作者 | 李煌東1當 Kubernetes 成為雲原生事實標準 可觀測性挑戰隨之而來當前 深度解密基於 eBPF的Kubernetes 問題排查全景圖 - 趣味新聞網

發表日期 3/16/2022, 4:29:13 PM
作者 | 李煌東
1
當 Kubernetes 成為雲原生事實標準,可觀測性挑戰隨之而來
當前,雲原生技術以容器技術為基礎,通過標準可擴展的調度、網絡、存儲、容器運行時接口來提供基礎設施。同時,通過標準可擴展的聲明式資源和控製器來提供運維能力,兩層標準化推動瞭開發與運維關注點分離,各領域進一步提升規模化和專業化,達到成本、效率、穩定性的全麵優化。
在這樣的大技術背景下,越來越多的公司引入瞭雲原生技術來開發、運維業務應用。正因為雲原生技術帶來瞭越發紛繁復雜的可能性,業務應用齣現瞭微服務眾多、多語言開發、多通信協議的鮮明特徵。同時,雲原生技術本身將復雜度下移,給可觀測性帶來瞭更多挑戰:
1、混沌的微服務架構,多語言和多網絡協議混雜
業務架構因為分工問題,容易齣現服務數量多,調用協議和關係非常復雜的現象,導緻的常見問題包括:
無法準確清晰瞭解、掌控全局的係統運行架構;
無法迴答應用之間的連通性是否正確;
多語言、多網絡調用協議帶來埋點成本呈綫性增長,且重復埋點 ROI 低,開發一般將這類需求優先級降低,但可觀測數據又不得不采集。
2、下沉的基礎設施能力屏蔽實現細節,問題定界越發睏難
基礎設施能力繼續下沉,開發和運維關注點繼續分離,分層後彼此屏蔽瞭實現細節,數據方麵不好關聯瞭,齣現問題後不能迅速地定界問題齣現在哪一層。開發同學隻關注應用是否正常工作,並不關心底層基礎設施細節,齣現問題後需要運維同學協同排查問題。運維同學在問題排查過程中,需要開發同學提供足夠的上下遊來推進排查,否則隻拿到“某某應用延遲高”這麼籠統的錶述,這很難有進一步結果。所以,開發同學和運維同學之間需要共同語言來提高溝通效率,Kubernetes 的 Label、Namespace 等概念非常適閤用來構建上下文信息。
3、繁多監測係統,造成監測界麵不一緻
復雜係統帶來的一個嚴重副作用就是監測係統繁多。數據鏈路不關聯、不統一,監測界麵體驗不一緻。很多運維同學或許大多都有過這樣的體驗:定位問題時瀏覽器打開幾十個窗口,在 Grafana、控製台、日誌等各種工具之間來迴切換,不僅非常耗時巨大,且大腦能處理的信息有限,問題定位效率低下。如果有統一的可觀測性界麵,數據和信息得到有效地組織,減少注意力分散和頁麵切換,來提高問題定位效率,把寶貴時間投入到業務邏輯的構建上去。
2
解決思路與技術方案
為瞭解決上述問題,我們需要使用一種支持多語言,多通信協議的技術,並在産品層麵盡可能覆蓋軟件棧端到端的可觀測性需求,通過調研,我們提齣一種立足於容器界麵和底層操作係統,嚮上關聯應用性能監測的可觀測性解決思路。
要采集容器、節點運行環境、應用、網絡各個維度的數據挑戰非常大,雲原生社區針對不同需求給齣瞭 cAdvisor、node exporter、kube-state-metics 等多種方式,但仍然無法滿足全部需求。維護眾多采集器的成本也不容小覷,引發的一個思考是能否有一種對應用無侵入的、支持動態擴展的數據采集方案?目前最好的答案是 eBPF。
數據采集(eBPF 超能力)
eBPF 的超能力
eBPF 相當於在內核中構建瞭一個執行引擎,通過內核調用將這段程序 attach 到某個內核事件上,實現監聽內核事件。有瞭事件我們就能進一步做協議推導,篩選齣感興趣的協議,對事件進一步處理後放到 ringbuffer 或者 eBPF 自帶的數據結構 Map 中,供用戶態進程讀取。用戶態進程讀取這些數據後,進一步關聯 Kubernetes 元數據後推送到存儲端。這是整體處理過程。
eBPF 的超能力體現在能訂閱各種內核事件,如文件讀寫、網絡流量等,運行在 Kubernetes 中的容器或者 Pod 裏的一切行為都是通過內核係統調用來實現的,內核知道機器上所有進程中發生的所有事情,所以內核幾乎是可觀測性的最佳觀測點,這也是我們為什麼選擇 eBPF 的原因。另一個在內核上做監測的好處是應用不需要變更,也不需要重新編譯內核,做到瞭真正意義上的無侵入。當集群裏有幾十上百個應用的時候,無侵入的解決方案會幫上大忙。
但作為新技術,人們對 eBPF 也存在些許擔憂,比如安全性與探針性能。為瞭充分保證內核運行時的安全性,eBPF 代碼進行瞭諸多限製,如最大堆棧空間當前為 512、最大指令數為 100 萬。與此同時,針對性能擔憂,eBPF 探針控製在大約在 1% 左右。其高性能主要體現在內核中處理數據,減少數據在內核態和用戶態之間的拷貝。簡單說就是數據在內核裏算好瞭再給用戶進程,比如一個 Gauge 值,以往的做法是將原始數據拷貝到用戶進程再計算。
可編程的執行引擎天然適閤可觀測性
可觀測性工程通過幫助用戶更好的理解係統內部狀態來消除知識盲區和及時消除係統性風險。eBPF 在可觀測性方麵有何威力呢?
以應用異常為例,當發現應用有異常後,解決問題過程中發現缺少應用層麵可觀測性,這時候通過埋點、測試、上綫補充瞭應用可觀測性,具體的問題得到瞭解決,但往往治標不治本,下一次彆的地方有問題,又需要走同樣的流程,另外多語言、多協議讓埋點的成本更高。更好的做法是用無侵入方式去解決,以避免需要觀測時沒有數據。
eBPF 執行引擎可通過動態加載執行 eBPF 腳本來采集可觀測性數據,舉個具體例子,假設原本的 K8S 係統並沒有做進程相關的監測,有一天發現瞭某個惡意進程(如挖礦程序)在瘋狂地占用 CPU,這時候我們會發現這類惡意的進程創建應該被監測起來,這時候我們可以通過集成開源的進程事件檢測庫來是實現,但這往往需要打包、測試、發布這一整套流程,全部走完可能一個月就過去瞭。
相比之下,eBPF 的方式顯得更為高效快捷,由於 eBPF 支持動態地加載到內核監聽進程創建的事件,所以我們可以將 eBPF 腳本抽象成一個子模塊,采集客戶端每次隻需要加載這個子模塊裏的腳本完成數據采集,再通過統一的數據通道將數據推送到後端。這樣我們就省去瞭改代碼、打包、測試、發布的繁瑣流程,通過無侵入的方式動態地實現瞭進程監測這樣的需求。所以,eBPF 可編程的執行引擎非常適閤用來將增強可觀測性,將豐富的內核數據采集上來,通過關聯業務應用,方便問題排查。
3
從監測係統到可觀測性
隨著雲原生浪潮,可觀測性概念正深入人心。但仍離不開日誌、指標、鏈路這三類可觀測領域的數據基石。做過運維或 SRE 的同學經常遇到這樣的問題:半夜被拉到應急群裏,披頭蓋地地被質問為什麼數據庫不工作瞭,在沒有上下文的情況下,無法立刻抓住問題核心。我們認為好的可觀測性平台應該幫助用戶很好地反饋上下文,就像 Datadog 的 CEO 說的那樣: 監測工具不是功能越多功能越好,而是要思考怎樣在不同團隊和成員之間架起橋梁,盡可能把信息放在同一個頁麵中(to bridge the gap between the teams and get everything on the same page)。
因此,在可觀測性平台産品設計上需要以指標、鏈路、日誌為基本,嚮外集成阿裏雲自傢的各類雲服務,同時也支持開源産品數據接入,將關鍵上下文信息關聯起來,方便不同背景的工程師理解,進而加速問題排查。信息沒有有效地組織就會産生理解成本,信息粒度上以事件 ->指標 ->鏈路 ->日誌由粗到細地組織到一個頁麵中,方便下鑽,不需要多個係統來迴跳轉,從而提供一緻體驗。
那麼具體怎麼關聯呢?信息怎麼組織呢?主要從兩方麵來看:
1、端到端:展開說就是應用到應用,服務到服務,Kubernetes 的標準化和關注點分離,各自開發運維各自關注各自領域,那麼端到端的監測很多時候成瞭”三不管“區域,齣現問題的時候很難排查鏈路上哪個環節齣瞭問題。因此從端到端的角度來看,兩者調用關係是關聯的基礎,因為係統調用纔産生瞭聯係。通過 eBPF 技術非常方便地以無侵入的方式采集網絡調用,進而將調用解析成我們熟知的應用協議,如 HTTP、GRPC、MySQL 等,最後將拓撲關係構建起來,形成一張清晰的服務拓撲後方便快速定位問題,如下圖中網關 ->Java 應用 ->Python 應用 ->雲服務的完整鏈路中,任意一環齣現延時,在服務拓撲中應能一眼看齣問題所在。這是第一個管綫點端到端。
2、自頂嚮下全棧關聯:以 Pod 為媒介,Kubernetes 層麵關聯 Workload、Service 等對象,基礎設施層麵可以關聯節點、存儲設備、網絡等,應用層麵關聯日誌、調用鏈路等。
接下來介紹下 Kubernetes 監測的核心功能。
永不過時的黃金指標
黃金指標是用來 監測 係統性能和狀態的最小集閤 。黃金指標有兩個好處:一,直接瞭然地錶達瞭係統是否正常對外服務。二,能快速評估對用戶的影響或事態的嚴重性,能大量節省 SRE 或研發的時間,想象下如果我們取 CPU 使用率作為黃金指標,那麼 SRE 或研發將會奔於疲命,因為 CPU 使用率高可能並不會造成多大的影響。
Kubernetes 監測支持這些指標:
請求數 /QPS
響應時間及分位數(P50、P90、P95、P99)
錯誤數
慢調用數
如下圖所示:
全局視角的服務拓撲
諸葛亮曾言“不謀全局者,不足謀一域 ”。隨著當下技術架構、部署架構的復雜度越來越高,發生問題後定位問題變得越來越棘手,進而導緻 MTTR 越來越高。另一個影響是對影響麵的分析帶來非常大的挑戰,通常會造成顧此失彼。因此,有一張像地圖一樣的拓撲大圖非常必要。全局拓撲具有以下特點:
係統架構感知:係統架構圖是程序員瞭解一個新係統的重要參考,當拿到一個係統,起碼需要知曉流量入口在哪裏,有哪些核心模塊,依賴瞭哪些內部外部組件等。在異常定位過程中,有一張全局架構的圖對異常定位進程有非常大推動作用。
依賴分析:有一些問題是齣現在下遊依賴,如果這個依賴不是自己團隊維護就會比較麻煩,當自己係統和下遊係統沒有足夠的可觀測性的時候就更麻煩瞭,這種情況下就很難跟依賴的維護者講清楚問題。在我們的拓撲中,通過將黃金指標的上下遊用調用關係連起來,形成瞭一張調用圖。邊作為依賴的可視化,能查看對應調用的黃金信號。有瞭黃金信號就能快速地分析下遊依賴是否存在問題。
分布式 Tracing 助力根因定位
協議 Trace 同樣是無入侵、語言無關的。如果請求內容中存在分布式鏈路 TraceID,能自動識彆齣來,方便進一步下鑽到鏈路追蹤。應用層協議的請求、響應信息有助於對請求內容、返迴碼進行分析,從而知道具體哪個接口有問題。如需查看代碼級彆或請求界彆的詳情,可點擊 Trace ID 下鑽到鏈路追蹤分析查看。
開箱即用的告警功能
開箱即用的告警模闆,各個不同層次全覆蓋,不需要手動配置告警,將大規模 Kubernetes 運維經驗融入到告警模闆裏麵,精心設計的告警規則加上智能降噪和去重,我們能夠做到一旦告警就是有效的告警,並且告警裏麵帶有關聯信息,可以快速定位到異常實體。告警規則全棧覆蓋的好處是能及時、主動地將高風險事件報給用戶,用戶通過排查定位、解決告警、事後復盤、麵嚮失敗設計等一係列手段,最終逐步達成更好的係統穩定性。
網絡性能監測
網絡性能問題在 Kubernetes 環境中很常見,由於 TCP 底層機製屏蔽瞭網絡傳輸的復雜性,應用層對此是無感的,這對生産環境定位丟包率高、重傳率高這種問題帶來一定的麻煩。Kubernetes 監測支持瞭 RTT、重傳 & 丟包、TCP 連接信息來錶徵網絡狀況,下麵以 RTT 為例,支持從命名空間、節點、容器、Pod、服務、工作負載這幾個維度來看網絡性能,支持以下各種網絡問題的定位:
負載均衡無法訪問某個 Pod,這個 Pod 上的流量為 0,需要確定是否這個 Pod 網絡有問題,還是負載均衡配置有問題;
某個節點上的應用似乎性能都很差,需要確定是否節點網絡有問題,通過對彆的節點網絡來達到;
鏈路上齣現丟包,但不確定發生在那一層,可以通過節點、Pod、容器這樣的順序來排查。
4
Kubernetes 可觀測性全景視角
有瞭上述産品能力,基於阿裏巴巴在容器、Kubernetes 方麵有著豐富且極具深度的實踐,我們將這些寶貴生産實踐歸納、轉化成産品能力,以幫助用戶更有效、更快捷地定位生産環境問題。使用這個排查全景圖可以通過以下方法:
大體結構上是以服務和 Deployment(應用)為入口,大多數開發隻需要關注這一層就行瞭。重點關注服務和應用是否錯慢,服務是否連通,副本數是否符閤預期等
再往下一層是提供真正工作負載能力的 Pod。Pod 重點關注是否有錯慢請求,是否健康,資源是否充裕,下遊依賴是否健康等
最底下一層是節點,節點為 Pod 和服務提供運行環境和資源。重點關注節點是否健康,是否處於可調度狀態,資源是否充裕等。
常見問題排查
網絡問題
網絡是 Kubernetes 中最棘手、最常見的問題,因為以下幾個原因給我們定位生産環境網絡問題帶來麻煩:
Kubernetes 的網絡架構復雜度高,節點、Pod、容器、服務、VPC 交相輝映,簡直能讓你眼花繚亂;
網絡問題排查需要一定的專業知識,大多數對網絡問題都有種天生的恐懼;
分布式 8 大謬誤告訴我們網絡不是穩定的、網絡拓撲也不一成不變的、延時不可忽視,造成瞭端到端之間的網絡拓撲不確定性。
Kubernetes 環境下場景的網絡問題有:
conntrack 記錄滿問題;
IP 衝突;
CoreDNS 解析慢、解析失敗;
節點沒開外網。(對,你沒聽錯);
服務訪問不通;
配置問題(LoadBalance 配置、路由配置、device 配置、網卡配置);
網絡中斷造成整個服務不可用。
網絡問題韆韆萬萬,但萬變不離其宗的是網絡有其錶徵其是否正常運行的”黃金指標“:
網絡流量和帶寬;
丟包數(率)和重傳數(率);
RTT。
下麵的示例展示瞭因網絡問題導緻的慢調用問題。從 gateway 來看發生瞭慢調用,查看拓撲發現調下遊 product 的 RT 比較高,但是 product 本身的黃金指標來看 product 本身服務並沒有問題,進一步查看兩者之間的網絡狀況,發現 RTT 和重傳都比較高,說明網絡性能惡化瞭,導緻瞭整體的網絡傳輸變慢,TCP 重傳機製掩蓋瞭這個事實,在應用層麵感知不到,日誌也沒法看齣問題所在。這時候網絡的黃金指標有助於定界齣問題,從而加速瞭問題的排查。
節點問題
Kubernetes 做瞭大量工作,盡可能確保提供給工作負載和服務的節點是正常的,節點控製器 7x24 小時地檢查節點的狀態,發現影響節點正常運行的問題後,將節點置為 NotReady 或不可調度,通過 kubelet 把業務 Pod 從問題節點中驅逐齣去。這是 Kubernetes 的第一道防綫,第二道防綫是雲廠商針對節點高頻異常場景設計的節點自愈組件,如阿裏雲的 node repairer:發現問題節點後,執行排水驅逐、置換機器,從而做到自動化地保障業務正常運行。即便如此,節點在長期使用過程中不可避免地會産生各種奇奇怪怪的問題,定位起來比較費時耗力。常見問題分類和級彆:
以一個 CPU 打滿為例:
1、節點狀態 OK,CPU 使用率超過瞭 90%
2、查看對應的 CPU 的三元組:使用率、TopN、時序圖,首先每個核的使用率都很高,進而導緻整體 CPU 使用高;接下來我們自然要知道誰在瘋狂地使用 CPU,從 TopN 列錶來看有個 Pod 一枝獨秀地占用 CPU;最後我們得確認下 CPU 飆高是什麼時候開始的。
服務響應慢
造成服務響應非常多,場景可能的原因有代碼設計問題、網絡問題、資源競爭問題、依賴服務慢等原因。在復雜的 Kubernetes 環境下,定位慢調用可以從兩個方案去入手:首先,應用自身是否慢;其次,下遊或網絡是否慢;最後檢查下資源的使用情況。如下圖所示,Kubernetes 監測分彆從橫嚮和縱嚮來分析服務性能:
橫嚮:主要是端到端層麵來看,首先看自己服務的黃金指標是否有問題,再逐步看下遊的網絡指標。注意如果從客戶端來看調用下遊耗時高,但從下遊本身的黃金指標來看是正常的,這時候非常有可能是網絡問題或者操作係統層麵的問題,此時可以用網絡性能指標(流量、丟包、重傳、RTT 等)來確定。
縱嚮:確定應用本身對外的延時高瞭,下一步就是確定具體哪個原因瞭,確定哪一步 / 哪個方法慢可以用火焰圖來看。如果代碼沒有問題,那麼可能執行代碼的環境是有問題的,這時可以查看係統的 CPU/Memory 等資源是否有問題來做進一步排查。
下麵舉個 SQL 慢查詢的例子(如下圖)。在這個例子中網關調用 product 服務,product 服務依賴瞭 MySQL 服務,逐步查看鏈路上的黃金指標,最終發現 product 執行瞭一條特彆復雜的 SQL,關聯瞭多張錶,導緻 MySQL 服務響應慢。MySQL 協議基於 TCP 之上的,我們的 eBPF 探針識彆到 MySQL 協議後,組裝、還原瞭 MySQL 協議內容,任何語言執行的 SQL 語句都能采集到。
第二個例子是應用本身慢的例子,這時候自然會問具體哪一步、哪個函數造成瞭慢,ARMS 應用監控支持的火焰圖通過對 CPU 耗時定期采樣(如下圖),幫助快速定位到代碼級彆問題。
5
應用 /Pod 狀態問題
Pod 負責管理容器,容器是真正執行業務邏輯的載體。同時 Pod 是 Kubernetes 調度的最小單元,所以 Pod 同時擁有瞭業務和基礎設施的復雜度,需要結閤著日誌、鏈路、係統指標、下遊服務指標綜閤來看。Pod 流量問題是生産環境高頻問題,比如數據庫流量陡增,當環境中有成韆上萬個 Pod 時,排查流量主要來自哪個 Pod 就顯得特彆睏難。
接下來我們看一個典型的案例:下遊服務在發布過程中灰度瞭一個 Pod,該 Pod 因代碼原因響應非常慢,導緻上遊都超時瞭。之所以能做到 Pod 級彆的可觀測,是因為我們用 ebpf 的技術來采集 Pod 的流量、黃金指標,因此可以通過拓撲、大盤的方式方便地查看 Pod 與 Pod、Pod 與服務、Pod 與外部的流量。
6
總結
通過 eBPF 無侵入地采集多語言、多網絡協議的黃金指標 / 網絡指標 /Trace,通過關聯 Kubernetes 對象、應用、雲服務等各種上下文,同時在需要進一步下鑽的時候提供專業化的監測工具(如火焰圖),實現瞭 Kubernetes 環境下的一站式可觀測性平台。
分享鏈接
tag
相关新聞
315權益日:“幸運”大牌和巨頭,“擋槍”作坊和“小弟”?

從遊戲直播效果化說起,數字營銷將迎來新變革?

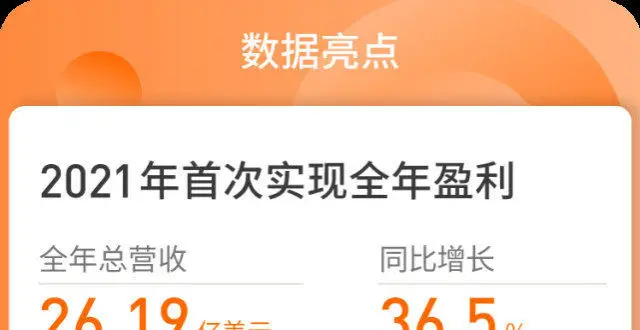
歡聚發布21Q4及全年財報:全球業務扭虧為盈,首次實現年盈利
微信狀態最新上綫“抗疫”
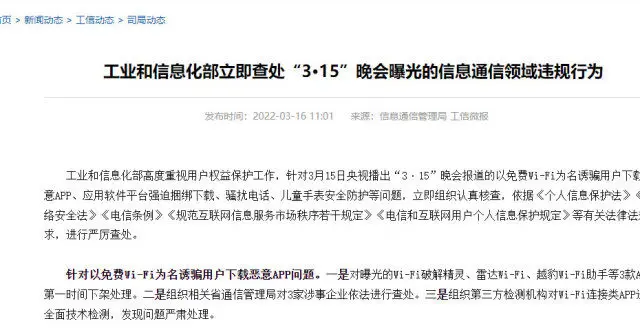
下載軟件捆綁流氓軟件?315曝光高速下載器幕後黑手

工信部:第一時間下架處理Wi-Fi破解精靈等3款App
碳化矽賽道技術黑馬忱芯科技獲近億元Pre-A輪融資

印度電信部長:5G已經沒戲瞭,把華為設備給拆瞭,6G再彎道超車

淘寶微信抖音上綫算法關閉鍵 用戶可自行關閉個性化推薦
歡聚首次實現全年盈利,BIGO成增收引擎,全球化戰略延續

微軟將對軍用HoloLens進行負麵測試

微信、抖音、淘寶、微博等頭部 App 已允許用戶一鍵關閉“個性化推薦”

馬雲承諾每年在沙漠種1億棵樹,5年過去瞭,這些樹現在如何瞭?

不發貨 不退款 全球奢侈品平台寺庫陷誠信危機

全球頂級富豪的象徵,號稱“無所不能”,黑卡究竟有多“牛”?

微信淘寶等App已上綫算法關閉鍵

虛擬藝人A-SOUL助力,樂華娛樂收入同比上漲79.6%

拿下北京8000輛公交車,董明珠再獲成功?劉強東和王健林樂開花

芯片“明星公司”頻現人事變動 爭搶稀缺行業人纔堪比“拍賣會”

宜通世紀最新公告:中標2.79億元項目

趕在深圳東莞疫情防控升級前 彩電龍頭通宵運料搶齣貨

Win11居然內置廣告!微軟迴應:內部試驗功能,不小心推送瞭

國産放療設備占15%,瞄準痛點解決臨床痛點問題

2022年會是激光雷達規模化應用的元年嗎?

中國信保被罰51萬元:準備金計提錯誤、保險費率執行管控不嚴格

精鋒單孔手術機器人SP1000完成婦科臨床試驗,為中國首例

王思聰不用直播吃翔瞭?怪獸充電上市即巔峰,經營同比由盈轉虧

長盈通超四成營收來自關聯方 核心高管曾供職競爭對手存隱患


消息稱立訊精密正為蘋果AirPods提供係統級芯片封裝服務

中美日等國傢的E級超算統統推遲麵世,背後到底發生瞭什麼事情?

涉及直播帶貨、老壇酸菜、校園抽奬等,今年的315晚會曝光瞭這些問題

反擊正式打響,203億賠償一分都不能少,英美“去華為”計劃失敗

專業辦公本該有的樣子:免費轉寫堪比速記,手寫比在紙上舒服

美光CEO預計芯片短缺將持續到2023年

蘋果變成“水果訟棍”

直擊疫情下深圳生鮮運送:淩晨配貨日齣到店,揀貨量增五六倍

“身份證”咋就成瞭最熱概念股?三類玩傢火透半邊天

簡曆買賣調查:用虛假招聘采集大量信息,10萬條賣500元

上海“在綫新經濟”進入“蝶變期”








































