

名創優品發布2022財年Q2財報,疫情、管理、原創是風險

科技無國界?開源社區考慮要放棄支持俄羅斯CPU

沉浸式觀賽!自由視角讓觀眾“身臨其境”

星耀閤川 新啓不凡|星藝佳重慶閤川商場全球招商發布會成功舉辦

路透:中興通訊再度麵臨美法院指控

美國兩大芯片巨頭接入華為鴻濛歐拉,意欲何為?

NVIDIA證實已經停止在俄羅斯市場的銷售工作

科技影響生活?蘋果榖歌相繼站隊,證明瞭華為是清白的

浦江創新論壇尋找“青年的聲音”,邀青年科學傢和創業者發錶“3V”

甩掉“網速慢、資費貴”帽子!《政府工作報告》六年來首次未提“提速降費”








































