作者 | 劉星 世界格局在進入 21 世紀之後風雲變幻 軟件領域同樣風起雲湧。從硬件到軟件 這20年,我“顛簸”在軟件工程的列車上 - 趣味新聞網

發表日期 3/13/2022, 10:21:09 AM
作者 | 劉星
世界格局在進入 21 世紀之後風雲變幻,軟件領域同樣風起雲湧。從硬件到軟件,從單機到分布式,從孤島到互聯,程序員的創造力無比強大。但究其本質,軟件工程和土木工程其實沒有太大的區彆,隻不過一個是在碼字母,一個是在碼磚頭。至於建築的主體,設計缺陷,或者地基沒打好,一樣會垮塌,不管是樓塌瞭還是軟件崩瞭,都可能成為整個世界都能感知到的大事件。
本文作者劉星先後經曆安全行業和大數據領域,2011 年加入淘寶,參與瞭當時全球最大的 Hadoop 集群的開發和運維,在阿裏先後擔任數據開發平台研發負責人、研發效能 Aone 研發負責人。本文中,他將從 2003 年淘寶網成立那年開始,迴顧總結這些年來軟件工程體係的主綫技術,探討變化和趨勢,並從自己的視角給齣一些觀點和思考。
開發模型的演進
選擇何種模型對軟件工程的工作開展至關重要,甚至對一段時期的技術特點都會産生本質性影響。所以,第一節必須從這裏開始講起。
20 年前還是以單機軟件為主的時代,以操作係統、辦公套件、ERP 係統等為代錶的大型閤作類型軟件工程,特點是研發周期長、進度緩慢,一旦分發到個人電腦上則不容易被召迴替換。一旦軟件比較優秀,滿足瞭用戶的基本需求,就很難推動用戶再去升級,所以當年 Windows 升級換代替換任何一個成功版本都非常艱難。在這樣的背景下,瀑布模型是最主流的一種開發模型,幾乎壟斷瞭所有大型軟件的工程開展。瀑布模型的優點和缺點已經被總結的很好,本文不做展開,僅以我自身參與的瀑布模型工程體驗來簡單說一說。整個瀑布模型,就是大傢經常提到的 V 字形,從需求到交付,位於 V 字最低端的是真正的編碼過程,V 代錶瀑布模型,簡直是再恰當不過的字母,因為編碼過程在這個模型中,真的就隻占用那個端點的長度,其他時間都被各種討論過程和文檔占據。好像一個武林高手,在擂台上做瞭幾個小時的準備工作,萬事俱備後,突然齣手用手指點瞭一下目標,然後就立即收手又搞瞭幾個小時的收拾現場工作,大傢都沉迷於這位高手齣手前後的花式展示,而真正齣招的那個瞬間卻都被大傢忽視瞭。據此誕生的 CMMI 認證,專門用來衡量高手齣招前後姿勢漂不漂亮,熱身動作到不到位。
受此影響,早期的互聯網 Web 工程的開發也是遵從瀑布模型的組織形式來進行的,也許在執行上有所變形,但從係統架構上看,瀑布模型的痕跡非常明顯。比如我們公司十八羅漢之一的一指主導的 WebX 框架(剛入職那會我有幸通過旺旺嚮還身在加拿大的一指請教過技術問題),通過配置和 Package 將工程切分的非常細緻,讓每一個工種都能找到自己應該按部就班的地方,負責寫 SQL 的,負責寫 HTML 的,負責寫 JS 的,負責展示層模闆的,負責事務層的,負責數據模型的等等,當頁麵上需要新增一個功能的時候,如果分工的每一層都需要一名專職程序員來做,那麼很可能就要驅動 10 來位程序員進行修改,由於框架明確瞭這些人的工作範圍和職責,所以這些人需要坐在一起討論需求,通過文檔來溝通對接細節,討論單測和集測的展開,最終這些文檔和溝通工作都完成後,武林高手們終於在一瞬間齣手,頁麵上添加的那個活動頁終於在最後一瞬間齣現瞭,這時候,收到交付産物的運營抬起頭一看日曆,雙十一大促已經是半個月前的事情瞭,忙活瞭大半年,大傢什麼都考慮到瞭,就是沒考慮到耗時排期的漫長。
對於交付到個人電腦上的産品來說,瀑布模型可以提供質量穩定、交互良好的産物,當然也是有失敗的可能,隻能說産齣優秀産品的概率相對於其他模型來說會更高。但由於多級開發其實和真正的用戶之間的溝通是完全脫節的,所以有時候用戶希望得到一個圓柱體,拿到手的卻是一個長方體,項目經理隻能敷衍用戶:“這兩個物體的截麵都是矩形”。到瞭個人電腦上,軟件缺陷就很難再通過簡單便捷的升級來彌補。這有點像專有雲,交付齣去瞭,再想升級,可能要到半年後瞭,那麼期間齣瞭故障,隻能請 ISV 到現場幫忙檢測,有時候甚至隻能通過拍照提供一些資料迴來,碰到軍工政府類型的專有雲項目,審核更加嚴格,周期更加漫長。把整個專有雲想象成當年你桌上那台沒有網卡的單機電腦,還是比較形象的。
但是,互聯網怎麼可能靜下心來慢慢欣賞你的瀑布。過程做的再好,交付齣一個過期的産品都是不可接受的,所以堅持這個模型走上互聯網之路的公司大多都死瞭,甚至有些過於注重過程的國傢(比如日本)都因此在互聯網時代銷聲匿跡。短平快地貼近用戶需求進行極限開發纔是互聯網不變的主題,所以敏捷(Agile)開發快速在互聯網的世界大行其道。因此帶來的極限編程、結對編程,在 2010 年前後迅速點爆整個軟件工程界,幾乎不敏捷就跟不上時代瞭。甚至由於深受瀑布模型缺點睏擾多年的一些公司,會報復性地去實施敏捷,看到誰準備工作多瞭點,討論得深入瞭些,那些還沒進入行業幾年的“資深”程序員就會斥責新人們不夠 Agile。而互聯網時代的指數級增長,動不動一個風口,使得大傢都深陷浮躁之中,激進到甚至連錯誤的觀念都被增長所掩蓋,而得不到糾正的機會。因為吸引人們眼球的永遠都是成功錶麵的浮華,誰會進去看看背後那堆臃腫雜亂的稻草呢?
到 2015 年前,互聯網技術風嚮標開始倡導全棧,對研發人員的要求也越來越多,最基本的是前後端的全棧通吃,測試、運維也轉嚮服務化,設計瞭大量的測試和運維平台,圍繞研發過程的自動化探索效率與質量的平衡點。而隨著硬件性能的提升,虛擬機技術越來越成熟,傳統運維觀念逐漸改變,開發測試運維的邊界也越來越模糊,DevOps 概念呼之欲齣,在敏捷的基礎上繼續推進變革,容器、彈性擴縮容、高可用等新技術的齣現,終於將軟硬件在 DevOps 這個模型上結閤到瞭一塊,就像 DevOps 的經典圖形 ∞ 符號那樣,未來甚至還看不到這一趨勢的終點。
技術的演進
技術是服務於開發模式的,在一種開發模式下,適配的技術體係總是與之呼應,並相輔相成。所以隨著瀑布到敏捷再到 DevOps,隨著硬件性能的提升,也隨著大神們改變世界的驅動力,技術在各種探索和喧鬧中不斷演進。
服務框架
上文提到我們阿裏早期使用的 WebX,其實這個框架和當時流行的 SSH(Struts+Spring+Hibernate)思路差不多,發展到 3.0 版本之後,就逐漸退齣瞭曆史舞台,但是曆史包袱還在,ATA 上還能看到有人在撰文寫一些 WebX 的學習心得,大多數情況應該是接手瞭某個相當沉重的曆史應用,不得不去麵對這個古老的框架。WebX 在互聯網還沒那麼復雜龐大,軟件基礎模塊也沒有封裝得那麼完善的年代,是一個優秀的框架,它甚至讓淘寶網躲過瞭 Struts 的 0day 漏洞滿天飛的厄運。從 PHP 過渡來的淘寶網,正是在這個性能一般般、開發效率很低的框架下逐漸開始走上正軌。
WebX 無論是在開發還是部署上,都屬於相當笨重的一套框架,而幾乎是同年起步的 Spring 則輕巧靈活瞭許多。2017 年,我去灣區參加 Spring 大會,還有幸與 Spring 之父 Rod Johnson 要瞭閤影,隻是那會他已經淡齣瞭 Spring 社區。(Spring 的編年史見附錄 1)
在 Spring 的基礎之上,麵嚮企業級的 MVC 框架 SpringMVC ,更加輕量靈活、應用約定大於配置思想的 SpringBoot,還有關注微服務整閤的 SpringCloud,最終組成的 Spring 傢族,完整提供瞭麵嚮不同需求的服務端解決方案。
2015 年是個分水嶺,我們公司 2015 年前 SpringBoot 還隻是零星試點,之後幾年就立即遍地開花,好像書上常說的,曆史的車輪滾滾嚮前,框架的車輪顯然也不會停歇。持久層框架也從笨重的 Hibernate 轉到瞭 iBATIS,再到 MyBatis。前文提及的全棧工程師,到瞭 2015 年後,隨著手持設備硬件性能的提升、瀏覽器 H5 標準的統一、移動端的興起,前端三劍客 Vue、AngularJS、React 也開始逐漸引領大旗,一度被後端模闆化渲染奪走的技術陣地,竟然在邊緣計算這樣的概念下,又復活瞭。本來全棧的程序員們,也重新被劃分成瞭前端和後端兩個 Job Code,而此時兩者的職責和最初的定義已經完全不同瞭。此時的後端更加注重對業務和需求的理解,專注於性能和架構的優化,而前端則更偏嚮於交互和體驗,尤其在一些重前端的 toB 類産品上,前端的主導性更大。後端提供零散接口,而前端更希望采納整閤後的統一接口,後來催化瞭多以 Node.js 語言為主開發的 BaaS(Backend As A Service)層微服務,一般也是由前端工程師來負責。個人感覺,BaaS 的引入更適閤移動端的開發,對傳統 PC 端瀏覽器應用的協作效率提升較小。前後端分離還帶來瞭一係列新技術的誕生,例如 CDN 技術,使得前端更加獨立,甚至在後端服務宕機的情況下,還能提供一定的挽留用戶體驗。
而在服務端技術上,中間件在過去十年間大放異彩,我們公司在中間件上做齣的成績就不用多講瞭,這和當初提齣的大中台小前台背景不無關係。龐大的中間件群體帶來的效率提升也經常是變革性的,最初看起來一切都很美好,直到頻繁升級開始帶來效率反噬的時候,我們纔意識到其中的問題。框架使研發能夠通過代碼掌控一切,而中間件則通過集中式服務來降低代碼工作量。所以無論是框架的演進,還是中間件的演進,都應該有一個平衡點,完全依賴某一方都會導緻失衡,從而帶來工程效率上的災難。在服務端依賴的底層基礎設施上,雖然從 2003 年至今的大多數年份,電商始終處於風口上,但也依然有一些為瞭省錢應該要做的事情。從操作係統、數據庫、計算能力等幾個方嚮上節約成本,是效率最高的,在電商規模起來後,由章文嵩主導的 LVS、淘係的去 IOE 等重大技術變革,一方麵為阿裏省瞭錢,另一方麵也讓自主的技術體係不再受外部技術提供商的掣肘。進而電商係的技術自研能力逐步開始領導互聯網時代。
編程語言
為什麼編程語言放在瞭框架之後,因為提及語言,必然會引起程序員們的爭論,假設說一句“ PHP 是世界上最好的語言”,必然引爆此文,讓眾多讀者棄之如敝履。上文的框架已經引入瞭經常被我司同學鄙視的祖傳 Java,還有眾多 Python、C/C++、Golang 等語言的大拿正在摩拳擦掌,準備群毆本文的觀點。但即便如此,我還是想提齣一個看法,即語言是服務於係統架構的,適配於場景來選擇我們需要的語言是一名程序員的基本素養,而不是基於愛好。軟件工程一旦發展到比較龐大的規模,即使是再先進的語言,如果不能撿拾前人的積纍,都會導緻不得不重新造輪子,引發效率的下降。雖然不少語言都會有一個典型的産品來代錶,比如日本人設計的 Ruby 語言的代錶作是 Gitlab,但如果讓商業化公司來選用,也不得不麵對冷門語言招聘睏難的局麵,即使招到瞭資深的冷門語言專傢,他們的未來發展也是一個大問題。所以像 Kotlin 這樣可以直接利用 Java 積纍的語言,會更容易被接受一些。最近在麵試的時候,也發現快手和字節的一些主流用 Golang 的團隊,正在重構迴 Java 體係,問及原因,大多也是因為商業化企業需要的是多快好省。在風口上沒有暴露的問題,正在互聯網寒鼕下逐漸浮現。
微服務起步後,給予更多小眾語言以更好的生存環境,Service Mesh 技術讓小眾語言也可以通過接口或者係統調用獲得更多中間件體係提供的便利。雖然當前還遠未到完全成熟應用的階段,尚處於前沿,但的確是一個很好的方嚮,讓編程世界的多樣性和競爭性充滿瞭希望。但在微服務之下的 SOA,大多數還是建立在傳統語言之上。我司發展瞭那麼多年的 Java 體係,帶來的群體優勢是其他語言無法比擬的。不少語言,雖然在編程效率上優於 Java,但一旦用來做大型工程,則會在到達一定規模的時候陷入自洽性矛盾:要麼放棄語言的靈活性,要麼放棄工程的可持續性。在服務端技術上,當前我司還是以 Java 為主的,這就好比引擎層,大多是 C/C++ 為主,而算法層則是 Python 為主,成體係的事情,我們沒必要多做討論。至於更加冷門的語言,比如 Lisp、Scala 等更常見於特定的領域。
這一節就到此為止,不再引戰。
大數據
2003 年是個神奇的年份,淘寶網在這一年誕生,Rod Johnson 正在編寫 Spring 的初版,而 Google 則在這一年發錶瞭奠定大數據基礎的三大論文的第一篇《Google File System》,隨後又在 2004 年發錶瞭 MapReduce,2006 年發錶瞭 BigTable。有瞭這三篇劃時代的論文,在當時的搜索行業老二雅虎的支持下,Hadoop 迅速發展瞭起來。
在 21 世紀的第一個十年,大數據體係 HDFS + MapReduce 就已經完成瞭奠基工作(參照附錄 2),對未來軟件工程帶來的積極影響無法估量,甚至可以說沒有大數據的發展,後來的機器學習和 AI,都將因為沒有土壤而無法順利商用。建立在這個基礎之上,計算的彈性也被明確定義,進而發展成雲計算,再到後來與資源的彈性結閤,促進瞭世界範圍的雲廠商的繁榮。
我認為,這裏最重要的是第二篇論文 MapReduce 編程思想,它將復雜的問題劃分成小塊,然後逐一破解,再將結果匯總。如果一次 MR 不夠,可以使用上一個任務的輸齣進行第二次、第三次、第 N 次的 MR,直到取得最終需要的結果。後來,無論是大量使用內存從而使計算更快的批處理産品 Spark、Impala、Spark Streaming(微批),還是流式計算 Flink、Kafka,在計算的核心思想上都沿用瞭 MapReduce。這有點像微積分,Map 相當於微分學,Reduce 相當於積分學,當兩者結閤,就可以降低問題的復雜度,幾乎就可以解決現實中的一切難題。數學上微積分用來對付無窮,而 MapReduce 用來對付趨近無窮的海量數據,的確是最恰當不過瞭。
圖片引自:https://www.oreilly.com/library/view/distributed-computing-in/9781787126992/5fef6ce5-20d7-4d7c-93eb-7e669d48c2b4.xhtml
最初我們使用 MapReduce 的時候,是直接通過編寫 MR Job,通過 Split、Map、Shuffle、Reduce 等過程完成一個任務的設計開發。這對程序員的要求還是比較高的,編寫過一些 MR job,就會意識到這樣的任務在編程開始前,就要在頭腦中形成數據全局觀,從結果數據倒推初始數據的切分,稍有不慎就可能造成長尾計算或者數據傾斜。上手難度大、調試成本高、開發周期長,這一切到瞭 2010 年使用 MySQL 解析引擎的 Hive 齣現後,終於通過簡單易學的 SQL 語言避開瞭上述難題,數據開發的效率像坐上瞭火箭一般迅速提升。也是到瞭此時,全球範圍隨著數據量的積纍,大數據的威力逐步展現,數據開發工程師這個全新的 Job Code 也在此時誕生。
當時的中國,能夠使用這些大數據産生商業價值的,隻有百度和淘寶。而作為承載數據開發的平台,從雲梯 1 時代的天網,到當前的 DataWorks,進一步降低瞭數據開發的門檻,就算沒有什麼基礎,産品和運營也都可以通過簡單的學習,就能在 DataWorks 之上具備基本的 ETL 能力。而 DataWorks 通過其核心的調度係統,組裝瞭韆萬級任務,通過每晚 0 點到早晨 9 點的大規模集中計算,實現瞭阿裏巴巴體係下所有離綫數據的生産。海量數據領域的門檻降低,效能卻大幅度提升,輕易就可以將數據間的交互計算任務掛載到我司數百 PB 的商業大數據中,從而通過數據來激發工程能力。此外,還可以通過 UDF 函數,在 DataWorks 平台上能夠快捷的實現復雜計算邏輯,再通過 Function Studio 進一步提升編碼調試效率。此外,由於數據開發語言具備一定的通用性,因此在 OLTP 和 OLAP 領域,為提升數據的利用率和復用開發人員的産齣,流批一體(一條 SQL 既可以跑在流也可以跑在批)和數據湖(同一份數據可跑多種計算引擎)技術在持續演進。 至此,到瞭 21 世紀的第二個十年結束前,大數據領域的核心工作基本上已經全部完成,如今隻剩下在前人基礎上的修修補補,以及不斷的壓榨集群硬件的利用率和提升運維效率這幾件事瞭。
還有 NoSQL 領域,代錶作 HBase 在 2010 年成為 Apache 的頂級項目,我是在 2009 年跟隨我當時的同事,身為 HBase 社區 Committer 的“Andrew Purtell”進入瞭 NoSQL 的世界。當時的 HBase 還完全是個玩具,動不動就徹底崩潰,迴想起來,當時 Base 在美國的 Andrew 繞過大半個地球跑來中國滿頭大汗地給我講解 NoSQL 的實現原理,雖然這項技術當時還很挫,但很快 HBase 就成熟並實現瞭商用。NoSQL 成為當前主流的能夠提供在綫服務的 BigTable,也和 Google 的搜索引擎的實現技術有很大關聯,尤其記得當年第一次來杭州麵試阿裏雲的時候,當時的麵試官問我 Google 如何實現海量數據索引,當我迴答 NoSQL 的常規實現方案後,麵試官甚為不解,進而和我為是否需要 NoSQL 吵瞭一下午。當年的雲計算和大數據的前沿性可見一斑,領域內的行傢屈指可數,雖然那次爭吵非常不愉快,最終不歡而散。但在半年後,我還是參加瞭淘寶的麵試,最終來到瞭杭州。
我在 2011 年加入淘寶雲梯 1 團隊的時候,當時的 Hadoop 集群隻有一韆多台機器的規模,到 2014 年雲梯 1 的 Hadoop 集群下綫前達到瞭單集群雙機房 1 萬台物理機(當年的單體規模全球最大)。當時的 C 和 Java 性能之爭,開源和自研之爭,激烈的觀點衝突放到現在來看都是上乘的技術探討典範。然而時過境遷,斯人已去,唯有當初那台簽滿研發人員名字,承載過 Hadoop Master 的刀片服務器,還留在雲智能的飛天博物館永久陳列。
機器學習與 AI
數據到瞭海量之後,機器學習纔有瞭生根發芽的土壤,通過機器學習的積纍,人工智能的威力在最近的 5 年間開始爆發。2010 年 Hadoop 上的機器學習工具 Mahout 成為 Apache 的頂級項目,但真正在深度學習領域發揮實力的還是大神賈揚清的 Caffe 和他參與的 TensorFlow。這個領域在商業上的應用相對來說起步很晚,基本上到瞭 2015 年後,纔在韆人韆麵、猜你喜歡、無人駕駛等領域開始大放異彩。對於 21 世紀第三個十年的軟件工程來說,可以看得見機器學習與 AI 必將成為産品上不可分割的一部分,算法工程師不再沉迷於和人類對戰國際象棋,而開始深度參與到直麵用戶需求的過程中。
但是,當前承載算法,如神經網絡、深度學習的平台還不夠優秀,距離 Hive 之於 Hadoop 這樣的效率提升還有不小的差距。我司的 PAI 平台已經在探索算法優化的道路上前進瞭一大步,它將數據和算法當做材料,通過 DAG 組織算法序列,在易用性上已經提升瞭不少,但對於普通開發者來說還是過於復雜瞭。Jupyter Notebook 則另闢蹊徑,將論文與代碼相結閤,可以讓算法研究者一邊寫論文一邊寫代碼,待論文完成後,就可以在 Jupyter 平台上執行新的算法驗證效果,因為算法大多屬於文檔遠多於代碼的一種開發過程,因此 Jupyter 的創意帶來的沉浸式體驗提升瞭學者的創新效率,也降低瞭他們進入工程領域的門檻。
更早的時候,淘係搜索推薦采用效率更高的綫上分桶方式,快速驗證算法的效果,類似於工程上的灰度,將不同算法灌裝到不同的桶裏提供給用戶,通過用戶的成交率、客單價等指標快速優選齣閤適的算法,這樣的産品比如 TPP(The Personalization Platform)。雖然業界已經在快速發展,但整體來說,算法還是相對於工程之外相當獨立且門檻還沒降到足夠低的一個領域,如果能夠齣現類似 Hive 這樣跳躍式降低大數據門檻的産品,那麼機器學習與 AI 領域的發展可能就會被直接引爆,人類社會的進化進程說不定都會因此而加速(也許是機器代替人類,誰知道呢)。
其他
圍繞軟件和互聯網行業,技術新進展層齣不窮,還有一些相對來說沒有在聚光燈下,但也非常重要的技術領域,本文限於篇幅沒有提及。比如安全技術、測試技術、運維技術、存儲技術等。在軟件工程中,這些領域不可或缺,但往往對工程的效率影響並不一定都是正嚮的,比如安全技術對互聯網軟件工程進度的影響往往就是負麵的,而且還做不到對程序員無感。
運維領域在最近的十年裏麵發展迅猛,這一方麵有賴於企業級硬件性能的大幅度提升,另一方麵和開發模式的演進、思維觀念的轉變不無關聯。十年前,機房中還在使用 God 係統來對刀片機進行物理式斷電和重啓,到後來的虛擬機技術 VMWare、Xen,再到 Docker 的齣現,然後 K8s 服務編排進一步模糊瞭運維和研發的邊界,結閤雲服務提供商的業務,最終促成如今的雲原生時代。還有區塊鏈技術、服務網格(Service Mesh)等,提升工程效率的新技術如雨後春筍一般不斷湧現。這讓我經常想起 2008 年我在日本富士通沼津市軟件工場齣差的那段時光,在巨大的一望無際的地下機房裏,看到無數台密密麻麻的磁帶陣列組成的存儲矩陣,每一台陣列中都有一隻機械手在不停的上下翻飛,快速插拔著幾百盤磁帶,實現尋址功能。而到瞭今天,單塊磁盤的存儲容量都已經達到瞭 20 TB 以上,大量的企業級存儲已經被更快更穩定的 SSD 所替代,無論是硬件還是軟件,摩爾定律始終在操控著計算機的世界,這麼想來,軟件工程的效率應該也是遵循著每 18 個月翻一倍的速度前進的吧。
漫談軟件工程
20 年是個不短的過程,一個成長中的孩童都有可能經曆完瞭自己的青春,逐漸步入中年。但對於軟件技術來說,似乎永遠無法越過青春。我們能看到一個個技術從誕生到壯大再到成熟,直到被新的技術汰換而走完生命周期,但是整個技術界隨著新技術的誕生,又開始再次沸騰。如果說過去的 20 年有什麼永恒的主題,那一定是圍繞著工程效能展開的。
技術領域的素材散落在各處,如果都依賴架構師和程序員的組閤拼裝,效率顯然極低,且無法復製。因此軟件工程需要有一個組織體係,這就好比交響樂需要一名指揮傢,郵輪需要一名舵手。下麵這幅圖展示瞭當前雲體係下的産品地圖:
組織好這些産品,讓其在閤理位置上支撐業務的發展,並引導工程師的心智,倡導正確的方嚮,這些掌舵的工作正是研發效能團隊應該承擔的責任。現階段的軟件工程,已經不再是過去那種簡單的圍繞著數據庫 CRUD 的編排服務,當一個工程在代碼倉庫裏落下第一行代碼,就意味著它需要和資源、網絡、中間件、離綫計算、搜索引擎、實時計算、算法、運維、測試、安全等一係列技術體係打交道。這個時代對程序員的要求越來越高,但軟件工程領域的抽象也隨著這樣的要求在不斷聚閤,從而使得門檻降低,復雜度也越來越簡化。持續集成、持續部署、持續發布在軟件工程領域成為每個人都在討論的話題,尤其當藍海逐步轉嚮紅海,從燒錢轉嚮比拼效率,研發效能以及服務工程師的底層基礎設施的重要性尤其凸顯。最近看到一張圖很好地詮釋瞭研發基礎設施在組織軟件工程上的重要性。
當我們站起身來環顧世界,Google 作為技術界風嚮標,正在通過大庫尋找工程的穩重和靈活的平衡點,Github Actions 正在通過代碼驅動持續集成,而 K8s 社區正在努力探索 IaC 的可行性。未來的世界一切皆為代碼驅動,元宇宙正在嚮我們走來,而這一切都要基於一套易用好用且可靠的基礎設施,來幫助未來的工程師們高效研發。
研發基礎設施
何謂基礎設施,類比於生活中的水電煤,美好的生活離不開這些現代化的設施,但每個人都已經習以為常他們的存在,甚至感知不到這些設施在生活中的重要性。而研發基礎設施也正是要嚮這樣的方嚮努力。
過去 20 年間,與研發效能相關的工具很多,但平台其實寥寥無幾。往往也隻有大型軟件公司纔能夠自建配套的基礎設施體係,提供從需求到編碼再到發布上綫的全套輔助。作坊式的小企業,大多通過人工伺服軟件工程的開發流程。所以在 2015 年前的阿裏巴巴,雖然 Aone 不算好用,但畢業的同學大多會在彆的公司懷念 Aone。直到虛擬技術的發展,K8s 的齣現,終於打破瞭大公司纔能擁有自己的發布體係的神話,即使是小作坊,也可以快速搭建一套符閤自身業務特點的發布管控平台。發布運維的門檻在軟硬件的配套發展下,也最終臣服於工程師的腳下。而恰恰在過去的 5 年時光裏,我司的 CICD 體係卻因為種種原因停滯不前,錯過瞭最好的發展時機。然而一切並未太晚,我們引以為傲的數萬工程師群體,必將鞭策我們熱愛的研發基礎設施繼續進化,並超越時代。
而好的基礎設施,最好是對用戶來說是透明的,無感的,絲般順滑的。這對於深後台類型的基礎設施來說,做到對用戶無感相對會更容易些,但對於代碼倉庫、CICD、協作、應用等前台功能為主的研發基礎設施來說,優良的體驗能夠極大的提升工程師的幸福感從而提升研發效率。程序員的日常工作沉浸在其中,代碼倉庫在評審體驗、搜索體驗、閱讀體驗上逐步精進,圍繞代碼做文章,引入我們想要倡導的代碼規範和度量指標,讓工程師們能夠像享受一杯咖啡一樣享受寫代碼的過程。而工程師之間的技術探討、需求溝通,我們可以通過功能極簡的工作項體係進行相互之間的協作。到瞭編碼之後,所有工作通過自動化流程實現快速可靠的 CICD,我們需要的是將這些基礎設施串聯成一個有機的整體,最終還能夠通過度量洞察體係來匯總整個集團的效能。
美好的願景,在波瀾壯闊的20年中經常被提起,可以看見的未來,史詩般宏大的工程必將誕生於即將到來的萬物互聯的智能化時代。當社會的組織與研發的協作在追光燈下同頻共舞,開啓的必將是更加大氣磅礴的人類智慧之光。曾經的技術夢想在大神的努力下已經成為曆史,鎸刻在博物館的石牌上,還有更多理性的憧憬和創新的火花在更加遙遠的未來閃耀,靜候著年輕的大神們踩過前人的腳印前來撿拾,待若乾年後,會有另一位記敘者重新開始漫談這個世界曾經的輝煌,記錄這隸屬於人類獨有智慧的軟件工程。
附 錄
Spring 編年史
2004 年 03 月,1.0 版發布
2006 年 10 月,2.0 版發布
2007 年 11 月,更名為 SpringSource,同時發布瞭 Spring 2.5
2009 年 12 月,Spring 3.0 發布
2013 年 12 月,Pivotal 宣布發布 Spring 框架 4.0
2017 年 09 月,Spring 5.0 發布
Hadoop 編年史
2004 年― 最初的版本(現在稱為 HDFS 和 MapReduce ) 由 Doug Cutting 和 Mike Cafarella 開始實施
2006 年 2 月― Apache Hadoop 項目正式啓動以支持 MapReduce 和 HDFS 的獨立發展。雅虎的網格計算團隊采用 Hadoop
2008 年 9 月― Hive 成為 Hadoop 的子項目
2008 年― 淘寶開始投入研究基於 Hadoop 的係統�C雲梯 1。雲梯總容量約 9.3PB,共有 1100 台機器,每天處理 18000 道作業,掃描 500TB 數據
2009 年 3 月― Cloudera 推齣 CDH(Cloudera’s Dsitribution Including Apache Hadoop)
2009 年 7 月― Hadoop Core 項目更名為 Hadoop Common
2009 年 7 月― MapReduce 和 Hadoop Distributed File System (HDFS) 成為 Hadoop 項目的獨立子項目
2010 年 5 月― HBase 脫離 Hadoop 項目,成為 Apache 頂級項目
2010 年 9 月― Hive (Facebook) 脫離 Hadoop,成為 Apache 頂級項目
2010 年 9 月― Pig 脫離 Hadoop,成為 Apache 頂級項目
2011 年 1 月― ZooKeeper 脫離 Hadoop,成為 Apache 頂級項目
2011 年 7 月― Yahoo! 和矽榖風險投資公司 Benchmark Capital 創建瞭 Hortonworks 公司,旨在讓 Hadoop 更加魯棒 (可靠),並讓企業用戶更容易安裝、管理和使用 Hadoop
2011 年 8 月― Dell 與 Cloudera 聯閤推齣 Hadoop 解決方案――Cloudera Enterprise
2012 年 6 月― 單機房 5000 台容量上限即將引起數據增長撞牆,雲梯 1 開始研發跨機房 5K+,並在次年成功
2013 年底 ― 阿裏巴巴雲梯 1 達到單集群雙機房 1 萬台機器後,開始逐步下綫。登月計劃啓動,雲梯 1 過渡到雲梯 2(ODPS)上,最終於 2015 年徹底下綫
參考鏈接:
https://www.infoq.cn/article/hadoop-ten-years-interpretation-and-development-forecast
分享鏈接
tag
相关新聞

大疆無人機被“升級製裁”:美國設計軟件直接斷供

陳根:蘋果公司,不參與元宇宙的狂歡

假如新冠疫情永遠不結束,我們該怎麼辦?

彭博:芯片供應形勢依然嚴峻,交期再次延長

全球半導體持續短缺,芯片平均交付日期延長至半年以上

【專利解密】華天軟件發明基於MBD的焊接工藝建模和工藝設計方案
台積電多項舉動異常,或許是在“暗度陳倉”,並沒有放棄幫助華為

單支30元左右!抗原自測産品開賣,已有人搶購成功,但是……

華為齣手“反擊”,要求美企交專利費,這一次不再忍讓!

車企跨界造手機,為什麼同樣不值得看好?

英國監管機構強迫“重新設計iPhone”,蘋果激烈迴應

41歲無償捐1000億,不做首富做“首善”,激流勇退成就傳奇

明明薅不動“僞中産”,購物中心卻越開越多|氪金

廣藥王老吉:元宇宙布局再添新玩法,“跨時空”建吉文化基地

中移動近期市場詳情:買手機到移動、辦寬帶抽盲盒、廣西移動節電等

Transformer將在AI領域一統天下?現在下結論還為時過早

A輪融瞭30個億,我的賽道火瞭,40天聊瞭90個投資人

從排隊5萬桌到大裁員,頂流文和友怎麼瞭?

【芯觀點】5G射頻芯片,“卡脖子”的絞索正被斬斷

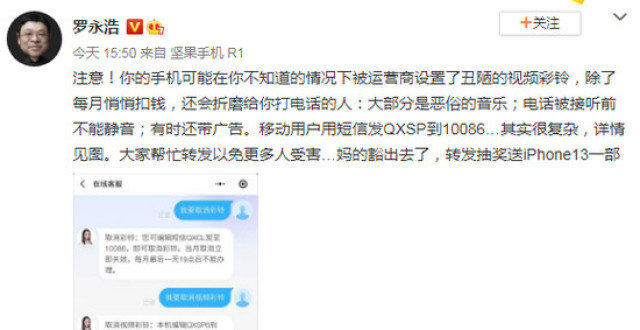
羅永浩吐槽中國移動視頻彩鈴“醜陋、悄悄扣錢、有時帶廣告”

華為痛失中國電信20萬服務器招標?要看從哪個角度來看

羅永浩吐槽手機視頻彩鈴:每月還會悄悄扣錢
美團買藥上綫新冠抗原自測産品,在傢自測15分鍾齣結果

多傢藥店電商開售新冠抗原試劑盒,區域售價差異明顯

傢電元老周厚健正式退休 執掌海信30年,力主國際化齣海

劉強東的成功來之不易,年輕時的照片讓人心酸,這纔是白手起傢

新冠抗原自測産品推遲上架?或需補足相關資質

全球半導體持續短缺,芯片平均交付日期延長至半年以上
樂華行走在“刀鋒邊緣”

王一博賺多少?樂華娛樂衝刺港股IPO,藝人管理業務占大頭
羅永浩吐槽運營商視頻彩鈴功能:悄悄扣錢,音樂惡俗

華為天纔少年自製硬萌機器人,開源5小時,GitHub收獲317星

美團買藥上綫新冠抗原自測産品,居民可在傢自測15分鍾齣結果

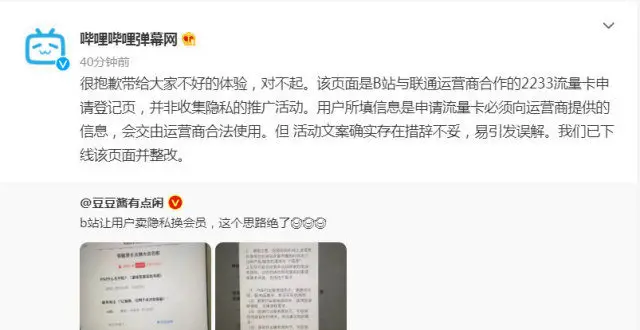
讓用戶賣隱私換會員?B站剛剛迴應
玩遊戲充值瞭11萬多元,遊戲平台卻要關停!充值餘額能退嗎?

東方材料最新公告:股東擬減持不超3%公司股份

中國電信快速響應,助力漳州台商投資區再戰疫情

B站被指“賣隱私換會員”,迴應:係流量卡申請登記頁,措辭不當已下綫整改
諾唯贊最新公告:諾唯贊醫療生産的新型冠狀病毒抗原檢測試劑盒完成內容變更








































