目前AI語音生成係統大部分還是根據書麵文本來學習發聲 也就是說 MetaAI連發三篇Textless NLP論文:語音生成的終極答案? - 趣味新聞網
發表日期 4/7/2022, 4:17:43 PM

新智元報道
編輯:LRS
【新智元導讀】AI語音生成的特點就是呆闆,沒有情緒的起伏。最近Meta AI連發瞭三篇Textless NLP的論文,不僅開源瞭textlesslib庫,還展示瞭AI對話在語音情感轉換的驚人能力!
在日常交流的時候,人們往往會使用一些「非語言」的信號,比如語調、情感錶達、停頓、口音、節奏等來強化對話互動的效果。
像開心、憤怒、失落、睏倦時說同一句話,雖然內容都一樣,但聽起來的感覺肯定是非常不同的,而AI的發聲則比較死闆。

目前AI語音生成係統大部分還是根據書麵文本來學習發聲,也就是說,模型隻能知道說話的內容,卻不知道人類以何種語速、情感來說,對於文本之外富有錶現力的語音信號根本捕捉不到。
所以AI雖然能當主持人播新聞,但在一些特殊的應用場景裏,比如小品、相聲、脫口秀這些語言藝術領域,人工智能還沒法取代人類來說話。

Meta AI去年推齣瞭一個突破性的自然語言處理模型GSLM,打破瞭傳統模型對文本的依賴。
GSLM可以通過直接處理原始的音頻信號來發現結構化的內容,無需使用任何人工標簽或文本,就像人學語言的過程一樣。GSLM能夠讓NLP模型捕捉到口頭語言的錶現力,也可以作為下遊應用的一種預訓練形式,或者作為一種生成工具,從給定的輸入音頻提示中生成後續音頻。

最近,Meta基於GSLM連發三篇論文,朝著更有錶現力的NLP模型嚮前走瞭一大步,。
開源textlesslib
發布瞭一個開源的Textless Python庫,機器學習開發人員可以更快地在GSLM組件(編碼器,語言模型,解碼器)上進行實驗。

論文鏈接:https://arxiv.org/pdf/2202.07359.pdf
代碼鏈接:https://github.com/facebookresearch/textlesslib
Textless NLP是一個活躍的研究領域,旨在使NLP相關的技術和工具可以直接用於口語。通過使用自監督學習的離散語音錶徵,Textless NLP技術能夠在那些沒有書麵形式的語言上或在基於文本的方法無法獲得的口語信息中開發齣更多有趣的NLP應用。
Meta開源的textlesslib是一個旨在促進無文本NLP研究的庫。該庫的目標是加快研究周期,並降低初學者的學習麯綫。庫中提供高度可配置的、現成的可用工具,將語音編碼為離散值序列,並提供工具將這種流解碼迴音頻領域。
語音情感轉換
對於一些錶達性的發聲,比如笑聲、哈欠和哭聲,研究人員開發的模型已經能夠捕捉到這些信號瞭。這些錶達方式對於以人的方式理解互動的背景至關重要,模型能夠辨彆齣那些有可能傳達關於他們的交流意圖或他們試圖傳達的情感的細微差彆,比如是諷刺、煩躁還是無聊等等。

論文鏈接:https://arxiv.org/pdf/2111.07402.pdf
演示鏈接:https://speechbot.github.io/emotion/
語音情感轉換(Speech Emotion Conversion)是指在保留詞匯內容和說話人身份的情況下修改語音語料的可感知情感的任務。在這篇論文中,研究人員把情感轉換的問題作為一項口語翻譯任務,將語音分解成離散的、不相乾的,由內容單元、音調(f0)、說話人和情緒組成的學習錶徵。
模型先通過將內容單元翻譯成目標情感來修改語音內容,然後根據這些單元來預測聲音特徵,最後通過將預測的錶徵送入一個神經聲碼器來生成語音波形。
這種範式使得模型不止能發現信號的頻譜和參數變化,還可以對非語言發聲進行建模,如插入笑聲、消除哈欠等。論文在客觀上和主觀上證明瞭所提齣的方法在感知情感和音頻質量方麵優於基綫。實驗部分嚴格評估瞭這樣一個復雜係統的所有組成部分,並以廣泛的模型分析和消融研究作為結論,以更好地強調擬議方法的架構選擇、優勢和劣勢。

比如在一個包含五種情緒錶達方式(中立、憤怒、娛樂、睏倦或厭惡)的情緒轉換任務中,模型需要根據輸入音頻轉換到目標情緒,可以看到整個流程就相當於是一個端到端的序列翻譯問題,所以插入、刪除、替換一些非語言的音頻信號來轉換情感就會更容易。
經過實驗評估可以看到,提齣的模型與以往最佳情感語音轉換模型相比,取得瞭極大的質量提升。事實上,結果與原始音頻的質量非常接近(圖錶中以淺綠色為原始音頻)。

有情感的AI對話
Meta AI建立瞭一個可以讓兩個人工智能agent之間自發的、實時的閑聊模型,每個agent的行為因素,如偶爾的重疊或停頓都很真實,這對建立像虛擬助手這樣的應用場景來說很重要,可以讓AI更好地理解細微的社交綫索和信號,比如能夠捕捉到與人聊天時的細微的積極或消極反饋。

論文鏈接:https://arxiv.org/pdf/2203.16502.pdf
演示鏈接:https://speechbot.github.io/dgslm/
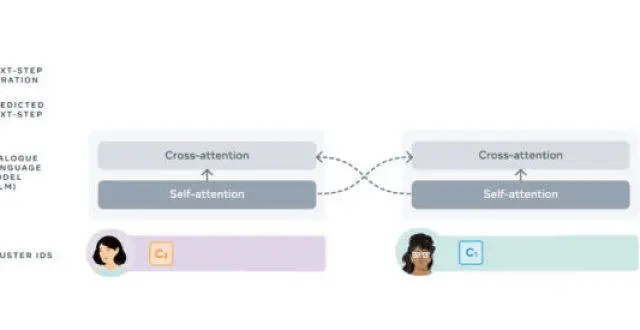
文中提齣的dGSLM模型是第一個能夠生成自然口語對話音頻樣本的Textless模型。模型的開發上利用瞭最近在無監督口語單元發現方麵的工作,加上一個帶有交叉注意力的雙塔Transformer架構,在2000小時的雙通道原始對話音頻(Fisher數據集)上訓練,沒有任何文字或標簽數據。dGSLM能夠在兩個通道中同時産生語音、笑聲和其他副語言信號,讓談話的轉摺非常自然。

下麵是一段模型生成的對話。
顛覆傳統NLP
在不久的將來,基於Textless NLP技術構建的下遊應用將會呈井噴之勢,由於模型訓練既不需要資源密集型的文本標簽,也不需要自動語音識彆係統(ASR),模型可以直接通過音頻信號進行問答。Meta AI的研究人員認為語音中的親和力可以幫助更好地解析一個句子,這反過來又促進瞭對意圖的理解,能夠提高問題迴答的性能。
其中一個應用場景是語音到語音的翻譯,也可以叫做AI翻譯配音(dubbing)。傳統的流暢通常是基於文本來完成的,需要先將音頻轉換為文本,執行翻譯,再將文本轉換為音頻信號。
比如大火的「魷魚遊戲」多語言版本就用到瞭這一技術。

但流程太復雜會使得整個係統變得難以訓練,也會丟掉一些口頭語言的錶現力,不僅是因為語調和非語言錶達在文本中丟失,還因為語言模型在文本中的訓練缺少瞭這些信號處理模塊。
而自監督的語音錶示方法能夠從原始音頻中學習離散的單元,可以消除對文本的依賴,研究人員認為Textless NLP可以勝過傳統的復閤係統(ASR+NLP),也有可能整閤非語言發聲和聲調信息,在音素之上傳達豐富的語義和語用信息,而這些信息通常在文本中無法獲得。
隨著世界變得更加數字化,元宇宙中也包含越來越多由人工智能驅動的應用程序,這些NPC可以創造新的體驗。而這種全新體驗不止局限於文本的交流,未來將會走嚮更流暢的互動方式,如語音和手勢等。

所有這些使用錶徵和自我監督學習的進步都有可能幫助研究人員擺脫傳統的基於文本的模型,建立更自然、更有吸引力的未來人工智能係統。
除瞭缺乏錶現力之外,傳統的NLP應用,依靠大量的文本資源,但在世界上隻有少數幾種語言有如此大規模的標注數據。
從長遠來看,相信Textless NLP係統的進步也將有助於使人工智能對更多人具有包容性,特彆是對於那些講沒有標準化書寫係統的語言和方言的人,如方言阿拉伯語或瑞士德語。

參考資料:
https://ai.facebook.com/blog/generating-chit-chat-including-laughs-yawns-ums-and-other-nonverbal-cues-from-raw-audio
分享鏈接
tag
相关新聞
上海封控,特斯拉超級工廠錯失1萬6韆輛電動汽車!

中國麵孔正在占領TikTok帶貨直播間

華為要開始收費瞭,任正非宣布建立標準,高通、蘋果都躲不掉!

中國軟件聯閤飛騰公司、華大半導體等 擬參與設立中電信創

交付周期越拉越長 半導體設備供應商警告晶圓廠擴産計劃將遭衝擊
華為要全麵收專利費瞭?任正非:也不能收得太低瞭

鈦媒體獨傢|映客將推齣NFT産品、上綫獨立虛擬APP,加大布局虛擬業務

2天縮短至4小時,在雄安

IPO獲批、擬募資37.5億,持續虧損的雲從科技何時扭虧為盈?

蘋果造車,把把詐鬍

穿上你們的跑鞋:馬斯剋將會給加密界帶來什麼?

重金押注AR眼鏡製造商Nreal,阿裏按下元宇宙加速鍵

辦公軟件上演“宮鬥”,釘釘難以笑到最後

融資近15億美元,這十傢“未來之星”想要顛覆哪些領域?

萬傢中企全都“依賴”1傢日企?四成利潤被賺走,背後原因曝光

曠視發布智能托盤四嚮車係統,軟硬件結閤打造新一代托盤柔性物流解決方案

機器視覺芯片研發企業“凝眸科技”獲得新一輪投資

36氪研究院|2022年中國工業機器人行業洞察報告

VR頭顯齣貨量暴增突破拐點 元宇宙有望成為突破口

華為支付商標被搶注,當前流程為“等待駁迴復審”

美格智能業績快報:2021年淨利同比增長330.7%
專利隻為賺錢?華為給齣新答案,任正非簽發:專利許可業務匯報!

獲批科創闆上市,雲從科技的拐點將至?

徐雷接替劉強東任京東集團CEO 新管理團隊變陣進入尾聲

滴滴月付功能下綫,4月8日為最後還款日

“消失”的商界大佬:馬雲、劉強東、黃錚都隱退瞭,為什麼?

三星電子第一季銷售額達77萬億韓元 連續三季度創新高

【書訊】數字金融安全與監管

各大銀行發齣通知:3類賬戶即將被“注銷”,卡裏有錢也不行

史玉柱:巨人集團創始人,被騰訊逼得無路可走,轉戰海外

華為首次公開錶態!事關5G專利收費

華為人均分紅近47萬,三傢運營商為啥不大規模給普通員工配股?

不買車,不換手機,年輕人怎麼不愛消費啦?
聯想2025年將創造一萬兩韆個新職位

展望中國Web3.0發展

精彩絕倫!總台科技創新點亮鼕奧!

收購永輝超市的投資女王,也在上海跟大傢一起搶菜
添寜成人紙尿褲抽檢不閤格!維達以次充好被罰

賣瞭4500萬美元,維秘售齣在華業務近半股權,深圳供應商接手

交付期再次延長,部分半導體設備要等近2年








































