作者|Aria Beingessner翻譯|平川本文標題裏的觀點很“刺激” 它來自國外一位 Swift 和 Rust 專傢 Aria Beingessner “C不再是一種編程語言” - 趣味新聞網

發表日期 3/28/2022, 2:54:42 PM
作者|Aria Beingessner
翻譯|平川
本文標題裏的觀點很“刺激”,它來自國外一位 Swift 和 Rust 專傢 Aria Beingessner,他近日撰寫瞭一篇文章《C 不再是一種編程語言》,在技術社區引起瞭熱議。
Beingessner 和他的朋友 Phantomderp 發現彼此在 C 語言的某個方麵都有著高度一緻的意見――對 C ABI 感到憤怒,並試圖修復它們。盡管他們各自憤怒的原因不盡相同,但本文作者想要錶達的是: “C 被提升到瞭一個具備聲望和權威的角色,它的統治是如此地絕對和永恒,以至於它完全扭麯瞭我們之間的對話方式。” “Rust 和 Swift 不能簡單地‘說’自己的母語或舒適的語言――它們必須怪異地模擬 C 的皮膚,並把自己包裹其中,使肉體以同樣的方式起伏。”
比喻雖尖銳,依據卻不無道理。幾乎任何程序要做任何有用或有趣的事情,它都必須在操作係統上運行。這意味著它必須與那個操作係統交互――而很多操作係統都是用 C 編寫的。因此,該語言必須與 C 代碼交互,這意味著它必須調用 C API。這是通過外部功能接口(FFI)完成的。換句話說,即使你從未用 C 編寫任何代碼,你也必須處理 C 變量、匹配 C 數據結構和布局、通過名稱和符號鏈接到 C 函數。這不僅適用於任何語言與操作係統的交互,也適用於從一種語言調用另一種語言。
雖然很多人都錶示自己喜歡 C,但對文章的內容也是錶達瞭認可和贊同。
更精確地說,這篇文章的核心並不是“C 不再是編程語言”,而是“C 不僅僅是一種編程語言”。InfoQ 對原文進行瞭翻譯,以饗讀者。以下內容節選自原文:
C 是編程通用語言,我們都必須學 C,因此 C 不再隻是一種編程語言,它成瞭每一種通用編程語言都需要遵守的協議。
本文僅探討“C 由實現定義導緻的難以捉摸的混亂”,這個讓所有人都不得不使用的協議已經變成瞭一個更大的噩夢。
外部函數接口
首先,讓我們從技術的角度看看。你完成瞭新語言 Bappyscript 的設計,它對 Bappy Paws/Hooves/Fins 提供瞭一流的支持。這是一門神奇的語言,它將徹底改變人們的編程方式!
但現在,你需要用它做一些有用的事情,比如,接受用戶的輸入,或者輸齣結果,或者任何可見的東西。如果你希望用你的語言編寫的程序成為優秀的公民,可以在主要的操作係統上很好地運行,那麼你就需要與操作係統接口進行交互。我聽說,Linux 上的任何東西都“隻是一個文件”,所以讓我們在 Linux 上打開一個文件。
對不起,什麼?這是 Bappyscript,不是 C。那 Linux 的 Bappyscript 接口在哪裏?
你說 Linux 沒有 Bappyscript 接口是什麼意思!?好吧,這是一種全新的語言,但你會添加一個,對吧?這時候你會想,我們好像必須使用他們給的東西。
我們將需要某種接口,使我們的語言能夠調用外部函數。外部函數接口,是的,FFI......然後你發現,什麼,Rust,你也有 C 的 FFI?Swift 你也有嗎?甚至連 Python 也有?!
為瞭與主要的操作係統對話,每種語言都必須學會說 C 語言。然後,當它們需要相互對話時,也就都說起瞭 C 語言。
現在,C 語言成瞭編程通用語言。它不再僅僅是一種編程語言,還成瞭一種協議。
與 C 交互涉及哪些方麵?
很明顯,幾乎每種語言都必須學會說 C 語言。那麼,“說 C 語言”是什麼意思?這是說要以 C 語言頭文件的方式描述接口的類型和函數,並以某種方式做一些事情:
匹配這些類型的布局;
用鏈接器做一些事情,將函數的符號解析為指針;
用適當的 ABI 來調用這些函數(比如把參數放在正確的寄存器中)。
然而這裏有兩個問題:
你不能真的編寫一個 C 解析器;
C 並沒有一個 ABI,甚至是定義好的類型布局。
你不能真的解析一個 C 頭文件
真的,解析 C 語言基本上是不可能的。
“但是,等等!有很多工具可以讀取 C 語言的頭文件,比如 rust-bindgen!”
但還是不行:
bindgen 使用 libclang 來解析 C 和 C++ 頭文件。要修改 bindgen 搜索 libclang 的方式,請參閱 clang-sys 文檔。關於 bindgen 如何使用 libclang 的更多細節,請參閱 bindgen 用戶指南。
任何花瞭大量時間嘗試從語法上分析 C(++) 頭文件的人,很快就會說“啊,去他的”,並轉而用一個 C(++) 編譯器來做這件事。請記住,僅僅從語法上分析 C 頭文件是沒有意義的:你還需要解析 #includes、typedefs 和 macros 的。因此,現在你需要實現平台所有的頭文件解析邏輯,並以某種方式找到與你所關注的環境相對應的 DEFINED 內容。
就拿 Swift 這個極端的例子來說吧。在 C 語言互操作和資源方麵,它基本上擁有一切優勢。
該語言是由蘋果公司開發的,它有效地取代瞭 Objective-C,成為在蘋果平台上定義和使用係統 API 的主語言。我認為,在這個過程中,它在 ABI 穩定性和設計方麵比其他任何語言都更進一步。
它也是我見過的對 FFI 支持最好的語言之一。它可以本地導入 (Objective-)C(++) 頭文件,並生成一個漂亮的原生 Swift 接口,相關類型會自動“橋接”到 Swift 中對等的類型(通常是透明的,因為這些類型的 ABI 相同)。
Swift 的開發者同時也是蘋果公司 Clang 和 LLVM 項目的構建者和維護人。他們都是 C 語言及其衍生物方麵的世界級專傢。Doug Gregor 就是其中之一,以下是他對 C FFI 的看法:
看吧,即便是 Swift 也不願意做這種事。(另外可以參見 Jordan Rose 和 John McCall 在 llvm 上的 PPT 去瞭解“Swift 為何采用這種方式”)。
那麼,如果你無論如何也不想使用 C 編譯器在編譯時分析並解析頭文件,那麼你要怎麼做?你就要“手工翻譯”瞭!int64_t?還是說寫i64.long?......
C 實際上並沒有 ABI
好吧,這沒什麼可大驚小怪的:齣於“可移植性”考慮,C 語言中的整數類型被設計成大小不固定的。我們可以把賭注押在有點怪異的 CHAR_BIT 上,但我們還是無法知道long的大小和對齊方式。
”但是等等!每個平台都有標準化的調用約定和 ABI!“
的確是有,而且它們通常定義瞭 C 語言中關鍵原語的布局!(而且,其中一些不僅僅定義瞭 C 類型的調用約定,參見 AMD64 SysV。)
但這裏有一個棘手的問題:其架構中並沒有定義 ABI。操作係統也沒有。我們必須針對特定的目標三元組(target triple)做工作,比如“x86_64-pc-windows-gnu”(不要與“x86_64-pc-windows-msvc”弄混瞭)。
好吧,會有多少個這樣的目標三元組呢?
還有:
還有:
這樣的目標三元組總共有176個。我原本打算都列齣來,以增強視覺衝擊,但實在是太多瞭。
ABI 實在是太多瞭。而且,我們還沒有涉及到所有不同的調用約定,比如 stdcall vs fastcall 或者 aapcs vs aapcs-vfp!
至少,所有這些 ABI 和調用約定之類的東西肯定要以機器可讀的格式提供給大傢使用:冗長的 PDF 文件。
好吧,至少對於特定的目標三原組,主要的 C 語言編譯器在 ABI 上達成瞭一緻!當然,也有一些奇怪的 C 語言編譯器,如 clang 和 gcc-。
這是我在 x64 Ubuntu 20.04 上運行 FFI abi-checker 的結果。這是一個相當重要的、錶現良好的平台。這裏測試的是一些非常令人厭煩的情況,即一些整型參數在兩個由 clang 和 gcc 編譯的靜態庫之間按值傳遞……而且失敗瞭!
甚至是 x64 linux 上的__int128ABI,clang 和 gcc 也未能達成一緻。該類型是一個 gcc 擴展,但 AMD64 SysV ABI 在一個不錯的 PDF 文件裏做瞭明確定義和說明。
我寫這個東西是為瞭檢查 rustc 中的錯誤,我並沒有指望發現,這兩個主要的 C 編譯器在最重要同時人們也最熟悉的 ABI 上存在不一緻!
ABI 就是謊言。
試著把 C 馴化
因此,對 C 語言頭文件做語義解析是一個可怕的噩夢,隻能由那個平台的 C 編譯器來完成,即使你讓 C 編譯器告訴你類型以及如何理解注釋,但實際上,你仍然無法知道所有東西的大小 / 對齊方式 / 調用約定。
如何與那堆東西進行互操作呢?
你的第一個選項是完全投降,將你的語言與 C 語言進行靈魂綁定,可以采用以下任何一種方式:
用 C(++) 編寫編譯器 / 運行時,所以它無論如何都能說 C 語言。
讓你的“codegen”直接生成 C(++),這樣用戶就需要一個 C 編譯器。
基於一個成熟的主流 C 編譯器(gcc 或 clang)構建自己的編譯器。
但也僅限於此,因為除非你的語言真的暴露瞭unsigned long long,否則你就會繼承 C 的可移植性混亂。
於是,我們來到瞭第二個選項:撒謊、欺騙和偷竊。
如果這一切是一場躲不開的災難,那麼還不如開始在自己的語言中手工翻譯類型和接口定義。這基本上就是我們在 Rust 中每天都在做的事情。是的,人們使用 rust-bindgen 之類的工具來自動化這個過程,但很多時候,還是需要檢查或手工調整那些定義,生命短暫,實在無法讓經過某人奇怪定製的 C 構建係統可移植。
嘿,Rust,在 x64 linux 上intmax_t是什麼?
嘿,Nim,在 x64 linux 上long long是什麼?
很多代碼已經從各個環節中剔除瞭 C,並且已經開始對核心類型的定義進行硬編碼。畢竟,它們顯然隻是平台 ABI 的一部分!它們要做什麼?改變intmax_t的大小嗎!?這顯然是一個破壞 ABI 的修改。
哦,對瞭,phantomderp 正在研究的那個東西又是什麼?
我們談下為什麼不能修改intmax_t,因為如果我們從 long long(64 位整數)改為 __int128_t(128 位整數),某些二進製文件就會無所適從,使用錯誤的調用約定 / 返迴約定。但是,有沒有一種方法――如果代碼選用瞭――我們可以在新的應用程序中升級函數調用,而讓老的應用程序保持原樣?讓我們編寫一些代碼,測試一下透明彆名可以為 ABI 帶來什麼幫助。
是的,他們的文章真的寫得很好,解決瞭一些非常重要的實際問題,但是...... 編程語言如何處理這種變化?如何指定與哪個版本的intmax_t互操作?如果有一些 C 語言頭文件涉及到瞭intmax_t,它使用哪個定義?
我們在討論 ABI 不同的平台時使用的主要機製是目標三元組。你知道什麼是目標三元組嗎?x86_64-unknown-linux-gnu。你知道都包括什麼嗎?基本上涵蓋瞭過去 20 年裏所有主要的桌麵 / 服務器 Linux 發行版。錶麵上,你可以針對某個目標進行編譯,並得到一個在所有這些平台上都能“正常工作”的二進製文件。但是,情況可能並非如此,比如有些程序在編譯時會默認intmax_t比int64_t大。
任何試圖做齣這種改變的平台是不是都會成為一個新的目標三元組?x86_64-unknown-linux-gnu2?如果任何針對x86_64-unknown-linux-gnu編譯的東西都可以在上麵運行,這還不夠嗎?
修改簽名而又不破壞 ABI
”那又怎樣,難道 C 語言就永遠不會再改進瞭嗎?“
說不是也是,因為它糟糕的設計。
老實說,進行 ABI 兼容的修改可謂是一種藝術形式。這項工作的一部分是準備。如果你準備好瞭,做不破壞 ABI 的修改就會簡單很多。
正如 phantomderp 的文章所指齣的那樣,像 glibc(g是x86_64-unknown-linux-gnu中的gnu)早就意識到瞭這一點,並使用符號版本化這樣的機製來更新簽名和 API,同時為任何針對舊版本的編譯保留舊版本。
因此,如果有個方法int32_t my_rad_symbol(int32_t),你告訴編譯器將其導齣為my_rad_symbol_v1,那麼任何針對你所提供的頭文件進行編譯的人,都會在代碼中寫上my_rad_symbol,但會鏈接到my_rad_symbol_v1。
然後,當你確定實際應該使用int64_t時,可以把int64_t my_rad_symbol(int64_t)當作my_rad_symbol_v2,但仍然保留舊的定義my_rad_symbol_v1。任何人在針對你的頭文件進行編譯時,如果是針對新版本就使用符號v2,而針對舊版本則繼續使用v1!
但仍然有一個兼容性問題:任何針對新的頭文件所做的編譯都不能與舊版本的庫進行鏈接!庫的 v1 版本根本沒有 v2 符號。所以,如果你想要熱門的新功能,就需要接受與舊有係統不兼容的事實。
不過,這並不是什麼大問題,隻是會讓平台供應商感到難過,因為沒有人能夠立即使用他們花瞭這麼多時間做齣來的東西。你推齣瞭一個閃亮的新特性,卻要放在手裏等數年的時間,等到大傢認為它變得足夠普及 / 成熟,願意依賴它並打破對舊平台的支持(或者願意為它實現動態檢查和迴退)。
如果你想讓人們立即升級,那麼就是嚮前兼容的問題瞭。這就需要讓舊版本能夠適應它們完全沒有概念的新特性。
修改類型而不破壞 ABI
好瞭,除瞭修改函數的簽名,我們還可以修改什麼?我們可以修改類型布局嗎?
可以!但也不可以!這取決於你暴露類型的方式。
C 語言真正奇妙的其中一個功能是,它讓你可以區分布局已知的類型和布局未知的類型。如果你隻在 C 語言的頭文件中前嚮聲明一個類型,那麼任何與該類型交互的用戶代碼都無法知道該類型的布局,而必須一直通過指針不透明地對它做處理。
所以你可以開發一個像MyRadType*make_val()和use_val(MyRadType)這樣的 API,然後利用同樣的符號版本化技巧來暴露make_val_v1和 use_val_v1,任何時候你想修改這個布局,都要在與該類型交互的所有東西上修改版本。同樣地,你得保留MyRadTypeV1、MyRadTypeV2和一些類型定義,以確保人們使用“正確”的類型。
很好,我們可以改變不同版本之間的類型布局!對嗎?嗯,大多數時候是這樣。
如果有多個東西基於你的庫構建,它們在類型不透明的情況下相互調用,就會齣現糟糕的情況:
lib1:開發一個 API,使用類型MyRadType*調用use_val;
lib2:調用make_val,並將結果傳給 lib1。
如果 lib1 和 lib2 是基於庫的不同版本進行編譯的,那麼make_val_v1就會被傳遞給use_val_v2!這時,你有兩個選擇來處理這個問題:
禁止這樣做,警告那些這樣做的人,令人傷心。
以一種嚮前兼容的方式設計MyRadType,這樣混用就沒問題瞭。
實現嚮前兼容常用的技巧有:
保留未使用的字段供未來版本使用。
MyRadType 的所有版本都有一個共同的前綴,讓你可以“檢查”所使用的版本。
有大小自適應的字段,這樣舊版本可以“跳過”新增部分。
案例分析:MINIDUMP_HANDLE_DATA
微軟確實是嚮前兼容的大師,他們甚至讓他們真正關心的東西在不同的架構之間保持布局兼容。我最近遇到的一個例子是Minidumpapiset.h中的 MINIDUMP_HANDLE_DATA_STREAM。
這個 API 描述瞭一個版本化的值列錶。該列錶以這種類型開始:
其中:
SizeOfHeader是 MINIDUMP_HANDLE_DATA_STREAM 本身的大小。如果需要在末尾添加更多的字段,那也沒關係,因為舊版本可以使用這個值來檢測頭的“版本”,並跳過任何它們不識彆的字段。
SizeOfDescriptor是數組中每個元素的大小。這也是為瞭讓你知道元素是什麼“版本”,你可以跳過不知道的字段。
NumberOfDescriptors是數組長度。
Reserved是一個保留字段(Minidumpapiset.h非常嚴謹,從不使用任何填充字節,因為填充字節的值未定,而且是一種序列化的二進製文件格式。我希望他們添加這個字段是為瞭使結構的大小是 8 的倍數,這樣就不會有數組元素是否需要在頭之後填充的問題瞭。哇,這纔是認真對待兼容性!)
事實上,微軟使用這種版本化方案是有原因的,他們定義瞭兩個版本的數組元素:
關於這些結構的實際細節,有幾個比較有趣的地方:
對它的修改隻是在末尾添加字段;
“最後一個”有類型定義;
保留一些 Maybe Padding(RVA 是 ULONG32 類型)。
在嚮前兼容性方麵,微軟絕對是一頭堅不可摧的巨獸。他們對填充如此謹慎,甚至在 32 位和 64 位之間采用瞭相同的布局!(實際上,這非常重要,因為你希望一個架構的小型轉儲文件處理器能夠處理每個架構的小型轉儲文件。)
好吧,至少它真的很健壯,如果你按照它的規則來,通過引用進行操作,並使用 size 字段。
但至少可以玩下去。隻是在某些時候,你不得不說“你的用法不對”。微軟可能不會這麼說,他們隻會做一些可怕的事。
案例分析:jmp_buf
我對這種情況不是很熟悉,但在研究 glibc 曆史上的破壞性修改時,我在 lwn 上看到瞭這篇很棒的文章:glibc s390 ABI 的破壞性修改。我認為這篇文章比較準確。
事實證明,glibc 曾經破壞過類型的 ABI,至少在 s390 上是這樣。根據這篇文章的描述,它造成瞭混亂。
特彆地,他們改變瞭setjmp/longjmp使用的狀態保存類型(即jmp_buf)的布局。看吧,他們並不是十足的傻瓜。他們知道這是一個破壞 ABI 的修改,所以他們負責任地做瞭符號版本化。
但是,jmp_buf並不是一個不透明類型。有些東西內聯地存儲瞭這個類型的實例,比如 Perl 的運行時。不用說,這個相比之下不是很容易理解的類型已經滲透到許多二進製文件中去瞭,最終的結論是,Debian 的所有東西都需要重新編譯。
這篇文章甚至討論瞭對 libc 進行版本升級以應對這種情況的可能性:
在像 Debian 這樣的混閤 ABI 環境中,SO 名稱的改變(SO name bump)會導緻兩個 libc 被加載並競爭相同的符號命名空間,而解析(以及 ABI 選擇)由 ELF 插值和作用域規則決定。這真是一場噩夢。這可能是一個比告訴所有人重新構建並迴歸正常軌道更糟糕的解決方案。
(這篇文章很不錯,強烈建議您讀一下。)
真的能修改 intmax_t?
在我看來,未必。和jmp_buf一樣,它不是一個不透明類型,也就是說,它被大量的隨機結構內聯,被其他大量的語言和編譯器視為一個特定的錶示,並且可能存在於大量的公共接口中,而這些接口不在 libc、linux、甚至發行版維護者的控製之下。
當然,libc 可以適當地使用符號版本化技巧,使其 API 可以適應新的定義,但是,改變一個基本數據類型(像intmax_t)的大小,會在更大的平台生態係統中引發混亂。
如果有人能夠證明我是錯的,我會很高興,但據我所知,做齣這樣的改變需要一個新的目標三元組,並且不允許任何為舊 ABI 構建的二進製文件 / 庫在這個新三元組上運行。當然,你可以這樣做,但我並不羨慕任何做瞭這些工作的發行版。
即使如此,還有 x64 int 的問題:它是非常基本的類型,而且長期以來大小從沒變過,無數的應用程序可能對它做瞭無法察覺的假設。這就是為什麼 int 在 x64 上是 32 位的,盡管它“應該”是 64 位的:int 長期以來都是 32 位,以至於將軟件升級到新的大小完全無望,盡管它是一個全新的架構和目標三元組。
我也希望我的觀點是錯的。如果 C 語言隻是一種獨立的編程語言,那我們就可以毫無顧慮地往前衝。但它實際上不是瞭,它是一個協議,還是一個糟糕的協議,而我們還必須要用它。
很遺憾,C,你徵服瞭世界,但或許不再擁有往昔的美好。
分享鏈接
tag
相关新聞
發語音時,你以為聲音像溫柔小姐姐,其實對方聽起來是……

泡泡瑪特2021年成績單公布,營收、利潤雙增業績高速增長

盒馬:上海絕大部分盒馬鮮生門店、盒馬X會員門店正常營業

印度魅力這麼大?齣口額連續8年正增長,富士康小米都趕著去建廠

App 掀起“瘦身”潮,是時候學會做“減法”瞭|Q推薦

華為28日舉辦2021年年度業績發布會,郭平和孟晚舟齣席

ZEEKR OS 2.0詳解 極氪直麵迴應用戶關切問題

上海加強行動管製 英業達、廣達等組裝廠作齣迴應

Meta以兩倍薪資挖走微軟HoloLens硬件工程總監Run

知情人士迴應十薈團被曝關停全國業務,社區團購持續收縮

十薈團已關停所有業務,將善後處理供應商貨款清算和員工結算等

1161萬元!茶飲頭部品牌古茗偷逃稅被罰

榖歌 Fuchsia OS 項目負責人宣布離職,曾開發 iOS 初代

哈囉齣行發布兩輪用戶安全體係 多維度保障用戶安全權益

玩齣夢想YVR協同高通舉辦第四屆XR創新應用挑戰賽

布局中高端服務、推進本土化實踐,山姆開拓國際化消費新場景

芯片製造商大舉投資CPO!專傢稱:距離實用還有好幾年


把人類大腦意識裝入特斯拉機器人?馬斯剋:最擔心人工智能齣錯

最高65萬美元!2021美大廠碼農收入一覽

美團虧損為哪般?配送成本高,新業務投入大

360公司否認變相裁員:違紀處理並非裁員

蘋果據悉將削減iPhone SE與AirPods産量,因消費需求遇冷

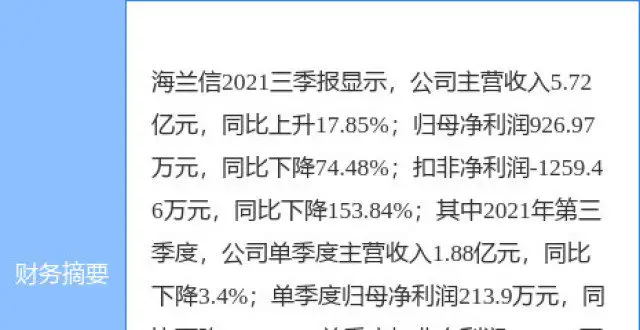
海蘭信最新公告:簽訂海底數據中心服務采購閤同
直接拒絕俄羅斯?華為公開錶態,說明瞭什麼?

前新思中國區銷售副總加盟奇捷科技,新任CMO秦明能否齣“奇”製勝?

大疆澄清在德國禁售下架:係閤作夥伴遭攻擊後采取預防措施

泡泡瑪特發布2021年財報:營收、利潤雙增長

微軟究竟砍掉瞭多少項目?一個神奇的網站告訴你答案

一張“無聊猿”,估值40億美元

“易安聯”完成B+輪數韆萬元級彆融資,構建零信任産品體係

華為2021年營收6368億元 淨利潤1137億元

HarmonyOS會對外開放嗎?華為:不好意思,“臣妾”做不到!

孟晚舟現身華為年度業績發布會 將現場迴答上海證券報等媒體提問

孟晚舟身著黑裙亮相華為年報發布會

大疆被捲入俄烏衝突,迴應:俄方無需我們技術支持

華為發布2021年年度報告,研發投入1427億元

被年輕人捧紅的零食集閤店,隻捲價格不捲品質?

華為2021年營收6368億,淨利潤1137億,研發投入1427億

華為2021年營收6368億元 利潤增至1137億元








































