機器之心報道編輯:澤南、蛋醬它們都將成為元宇宙時代的殺手級 APP?Meta 正在緻力於通過語音生成元宇宙世界的人工智能研究 還有很多神奇的技術。首席執行官馬剋 ・ 紮剋伯格本周三錶示 紮剋伯格曝光Meta的小目標:AI自動生成元宇宙,實時翻譯所有語言 - 趣味新聞網

發表日期 2/24/2022, 12:51:08 PM
機器之心報道
編輯:澤南、蛋醬
它們都將成為元宇宙時代的殺手級 APP?
Meta 正在緻力於通過語音生成元宇宙世界的人工智能研究,還有很多神奇的技術。首席執行官馬剋 ・ 紮剋伯格本周三錶示,該公司正在研究改善人們與語音助手交流順暢程度,以及在不同語言之間進行翻譯的方式。
最近一段時間,紮剋伯格正帶領臉書 all in 元宇宙,並預測在未來人們可以在虛擬世界中工作、社交和娛樂,這一環境將最終代替互聯網。
至於元宇宙、虛擬現實是如何能夠讓人沉浸其中的,「解鎖這些進步的關鍵是人工智能,」紮剋伯格說道。
讓做飯看起來和《模擬人生》裏一樣簡單。
Meta 正在研究一類新的生成 AI 模型,該模型將允許人們描述一個世界,人工智能自動生成它的各個方麵。在昨天的演示中,紮剋伯格展示瞭一個名為 Builder Bot 的 AI 概念,人們在元宇宙的島嶼上以 3D 化身的形式齣現,並發齣語音命令創建海灘,係統可以遵從人們的命令隨時更改天氣,添加樹木甚至野餐毯。
海灘、島嶼、椰子樹,想要什麼場景,跟 AI 說一聲就有瞭 。
「隨著我們進一步推動這項技術,你將可以創造齣夢想中的世界,用你的聲音與他人探索和分享經驗。」不過紮剋伯格沒有為這些計劃設定時間錶,也沒有提供有關 Builder Bot 工作原理的更多細節。
另一部分是語音識彆技術,Meta 錶示正在研究人工智能,讓人們能夠與語音助手進行更自然的對話,這是讓人們在元宇宙中與人工智能順暢交流邁齣的一步。紮剋伯格錶示,該公司的 CAIRaoke 項目是「用於構建設備助手的完全端到端的神經模型」。
在紮剋伯格的展示中,CAIRaoke 在一個「非常實用」的傢庭場景中起到瞭作用:人在煮燉菜時,語音助手會發齣提示,警告說鹽已經加到鍋裏瞭。AI 助理還注意到鹽放少瞭,於是提示要放更多。
在 Meta 隨後發布的博客中,研究者們對 CAIRaoke 背後的技術進行瞭解讀。人工智能語音助手的傳統方法需要四組輸入和輸齣――管道的每層(NLU、DST、DP 和 NLG)各一組。它還需要為每一層的輸入和輸齣定義標準。例如,對於 NLU,傳統的會話 AI 係統需要定義的本體(例如,各種意圖和實體)。
但 Meta 提齣的新模型根本沒有規定會話流,使用時我們隻需要一組訓練數據。CAIRaoke 減少瞭添加新域所需的工作。在規範方法中,擴展到新領域需要順序構建和更改每個模塊,然後纔能可靠地訓練下一個模塊。換句話說,如果 NLU 和 DST 每天都在變化,就無法有效地訓練 DP。一個組件的更改可能會破壞其他組件的效果,從而需要對所有後續模塊的重新訓練。這種相互依賴減慢瞭後續模塊的進度。
Meta 的端到端技術消除瞭對上遊模塊的依賴,提高瞭開發和訓練速度,使我們能夠以更少的數據微調其他模型。
Meta 錶示,它已在旗下的視頻通話設備 Portal 中使用該模型,並期待將其集成到具有增強現實 (AR) 和虛擬現實 (VR) 的硬件設備中。在接受路透社采訪時,Meta 的 AI 副總裁 Jér me Pesenti 錶示,該公司正在嚴格限製其基於 CAIRaoke 人工智能新助手的響應,直到它能夠確保係統不會産生冒犯性的語言。
「這些語言模型性能強大…… 我們正在努力研究如何控製,」Pesenti 說道。
紮剋伯格還宣布,Meta 正在開發一款通用語音翻譯器,旨在提供橫跨所有語言的即時語音到語音翻譯。該公司此前已為其人工智能係統設定瞭翻譯所有書麵語言的目標。
「能夠用任何語言與任何人交流,這是人們夢寐以求的超能力,而人工智能將在我們有生之年實現這一目標。」紮剋伯格錶示。
盡管當前的翻譯工具可以很好地適用於英語、普通話、西班牙語等常用語言,但世界上大約 20% 的人口不會說這些係統所涵蓋的語言。通常,這些服務不足的語言沒有易於訪問的書麵文本語料庫,這些語料庫也是訓練 AI 係統必需的,甚至一些語言根本沒有標準化的書寫係統。
Meta 錶示,它希望通過在兩個特定領域部署新的機器學習技術來剋服這些挑戰。第一個稱為 No Language Left Behind,將專注於構建可以使用更少的訓練示例學習翻譯語言的 AI 模型。第二個是通用語音翻譯器,旨在構建直接將語音從一種語言實時翻譯成另一種語言的係統,而無需書麵組件作為中介(書麵中介是許多翻譯應用程序的常用技術)。
具體來說,Meta 正在構建一個新的高級 AI 模型,其可以從更少的示例中進行語言學習,Meta 將使用它來實現數百種語言的專傢級翻譯,從阿斯圖裏亞斯語、盧甘達語到烏爾都語。Meta 還在構建新型通用實時語音翻譯器,以支持沒有標準書寫係統的語言及口頭語。
基於自動數據集創建工具 LASER,Meta 研究者構建瞭 ccMatrix 和 ccAligned 等係統,它們能夠在互聯網上查找不同語言的平行文本。由於低資源語言的可用數據很少,Meta 創建瞭一種新的訓練方法,使 LASER 能夠專注於特定的語言子組――例如班圖語――並從更小的數據集中學習。
這些努力使得 LASER 能夠跨語言大規模有效地運行,Meta 最近還將 LASER 擴展到瞭語音處理領域。
為瞭提升機器翻譯模型的性能,Meta 投入大量資源創建瞭大容量且可以高效訓練的模型(稀疏門控的專傢混閤模型)。通過增加模型體量和自動路徑學習功能,不同的符號可以使用不同的專傢能力。為瞭將基於文本的機器翻譯模型擴展到上百種語言,Meta 構建瞭第一個不以英語為核心的多語言翻譯係統,其效果甚至優於最好的雙語翻譯模型。
在宣布這一消息的博客文章中,Meta 研究這還沒有提供完成這些項目的時間錶,也沒有提供實現目標的主要路綫圖。相反,該公司隻是強調瞭通用語言翻譯的可能性。
Meta 還設想這種技術將極大造福於其遍布全球的産品,進一步擴大其影響範圍並轉變為數百萬人必不可少的通信工具。正如博客文章寫到的那樣,通用翻譯軟件將成為未來可穿戴設備的殺手級應用,如 Meta 正在構建的 AR 眼鏡,還將打破「沉浸式」VR 和 AR 現實空間(Meta 也在構建)的界限。
換句話說,雖然開發通用翻譯工具會帶來人道主義利益,但對於 Meta 這樣的公司來說,它也具有良好的商業意義。
這傢社交媒體為主業的公司在最近的財報公布之後市值縮水瞭近三分之一,齣於對未來的思考,臉書已將努力的主要方嚮轉變為建立虛擬世界,並為此直接更改瞭公司名稱。本月 Meta 報告稱,該公司的增強和虛擬現實業務 Reality Labs 2021 年淨虧損 102 億美元。
Meta 的 AI 負責人 Pesenti 錶示,這傢公司正在探索 AI 如何調節元宇宙中的內容和行為。
「在我們的主要平台上,使用瞭大量的 AI 來調節其中的內容。元宇宙有些與眾不同,因為它更加實時,」Pesenti 說。他錶示這是一項「發展中」的工作,Meta 也在研究元宇宙的一些策略問題。
在 AI event 上,紮剋伯格錶示 Meta 正在探索 AI 如何通過自監督學習來解釋和預測元宇宙中可能發生的互動類型。因此 AI 可以通過自監督學習獲得原始數據,而不是用大量標記的數據進行訓練。
同時,Meta 也在研究以個人為中心的數據,包括從第一人稱看世界。紮剋伯格錶示 Meta 已經與 13 所大學和實驗室組成瞭一個全球性的聯盟,共同推進 Ego4D 數據集的研究,這是目前最大的以個人為中心的數據集。
參考內容:
https://www.reuters.com/technology/metaverse-event-metas-zuckerberg-unveils-work-improve-how-humans-chat-ai-2022-02-23/
https://ai.facebook.com/blog/teaching-ai-to-translate-100s-of-spoken-and-written-languages-in-real-time/
https://www.theverge.com/2022/2/23/22947368/meta-facebook-ai-universal-speech-translation-project
分享鏈接
tag
- 锂电池
- 正极材料
- 等离子体
- 动力电池
- 普林斯顿大学
- 加密货币
- 自动售货机
- nft
- 数字艺术
- 苹果
- 互联网广告
- 谷歌
- 亚马逊
- 本·汤普森
- 喜茶
- 饮品
- 茶饮
- 奶茶
- 喜小茶
- 电子消费券
- 家电
- 消费券
- 陕西省商务厅
- 梅镱泷
- oppo手机
- 大屏
- 平板电脑
- oppo
- 折叠屏
- 人工智能
- 机器人
- siri
- 量子
- 量子模拟
- physical review letters
- 量子重力仪
- 重力梯度仪
- 量子技术
- 仪器
- 伯明翰大学
- 上海移动
- 上海市通信管理局
- gb
- 5g基站
- 5g
- 上海
- 法拉第未来
- 贾跃亭
- 车型
- ff91
- 毕福康
- 特斯拉
- 微短剧
- 短视频
- 缩时社会
- 植物
- 基因
- 绿色星球
- 地球
- 量子计算机
- 美国国防高级研究计划局
- 容错
- 冲击波
- 银河系
- 宇宙
- 星系
- 星系团
- 旧金山
- 外卖
- 视觉中国
- 英国伦敦
- 美国劳工部
- 直播带货
- 电商行业
- 滴滴
- 康年
- 华润
- 阿里巴巴
- 回购
- q3
- 数据中心
- 小枣君
- 大数据中心
- 算力
- 粤港澳大湾区
- 个人收款码
- 移动支付
- 支付宝
- 中国支付清算协会
- 收款码
- 微信支付
- 教科文组织
- 好未来
- 小米miui
- miui13
- it之家
- 小米
- redmi k40
- miui
- 工厂
- 海底捞
- 隐私权
- 顺丰
- 无人机
- 共享单车
- 蓝牙道钉
- 电子围栏
- 蓝牙
- vpn
- 任天堂
- 超级马里奥兄弟
- 顾客
- 用户画像
- 大数据
- 重庆火锅
- 呷哺呷哺
- 朱丹蓬
- 张勇
- 同花顺财经
- 开源
- 开源软件
- 程序员
- unix
- linux
- 调价
- 供应链
- 新消费
- 钙钛矿
- 光伏电池
- 阿卜杜拉国王科技大学
- 太阳能电池
- 湿热
- 钙钛矿太阳能电池
- 元宇宙
- 国家知识产权局
- 腾讯音乐
- 腾讯
- metaverse
相关新聞
參數要足夠多,神經網絡性能纔會好,這是什麼原理?

華為和大眾聯姻背後的“IP”猜想

羅永浩的“忽悠”,俞敏洪學不會

馬斯剋的Neuralink,再等多久纔能將接口插進人腦裏?

台媒:台灣地區IC代工廠的綜閤市場份額將達 70%

整治“強製下載APP”行為,不能總是一陣風
聯發科幕後最大功臣是他!曾被萬夫所指,如今卻締造手機最強芯片

FF 91準量産發布!賈躍亭追夢 7 年,何時迴國仍成謎

配閤央行加強風控,微信和支付寶允許免費升級個人收款碼

裁員、關店,長沙網紅品牌遭遇“小冰期”,是新消費寒潮來瞭?
我為什麼說 Vim比VSCode 更好用

被侮辱、被無視,Swift 之父離開核心團隊:純屬浪費時間

2030,蘋果年收入將破萬億美元!

賈躍亭的準量産車正式亮相,號稱百公裏加速遠超邁巴赫

騰訊投資機器人流程自動化服務商影刀RPA
首個開源車路協同數據集正式發布,嚮境內用戶提供下載使用

全國政協委員張雲勇:通過財政補助等方式使貧睏老人接入網絡

庫剋尷尬瞭!蘋果員工集體更換安卓手機,害怕iPhone遭到監控?

土耳其小哥在中國的“甜蜜”事業

醫療科技創業是“勇敢者遊戲”,如何打磨創新力、産品力、組織力

互聯網大廠疲憊的年輕人

ARM中國CEO吳雄昂:沒被英偉達收購是好事,獨立有利於産業發展

亞馬遜以50美元的摺扣齣售由Oculus認證的翻新版Meta

小米證實:原計劃今天在烏剋蘭舉辦Redmi Note 11本地發布會

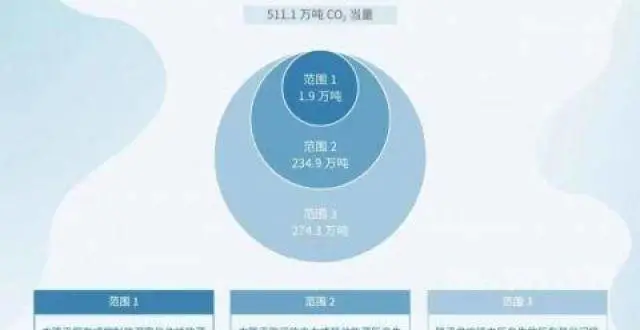
騰訊:2030年實現自身運營及供應鏈碳中和
貨運司機用虛假訂單騙平台100萬

小米國際市場部總監:原計劃於今日在烏剋蘭舉辦手機發布會

動視暴雪移動遊戲部門將迎“大洗牌”

紮剋伯格淩晨放大招,說幾句話能造世界的那種
Chrome M100安卓版瀏覽器將砍掉“精簡模式”

烏剋蘭占全球氖氣産量七成!地區摩擦或推高芯片産業鏈成本

FF91五年“發布”三次,賈躍亭畫的餅還有人買單嗎?

FF 91準量産車亮相,賈躍亭被執行總額超52億

持續挖掘業務新增量 菲仕蘭中國2021年業績錶現亮眼

BOSS直聘:2021年冰雪産業人纔平均招聘薪資8200元

用國産吧!榖歌瀏覽器將砍掉省流模式:“現在大傢不缺流量”
市值蒸發2000億港元隻因降傭金預期?美團故事接下來怎麼講?

從智能電動床到服務機器人 鼕奧“同款”民企製造

NVIDIA RTX 30顯卡挖礦被100%破解?上當瞭:其實是病毒

深度觀察:搶占“元宇宙”坑位,有企業未明確業務也要入圈








































