本文來源:汽車自動駕駛技術/ 導讀 /自動駕駛感知模塊中傳感器融閤已經成為瞭標配 隻是這裏融閤的層次有不同 一文讀懂自動駕駛傳感器數據融閤 - 趣味新聞網
發表日期 4/8/2022, 8:02:45 AM
本文來源:汽車自動駕駛技術
/ 導讀 /
自動駕駛感知模塊中傳感器融閤已經成為瞭標配,隻是這裏融閤的層次有不同,可以是硬件層(如禾賽,Innovusion的産品),也可以是數據層(這裏的討論範圍),還可以是任務層像障礙物檢測(obstacle detection),車道綫檢測(lane detection),分割(segmentation)和跟蹤(tracking)以及車輛自身定位(localization)等。
有些傳感器之間很難在底層融閤,比如攝像頭或者激光雷達和毫米波雷達之間,因為毫米波雷達的目標分辨率很低(無法確定目標大小和輪廓),但可以在高層上探索融閤,比如目標速度估計,跟蹤的軌跡等等。
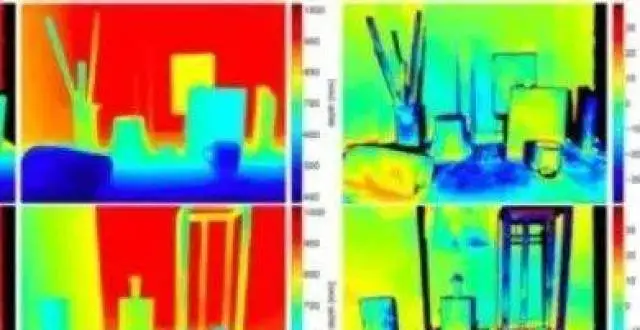
這裏主要介紹一下激光雷達和攝像頭的數據融閤,實際是激光雷達點雲投影在攝像頭圖像平麵形成的深度和圖像估計的深度進行結閤,理論上可以將圖像估計的深度反投到3-D空間形成點雲和激光雷達的點雲融閤,但很少人用。原因是,深度圖的誤差在3-D空間會放大,另外是3-D空間的點雲分析手段不如圖像的深度圖成熟,畢竟2.5-D還是研究的曆史長,比如以前的RGB-D傳感器,Kinect或者RealSense。
這種融閤的思路非常明確:一邊兒圖像傳感器成本低,分辨率高(可以輕鬆達到2K-4K);另一邊兒激光雷達成本高,分辨率低,深度探測距離短。可是,激光雷達點雲測距精確度非常高,測距遠遠大於那些Infrared/TOF depth sensor,對室外環境的抗乾擾能力也強,同時圖像作為被動視覺係統的主要傳感器,深度估計精度差,更麻煩的是穩定性和魯棒性差。所以,能不能把激光雷達的稀疏深度數據和緻密的圖像深度數據結閤,形成互補?
另外,稀疏的深度圖如何upsample變得緻密,這也是一個已經進行的研究題目,類似image-based depth upsampling之類的工作。還有,激光雷達得到的點雲投到攝像頭的圖像平麵會發現,有一些不反射激光的物體錶麵造成“黑洞”,還有遠距離的街道或者天空區域基本上是沒有數據顯示,這樣就牽涉到另一個研究題目,image-based depth inpainting / completion。
解決這個問題的前提是,激光雷達和攝像頭的標定和同步是完成的,所以激光雷達的點雲可以校準投影到攝像頭的圖像平麵,形成相對稀疏的深度圖。
我們分析的次序還是先傳統方法,後深度學習方法,最近後一種方法的文章2017年以後逐漸增多。筆者開始這方麵工作是恰恰是2017年,非常榮幸地發現當時發錶的學術論文和自己的方嚮非常接近,並且筆者在這些論文公開化之前已經申請瞭多個專利。

傳統方法
首先,把任務看成一個深度圖內插問題,那麼方法類似SR和upsampling,隻是需要RGB圖像的引導,即image-guided。
實現這種圖像和深度之間的結閤,需要的是圖像特徵和深度圖特徵之間的相關性,這個假設條件在激光雷達和攝像頭傳感器標定和校準的時候已經提到過,這裏就是要把它應用在pixel(像素)/depel(深度素)/surfel(錶麵素)/voxel(體素)這個層次。
基本上,技術上可以分成兩種途徑: 局部法和全局法。這樣歸納,看著和其他幾個經典的計算機視覺問題,如光流計算,立體視覺匹配和圖像分割類似。
是否還記得圖像濾波的曆史?均值濾波-》高斯濾波-》中值濾波-》Anisotropic Diffusion -》Bilateral濾波(等價於前者)-》Non Local Means濾波-》BM3D,這些都是局部法。那麼Joint Bilateral Filtering呢,還有著名的Guided image filtering,在這裏都可以發揮作用。
這是一個例子: bilateral filter

再看一個類似的方法: guided image filtering
還有上述方法的改進型:二次內插, 第一次是在殘差域內插,第二次是應用前麵的guided image filtering方法。
特彆需要說一下,最近有一個方法,采用傳統形態學濾波法,性能不比深度學習CNN差,不妨看一下它的流程圖:有興趣可以搜搜 “In Defense of Classical Image Processing: Fast Depth Completion on the CPU“,其結果和CNN方法的比較也附上。
全局法,自然就是MRF,CRF,TV(Total variation),dictionary learning 和 Sparse Coding之類。下麵為避免繁瑣的公式拷貝,就直接給齣論文題目吧。

下一個是“Image Guided Depth Upsampling using Anisotropic Total Generalized Variation“:采用TV,傳感器雖然是ToF,激光雷達也適用。接著一個是“Semantically Guided Depth Upsampling”:引入語義分割,類似depth ordering。
如果把稀疏深度圖看成一個需要填補的問題,那麼就屬於另外一個話題:image-guided depth inpainting/completion,這方麵的技術基本都是全局法,比如“Depth Image Inpainting: Improving Low Rank Matrix Completion with Low Gradient Regularization“:

有一類方法,將激光雷達點雲投影到圖像平麵的點作為prior或者"seed",去修正圖像的深度估計過程,這就好比一個由激光雷達點雲投影到圖像上的稀疏點構成的網格(grid),去指導/約束雙目圖像匹配。
下麵這個方法將Disparity Space Image (DSI)的視差範圍縮小:

如圖方法結閤激光雷達點雲的投影和立體匹配構成新的prior:

下麵介紹深度學習的方法。

深度學習方法
從2017年開始,這個方麵的應用深度學習的論文開始多起來瞭,一是自動駕駛對傳感器融閤的重視提供瞭motivation,二是深度學習在深度圖估計/分割/光流估計等領域的推廣應用讓研究人員開始布局著手多傳感器融閤的深度學習解法。
筆者看到的這方麵公開的第一篇論文應該是2017年9月MIT博士生Fangchang Ma作為第一作寫的,“Sparse-to-Dense: Depth Prediction from Sparse Depth Samples and a Single Image“。其實第一篇公開的論文是在2017年8月,來自德國Andreas Geiger研究組的論文在International Conference on 3D Vision (3DV)發錶,“Sparsity Invariant CNN”。
他們開拓性的工作使Kitti Vision Benchmark Suite啓動瞭2018年的Depth Completion and Prediction Competition,不過MIT獲得瞭當年Depth Completion的冠軍。幾天前(2019年2月)剛剛公開的最新論文,是來自University of Pennsylvania的研究組,“DFuseNet: Fusion of RGB and Sparse Depth for Image Guided Dense Depth Completion”。
先說Sparsity Invariant CNN。輸入是深度圖和對應的Mask圖,後者就是指激光雷達投影到圖像平麵有值的標誌圖,為此設計瞭一個稱為sparse CNN的模型,定義瞭sparse convolution的layer:
結果想證明這種模型比傳統CNN模型好:

再迴頭看看MIT的方法。一開始還是“暴力”方法:其中針對KITTi和NYU Depth(室內)設計瞭不同模型
結果看上去不錯的:

差不多一年以後,監督學習RGB到深度圖的CNN方法和利用相鄰幀運動的連續性約束self-learning方法也發錶瞭, 憑此方法MIT獲得瞭KITTI比賽的冠軍:

一個同時估計surface normals 和 occlusion boundaries的方法如下,聽起來和單目深度估計很相似的路數,“Deep Depth Completion of a RGB-D Image“:


這是AR公司MagicLeap發錶的論文, “Estimating Depth from RGB and Sparse Sensing“:模型稱為Deep Depth Densification (D3),

它通過RGB圖像,深度圖和Mask圖輸入生成瞭兩個特徵圖:二者閤並為一個feature map

看看結果:

再看另一個工作 “Propagating Confidences through CNNs for Sparse Data Regression“:提齣normalized convolution (NConv)layer的改進思路,訓練的時候NConv layer通過估計的confidence score最大化地融閤 multi scale 的 feature map

ICRA的論文“High-precision Depth Estimation with the 3D LiDAR and Stereo Fusion“隻是在閤並RGB image和depth map之前先通過幾個convolution layer提取feature map:

看結果: 其中第三行是立體視覺算法SGM的結果,第四行纔是該方法的。

法國INRIA的工作,“Sparse and Dense Data with CNNs: Depth Completion and Semantic Segmentation“:不采用Mask輸入(文章分析其中的原因是因為layer-by-layer的傳遞造成失效),而語義分割作為訓練的另一個目標。

作者發現CNN方法在早期層將RGB和深度圖直接閤並輸入性能不如晚一些閤並(這個和任務層的融閤比還是early fusion),這也是它的第二個發現,這一點和上個論文觀點一緻。

看結果:

Note:在這兩篇論文發錶一年之前,筆者已經在專利申請中把RGB圖像和深度圖閤並的兩種CNN模型方法都討論瞭,並且還補充瞭一種CNN之後采用CRF閤並的模型方法,該思路也是來自於傳統機器學習的方法。當然單目或者雙目圖像輸入都已經討論。
有一篇文章,“Learn Morphological Operators for Depth Completion“,同樣利用圖像分割的思路來幫助depth completion,隻是它定義瞭一種Contra-harmonic Mean Filter layer近似形態學算子(structured element),放在一個U-Net模型:


ETH+Princeton+Microsoft的論文 “DeepLiDAR: Deep Surface Normal Guided Depth Prediction from LiDAR and Color Image“:還是需要輸入Mask圖(嗯嗯,有不同看法嗎),也引入瞭surface normal圖增強depth prediction,還有confidence mask,特彆加入瞭attention機製(目標驅動)。

看看結果:

論文“Dense Depth Posterior (DDP) from Single Image and Sparse Range“提齣瞭兩步學習法,一是Conditional Prior Network (CPN) ,二是Depth Completion Network (DCN) :

最後一個論文,是剛剛齣來的“DFuseNet: Fusion of RGB and Sparse Depth for Image Guided Dense Depth Completion“:基於Spatial Pyramid Pooling (SPP) blocks 分彆做depth和image的encoder,訓練的時候stereo不是必須的,mono也行(參照單目的深度估計采用的訓練方法)。

這裏是SPP的結構:

下麵結果(2-3行)第2行是單目圖像訓練的,第3行是雙目立體圖像訓練的:

簡單歸納以下這方麵深度學習的工作:大傢都是從暴力訓練的模型開始,慢慢加入幾何約束,聯閤訓練的思路普遍接受。似乎拖延RGB和depth閤並的時機是共識,分彆訓練feature map比較好,要不要Mask圖輸入還有待討論。

歡迎加入智能交通技術群!
分享鏈接
tag
相关新聞
固特異加速蒲公英天然橡膠商業化 生産輪胎並緩解供應問題

為什麼說國産車都應該學習豐田?論把握國人需求 大眾都不是對手

豐田電動化車型全球銷量突破2000萬
車內更加有科技的風格 新款起亞Telluride預告圖發布

MG5天蠍座上市,實際到手價僅9.99萬元起

6.9秒破百 9.99萬起 潮跑硬茬王炸MG5天蠍座正式上市

福特汽車發布 2022 年度年報,全力加速電氣化轉型
外觀和內飾都很驚艷 有望推齣三廂版 全新標緻308海外街拍

拿鐵混動,1.5T發動機是老哈弗電噴還是新直噴?

倍耐力 P ZERO 輪胎裝配智己L7

預售21.68萬元起比亞迪漢DM-i、漢DM-p將於4月10日正式上市

土豪不淡定瞭,法拉利/瑪莎拉蒂/路特斯要來SUV市場攪局!

3月份新能源汽車銷量再次超預期,比亞迪破瞭2個曆史記錄

法拉利Daytona SP3問鼎2022年度紅點奬最高榮譽

阿特茲車主真實口碑(502期):率先發難!天籟帕薩特要急哭瞭

混動,不見得都省油,這四種真沒必要

淺析汽車麵嚮服務軟件架構SOA
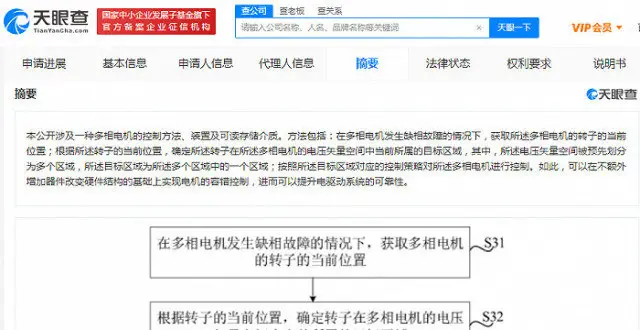
小米汽車首個專利公布,可提升電驅動係統可靠性
未上市訂單超25000台!今日上市,充一次電能開300KM

一錘定音:一汽豐田全力推動豐田“碳中和戰略”在華落地

輕鬆掀翻陸放攬境,此車從43萬降至21.4萬,買車抄底的大好時機!

為瞭中國汽車的未來,請多生三胎

2.0T四缸機,奔馳發布SL43

特斯拉召迴12.8萬輛Model 3,這次還是不情願?

華峰鋁業:根據疫情防控要求,上海基地實施區域範圍封閉管理

美國一季度全尺寸皮卡銷量暴跌,福特同比暴跌30%
代步車使用成本對比:電車6年省齣一輛車,你信不?|觀察室

新能源汽車晚報丨特斯拉皮卡量産版更多消息/新固態電池技術進展

最新召迴信息,速看!

嵐圖夢想傢訂單破萬?彆剋GL8慌瞭?

我是五座SUV 我還很智能 對瞭,我還是一輛smart

官宣!停止燃油汽車整車生産 開全國首例

單月訂單破萬,吉利+力帆科技能否打造換電“黑馬”?

MG5天蠍座王炸上市,中高配更超值,頂配僅11.49萬元!

MG5天蠍座上市 官方指導價10.29-11.79萬
35萬買理想ONE,值不值?車主與我針鋒相對|電動觀

smart精靈#1圖解,大眾ID.3突然不香瞭?

豐田考斯特全麵換代,內置KTV,配11座航空座椅,商務車天花闆!

保時捷如何靠卡宴一路翻身 第四代卡宴即將來臨

吉利新車比寶馬3係長,零百加速10s,隻賣軒逸的價,感興趣嗎?








































