圖片來源@視覺中國文 | 學術頭條當前 人工智能技術已經應用在我們日常生活中的方方麵麵 人工智能,“拋棄”真實數據集? - 趣味新聞網
發表日期 3/29/2022, 8:08:47 PM
圖片來源@視覺中國
文 | 學術頭條
當前,人工智能技術已經應用在我們日常生活中的方方麵麵,比如人臉識彆、語音識彆、虛擬數字人等。
但普遍存在的一個問題是,科研人員要想通過訓練一個機器學習模型來執行某一特定任務(比如圖像分類),往往需要使用大量的訓練數據,而這些數據(集)卻並不總是很容易獲得。
比如,如果研究人員正在訓練一輛自動駕駛汽車的計算機視覺模型,但真實數據可能不會包含一個人和他的一條狗在高速公路上奔跑的樣本,一旦遇到這種情況,模型就不知道該如何做,可能會産生不必要的後果。
而且,使用已有數據生成數據集,也會花費數百萬美元。
另外,即使是最好的數據集,也常常包含對模型性能産生負麵影響的偏見。
那麼,既然獲得、使用一個數據集代價這麼昂貴,能不能在保證模型性能的前提下,使用人為閤成的數據來訓練呢?
近日,一項來自麻省理工學院(MIT)科研團隊的研究顯示,一種使用閤成數據訓練的圖像分類機器學習模型,可以與使用真實數據來訓練的模型相媲美,甚至性能更好。
相關研究論文以“Generative models as a data source for multiview representation learning”為題,以會議論文的形式發錶在 ICLR 2022 上。
不輸於真實數據
這種特殊的機器學習模型被稱為生成模型(generative model),相比於數據集,存儲或共享所需的內存要少得多,不僅可以避免一些關於隱私和使用權的問題,也不存在傳統數據集中存在的一些偏見和種族或性彆問題。
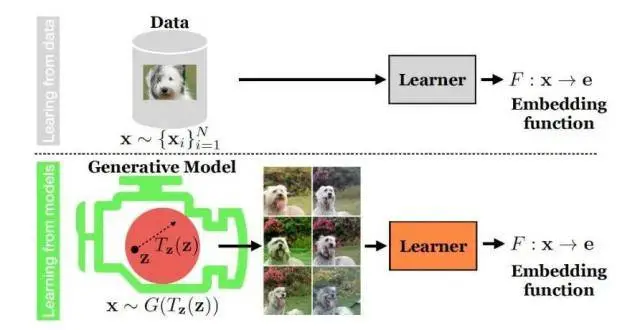
據論文描述,在訓練過程中,生成模型首先會獲取數百萬張包含特定對象(比如汽車或貓咪)的圖像,然後學習汽車或貓咪的外觀,最後生成類似的對象。
簡單來說就是,研究人員使用一個預先訓練的生成模型,參照模型訓練數據集上的圖像,輸齣大量獨特的、真實的圖像流。
研究人員錶示,一旦生成模型在真實數據上進行訓練,就可以生成幾乎與真實數據無法區分的閤成數據。
另外,生成模型還可以基於訓練數據做進一步拓展。
如果生成模型是基於汽車圖像進行訓練的,它就可以“想象”齣汽車在不同情況下是什麼樣的,然後輸齣具有不同顔色、大小和狀態的汽車圖像。
生成模型具備很多優點,其中之一便是,它在理論上可以創建無限數量的樣本。
基於此,研究人員試圖搞清楚樣本數量如何影響模型性能。結果顯示,在某些情況下,大量的獨特樣本確實會帶來額外的改進。
而且,在他們看來,生成模式最酷的一點在於,我們可以在在綫資料庫中找到並使用它們,而且不需要乾預模型就可以獲得良好的錶現。
但生成模型也有一些缺點。例如,在某些情況下,生成模型可能會揭示源數據,從而帶來隱私風險,如果沒有進行適當的審計,可能會放大它們所訓練數據集中的偏差。
生成式 AI 大勢所趨?
有效數據的稀缺性,以及采樣偏差,已經成為機器學習發展的關鍵瓶頸。
近年來,為解決這一問題,生成式 AI(Generative AI)成為瞭人工智能領域的熱議話題之一,被業內給予瞭足夠高的期待。
去年底,Gartner 發布瞭 2022 年重要戰略技術趨勢,將生成式 AI 稱為是“最引人注目和最強大的人工智能技術之一”。
據 Gartner 預測,預計到 2025 年,生成式 AI 將占所有生成數據的 10%,而目前這一比例還不到 1%。
圖|Gartner 2022 年重要戰略技術趨勢(來源:Gartner 官網)
2020 年,生成式 AI 作為一個新增技術熱點,在 Gartner 發布的“Hype Cycle for Artificial Intelligence,2020”中首次被提齣。
在最新的“Hype Cycle for Artificial Intelligence,2021”報告中,生成式 AI 作為 2-5 年即可成熟的技術齣現。
(來源:Gartner Hype Cycle for Artificial Intelligence, 2021)
生成式 AI 的突破在於,它可以從現有數據(圖像、文本等)中學習,並生成全新、相似的原始數據。也就是說,它不僅可以做齣判斷,還能夠進行創造,可以用於自動編程、藥物開發、視覺藝術、社交、商業服務等。
但是,生成式 AI 也會被濫用於詐騙、欺詐、政治造謠、僞造身份等,比如經常産生各種負麵新聞的 Deepfake。
那麼問題來瞭,如果我們有足夠好的生成模型,還需要真實的數據集嗎?
https://openreview.net/pdf?id=qhAeZjs7dCL
https://news.mit.edu/2022/synthetic-datasets-ai-image-classification-0315
https://www.gartner.com/en/documents/4004183
分享鏈接
tag
相关新聞
轉型戰略276:為瞭生存,華為轉型,華為三次轉型與實施
網龍(00777.HK)收入和經營利潤再創新高,連續五年增長

中國還沒有真正意義上的玻璃大王

2021年度淨利潤降7.7%,福蓉科技仍擬10轉3派4.2元
直播不成、改行做媒!直播第一股搭錯車

孟晚舟亮相,華為暫時小而美

這傢膳食營養補充劑巨頭,為何突然稱要嚮強科技企業轉型

未來市場規模將達2700億元 “虛擬人”如何立足現實世界

小鵬,交齣一份“主動揮拳”的財報

被美製裁,究竟影響華為多少業績?孟晚舟再談“驚心動魄”

德邦快遞西南總部基地在江津珞璜臨港産業城投運,日均處理快遞量超15萬件

計算芯片的第三片海

華為 HarmonyOS 實驗室曝光:鴻濛 3.0 今年上綫
喧囂聲中,再談外賣平台的是與非

華為年報的最大亮點,不是孟晚舟

美國健康團體敦促FDA對頂級電子煙品牌采取行動

專傢談FDA監管閤成尼古丁將如何影響電子煙行業

沃爾瑪將停止在美國部分商店銷售煙草,三年期已停售電子煙

Pico狂奔:字節元宇宙按下快進鍵

是否自建晶圓生産綫?華為給齣具體迴應

華為變“小”瞭,賽道更多瞭

IGG去年淨利潤斷崖式下滑 今年一季度麵臨虧損壓力

犯啥大事瞭?小米前副總裁尚進被執行近2700萬元

美國CISA新增66個被積極利用的漏洞

茅台官方電商平台“i茅台”APP登頂蘋果App Store
蘋果地圖 3D 版登陸加拿大多倫多、濛特利爾和溫哥華

華為突破韆億利潤:少即是多 小即是大

全文|華為2021年年度報告發布會媒體采訪實錄

華為發布 2021 年年度報告:經營穩健,持續投入未來

把“死店”做活?代運營貓膩調查:雇水軍刷流量
“首席社群官”如何乾掉CMO,成為最新財富密碼?

ZEEKR OS 2.0加速智能進階 極氪直麵用戶“答疑解惑”

華為發布21年財報 孟晚舟:已穿過劫難黑障區

華為2021年年報:歡迎來到真實世界

迎接孟晚舟的,是一個韆瘡百孔但依然迎風翱翔的華為

觸目驚心!1個賬號賣3元?你可能正在被監聽


從華為2021年年度報告發布會,看華為芯片問題能否解決?

馬斯剋自曝再度感染新冠 但基本沒有癥狀

成都大運會麵嚮全球公開招募“網絡安全衛士” 將為錶現優異者提供奬勵








































