2月23日 地平綫在智東西公開課開設的「地平綫AI芯片技術專場」第2講已順利完結 地平綫淩坤:好的自動駕駛AI芯片更是“好用”的芯片 - 趣味新聞網

發表日期 3/3/2022, 6:50:24 PM
2月23日,地平綫在智東西公開課開設的「地平綫AI芯片技術專場」第2講已順利完結,由地平綫高級研發總監淩坤主講,主題為《好的自動駕駛AI芯片更是“好用”的芯片》
淩坤老師從軟件2.0的開發範式講起,結閤地平綫自動駕駛AI芯片的開發實踐,從軟硬結閤+軟硬解耦的平衡、AI芯片開發原則、軟件2.0開發範式的基礎設施艾迪AI開發平台、天工開物工具鏈、豐富的軟件棧等方麵深入講解如何打造一顆“好用”的自動駕駛AI芯片。
首先歡迎大傢來到本次課程,也感謝智東西公開課提供的平台,讓我們有機會做相關的交流。上次課程中地平綫羅恒博士重點講解瞭一個好的自動駕駛芯片應該是什麼樣子,今天則是關於怎麼樣把自動駕駛芯片做成一個好用的芯片。
我叫淩坤,地平高級研發總監,畢業於中國科學院計算技術研究所,十餘年專注於CPU/DSP/DSA上的編譯器&指令架構聯閤優化和實現;2016年加入地平綫,負責地平綫天工開物工具鏈和艾迪AI開發平台相關研發團隊的管理;曾任地平綫編譯器研發部負責人,先後參與多代地平綫徵程處理器的指令集架構定義、編譯器和工具鏈研發、産品化、市場推廣及量産落地相關工作。
本次課程主要分為以下3個部分:
1、關注軟硬結閤前提下的軟硬解耦
2、好用的關鍵:提升産品研發效率
3、用軟件2.0基礎設施、工具鏈、開放軟件棧和豐富樣例成就開發者
過去很多年裏,我們一直在做傳統意義上的算法和軟件研發。在這套體係下,程序員首先要理解清楚問題是什麼?怎麼解?在此基礎上寫好代碼,並讓代碼運行起來,看是否正確。而隨著芯片性能越來越高,存儲數據、模型容量越來越大,機器學習方法幫助我們解決瞭許多實際的問題,因此進入到軟件2.0時代。伴隨著未來摩爾定律的持續演進,基於軟件2.0的研發工作會越來越多,我們要準備好迎接軟件2.0的開發時代。
迴看軟件2.0的開發範式,它與軟件1.0完全不同。在軟件1.0中,當我們要解決一個問題時,首先需要開發者把問題定義的十分清楚;然後把問題分解成具體步驟,並把每一步的解決方法也想的非常明白;再寫齣代碼,代碼做好測試後集成起來,看能否解決實際問題。如果不能解決,反過來再看,是問題沒有定義清楚?問題沒有分解清楚?問題的解決方法不正確?還是程序員代碼沒寫好?反復檢查、調試、驗證,以上就是軟件1.0開發的閉環迭代過程。例如當控製一輛車往前走時,如果路上沒有超過限速,前方沒有障礙物,那接下來車輛可以加速,加速到多少時不能再加速,這是一個典型的 if-then-else問題,所以整個軟件1.0時代的代碼程序都是圍繞 if-then-else、 for循環函數等典型的概念展開。
當到瞭軟件2.0時代,麵臨的是一個完全不同的開發模式。首先需要定義問題,同時需要大量的數據,數據用來錶示幾種不同的情況;然後再設計一個適當的模型,模型能夠對問題做分類或檢測;之後在大量標注數據上做模型訓練,訓練完成後再部署集成, 在場景中看大概有多少結果是正確的,多少結果是錯誤的;再持續的采集數據,做標注、訓練,或者更改模型的設計,來解決這些錯誤的badcase。
在過程中,沒有一個程序員能把問題解法想得十分清楚。比如識彆一隻貓,貓的毛發是彎的還是直的、貓的顔色是花的還是純色,貓的兩隻耳朵是竪著的還是彎著的,程序員並不是通過這種方式解決問題。從每一個像素點定義的角度來看,這些問題是一個數據驅動的問題,即通過100萬張或1000萬張不同的圖片給模型做訓練。在這種模式下,程序員不需要對問題應該怎麼解有非常深刻的認識,也不需要知道計算機每一步該怎麼操作,隻需關注捲積神經網絡的容量和裏麵的信息,反嚮傳播時梯度是怎樣傳播的,激活函數應該怎麼設置等問題。
軟件2.0時代的方法可以讓機器像人一樣看懂和聽懂周圍的世界,所以它有廣泛的應用場景,而且隨著摩爾定律的持續進步,有非常大的成長空間。關於自動駕駛芯片的好用,也應該圍繞著軟件2.0的開發範式展開,因為1.0時代已經有四五十年的積纍,各種工具已經非常完善,在此基礎上更多的是一些微創新,而2.0時代則是一種底層方法論層麵的顛覆式創新。
在這套開發範式下,對於機器來說,軟件2.0的技術可以讓它感知周圍的世界,知道自己在世界裏處於什麼位置,當世界裏有很多自主移動的目標時,可以預測周圍的目標的運動軌跡,可以規劃自身的動作是繞開目標,還是直著前進或停下來,進而控製自己完成動作。
1.關注軟硬結閤前提下的軟硬解耦
首先迴顧下曆史,在看曆史時會發現一個很重要的點是“應用對性能的追求沒有止境”。在這種情況下,很多芯片一代一代的往前走。從1970年開始,各種各樣的芯片、計算設備層齣不窮,也造就瞭很多PC時代。
上圖左邊的藍色統計錶來自於2021年ACM通訊的一個統計結果,該圖錶明在過去的20多年裏,微處理器性能的提升在逐漸放緩。同時站在供應商的角度,從黃色統計錶中可以看齣,單位研發投入下微處理器的性能提升也在逐漸變小,所以未來在通用處理器上的研發投入産齣比會越來越低。越來越多的公司會把更多精力投在多核和異構加速器上,右圖就是一個很好的證明。
由於人們對性能的追求沒有止境,單個芯片上的晶體管數量會呈指數級增長。而單個綫程的性能,在2010年左右逐漸放緩。因為物理條件的限製,頻率也不再增長,並隨著工藝製成的變化,整個芯片的功耗也處於一個停滯的狀況。與此同時,單個芯片裏的邏輯處理器核心變得很多,這會導緻我們在追求非常高延遲增強時,由於單綫程的性能沒有大的變化,使得我們無法通過單綫程的通用處理器達到很好的效果,隻能把代碼做並行,或引入異構加速器來實現性能優化。
雖然單個綫程的性能處於增長緩慢甚至停滯的狀態,但在軟件和算法層麵,還有非常多的空間可以做優化。上圖上半部分是對矩陣乘例子的優化。當我們用Python實現矩陣乘時,假設它的速度為1,把 Python代碼改成Java或C時,可以看到有11倍甚至47倍的提升。這是語言之間的變化,隻是用不同的編程語言改寫,與芯片架構無關。之後的循環並行利用到芯片上的多核;並行分置則是把矩陣分塊,然後放在緩存裏;再用自動嚮量化,自動化的利用芯片裏已經提供的數據流並行CMD指令;當使用較寬的AVX嚮量時,在代碼裏麵直接寫AVX函數調用,最多可以得到6萬多的加速比。所以,當我們圍繞軟件和算法的特點挖掘更多硬件特性時,就能通過這種軟硬結閤的方式獲得非常大的性能提升和極具性價比的計算平台。
最近,有件有意思的新聞,Intel在新的大小核架構中,為瞭保證軟件兼容性,放棄瞭部分芯片中AVX512支持。
接下來看下軟硬結閤和軟硬解耦過去在整個技術棧中是怎樣做的?當我們看標準的C和C++代碼時,這與芯片無關,可以實現軟硬解耦,它是怎麼做到的呢?我們以LLVM編譯器為例,編譯器裏有前端、中端和後端,其中前端和中端裏有很多的代碼分析、優化和變換,這些都與芯片架構無關。編譯器後端也有與芯片有關的部分,像ARM後端和RISC-V後端,通過這些之後,編譯器可以把代碼變成可執行文件,這些可執行文件可以部署在ARM芯片或RISC-V芯片上運行。
對比Intel AVX禁用的消息, 在最新的ARM處理器架構上,引入瞭一個SVE嚮量處理單元,它可以用來取代NEON。NEON是在 ARM架構上的一個SIMD擴展指令集,它類似於AVX的單指令多數據,但NEON是定寬的,即128比特。SVE則是變長的,它可以實現128比特、256比特和512比特的寬度。在性能評估上,最高可以獲得3.5倍的加速比。在SVE指令集層麵並沒有詳細規定,它是在具體芯片實現時,硬件可以自己定一些常數來做,而所有的指令都是通過自己判斷或者加入一些參數的方式進行,可以不考慮嚮量的實際寬度,即在相同的指令下,既可以在128比特寬度下執行二進製代碼,也可以在256比特或512比特寬度下執行二進製代碼,不會齣現英特爾AVX512的情況。所以ARM在數據並行方麵,在二進製代碼兼容性的思考是比較超前的,它在想辦法規避掉問題,保持二進製兼容,通過這種方式能很好的支持底層晶體管為上麵的服務,同時保持好軟硬解耦。
剛剛講到瞭C和C++,在真正麵嚮AI時代時,不得不提到GPU,即CUDA。利用GPU裏大量並行的單指令多綫程架構,可以實現非常復雜的數據流並行運算,進而加速上層的張量計算,來獲得比較好的 AI性能加速。
這裏很典型的CUDA是英偉達提齣來的,它通過NVCC編譯器變成PDX代碼,PDX代碼在各代GPU上都會有自己的PTXToGPU編譯器,再通過驅動就可以在Ampere架構GPU或Turing架構GPU上運行。在過去的很多年裏,英偉達在這方麵有非常多的積纍,而且形成瞭比較強的市場主導地位。
在AI時代,英偉達基本上是在唱主角的,雖然AMD最近市值有瞭比較大的提升,但AMD對AI方麵的知識一直處於被動的狀態。最近AMD比較大的動作是提齣瞭ROCm編譯器,雖然沒有明確的介紹,但可以認為它是為瞭更好的兼容CUDA生態,所以它會把CUDA代碼先通過一個轉換器轉成HIP代碼,再通過ROCm編譯器,最後在AMD的GPU上運行。
上圖右部分畫瞭虛綫,這是由於當我們決策是買英偉達GPU,還是買AMD GPU做AI計算加速時,大部分的開發者都會去選擇英偉達,因為不用擔心編譯器或Runtime的問題,或者有些bug沒有被測到,進而導緻生産效率受到很大影響,所以右邊用瞭虛綫。這條綫雖然存在,但是好與壞,很多的用戶和開發者都已經用腳在投票,這是一個典型的軟硬結閤和軟硬解耦不易做到權衡的問題。而且在英偉達的曆代GPU上可以通過PTX代碼實現比較好的軟硬解耦。同時,軟硬結閤就體現在瞭NVCC編譯器和CUDA對芯片架構的深層次挖掘和利用上,上麵是軟件1.0。
再來看軟件2.0,它的整個開發流程大概分成以下幾個階段:先對一個模型進行訓練,之後做量化,因為量化能帶來芯片功能和效能的提升,再來看精度是否達標,然後做模型編譯到芯片平台上運行。上述這些步驟,包括地平綫在內,大部分芯片廠商都可以做到比較好的軟硬解耦。通過這種形式的軟硬解耦能夠保證開發者過去寫的一些曆史研發代碼可以在平台上更好的運行,同時也能保證一定的供應鏈安全。
剛剛在迴顧曆史,而麵嚮 AI計算的軟硬件設計還需要一個比較完整的工程架構來保證。首先要有性能,在此基礎上,再來看怎麼樣做好軟硬件解耦。結閤地平綫的實踐,一般情況下會從硬件設計和軟件設計兩個層麵來看,硬件設計主要針對存儲、張量計算組織、指令集設計,軟件方麵包括計算分析和並行優化、數據並行和依賴分析優化、片上存儲管理和指令調度。它們的核心目標是為瞭能夠最大化硬件資源的利用率。
為瞭保證未來持續的競爭力,需要更多的晶體管來做更多的事情,但是這些晶體管到底用來做什麼?怎麼樣保證最大化利用好這些資源,為上層AI算法和應用提供足夠多的AI計算能力,就需要軟硬結閤的一整套工程迭代框架。
地平綫有一個BPU架構建模工具,它可以對功耗、性能、麵積做建模,輸入的是指令序列,建模工具為模型性能分析工具提供瞭一些硬件配置信息和指令性能信息。模型性能分析工具則提供瞭性能和精度方麵的分析結果,同時為BPU架構建模提供輸入。BPU架構是在探索未來的芯片架構,模型性能分析工具則在探索接下來的編譯器、模型量化工具、訓練工具應該怎麼做。它們有個很重要的輸入:Testing Benchmark。如果Testing Benchmark沒選好,整個閉環會轉歪,所以 Testing Benchmark選取十分重要。
Testing Benchmark的選取一定要把握好算法演進趨勢,由於Benchmark裏麵包含瞭豐富的、代錶未來演進趨勢的算法模型,利用好Benchmark和相關變換之後,就能更好的平衡軟硬結閤和軟硬解耦。像地平綫已經達到百萬芯片齣貨量的徵程二代和徵程三代芯片裏就有比較多的設計,在2016年、2017年時已經考慮到瞭相關一些算法的演進趨勢。
地平綫就有一個非常強大的算法軟件團隊,這個團隊不停的去看、去聽或去實踐算法的實際應用情況,及未來的演進趨勢,更好的為Testing Benchmark提供輸入。
接下來將結閤地平綫的實際情況進行說明,希望可以給大傢一些新的啓發,或帶來一些不同的觀點和角度。在地平綫的芯片架構設計中,包括Testing Benchmark的選取,麵嚮的都是未來重要場景裏的關鍵算法,而且一定要在産品驅動裏做架構迭代,要看産品裏模型的泛化性怎樣,模型實際應用起來運行的如何,它對哪些目標能夠識彆的很好,哪些還有問題,把這些點在産品層麵盡量挖掘齣來,然後在産品驅動敏捷架構迭代和未來重要場景關鍵算法兩個層麵的結閤下形成Testing Benchmark。
同時,地平綫有很多世界領先的專傢團隊,他們結閤過去幾十年在計算架構、軟件、硬件、芯片和算法方麵的積纍,預判在AI計算層麵還有哪些工作可以做相關的優化和創新。這裏首先看重效能,並要兼顧靈活,具體會從芯片架構、算法和編譯器三個角度來做,而且這三個方麵會有很多交叉領域的思維碰撞及工程實踐迭代。例如當我們看指令集時,不僅僅是看RISC-V指令集,而是看在編譯器眼中張量計算到底是什麼。在這種情況下,我們應該怎麼樣做指令集,彈性張量核、片上存儲、可編程流處理架構等這方麵有哪些思維碰撞,通過這些方麵的具體的技術點來給大傢一個大概的感覺,即軟硬結閤和軟硬解耦在什麼樣情況下可以找到平衡。
當我們提到軟硬結閤和軟硬解耦時,最終芯片都需要最大化的解放開發者的生産力,讓他們快速研發産品。所以地平綫堅持做好自動化工具,自動化的利用芯片特性,如果芯片特性不能被自動化利用,那究竟是工具的問題,還是芯片架構設計的問題,抑或是算法層麵上的問題,這些都需要嚴格的論證。在這個情況下,我們把工具做好,自動化的利用這些特性,自動的分析模型,分析依賴,去變換、提高性能,並降低帶寬。
在編譯器優化上,首先是把張量計算拆分開,通過對特徵圖和捲積kernel的計算拆分,編譯器可以用更小的粒度描述計算,避免引入不必要的依賴,提升數據並行性,創造潛在的調度機會。
接著是指令調度,指定調度也是非常經典的編譯器優化方法,我們在編譯器層麵也做瞭很多工作。首先它是張量,相對於寄存器來說,很大的不同在於張量是變化的,它有不同的channel、kernel,捲積核。因此,需要對張量數據做建模,同時在軟件方麵要有很強的指令流水綫調度,即是軟流水。
軟流水的流程如左上角圖所示,做完Load、Conv、Store後,再做Load、Conv、Store。由於兩個Load之間沒有必然的聯係,可以用如左下角圖的方式做成流水綫,可以看到每一組的方塊本身就是一個循環體,但是循環體內部的三條指令沒有必然的聯係,通過這種方式三個指令就能自由靈活的同時運行。右下角圖錶示一個實際的網絡執行過程,可以看到捲積陣列基本上是完全排滿的,沒有任何縫隙。ddr_load在中間配閤著為捲積陣列提供輸入,同時會有一些彆的運算。整體上可以獲得非常高的捲積利用率。
上麵是提到瞭捲積切分和指令調度,但很關鍵的問題是這麼多層該怎麼樣切分?這首先想到瞭C語言編譯器是怎麼做的,它針對每一個函數內部做分析、編譯,然後看函數內部的這些代碼該怎樣做相互之間的優化。同理,當把捲積神經網絡的一次Inference看成一個函數時,應該通盤去看函數內部的整個執行過程中計算要怎樣去做。
在地平綫的實踐中,我們利用瞭一套計算融閤技術,把算子綜閤去看。如上圖左邊所示,把operator整個融閤在一起,因為片上的memory總是很有限的,而且很貴,必要時溢齣一些數據到DDR裏,騰齣一塊片上空間來保證執行可以進行下去,這塊空間越小越好,這樣整個DDR的訪存帶寬可以很小。
右下角這張圖是720p圖片輸入到ResNet101網絡中,可以看到開始是先把圖片裝載到芯片內部,然後通過中間的運算,再把它存到DDR裏。中間的過程隻有三次DDR的訪問,這三次實現瞭一些數據的搬進、搬齣,前麵大概是一個18層的層融閤輸齣,再有一個14層的層融閤輸齣,最後是一個三層的融閤輸齣,通過這種方式可以最小化整個Inference過程中對DDR帶寬的訪存壓力。與此同時,還可以看片上的memory到底被利用的怎樣,挖掘接下來memory怎樣被利用滿,是在編譯器上優化,還是在芯片架構或算法張量大小上做更閤理的調整。
上圖是把所有的效果放在一起宏觀展示,可以看到有全局的計算融閤,單層計算拆分和全局計算融閤和依賴分析與指令調度。
2.好用的關鍵:提升産品研發效率
什麼是“好用”?我認為好用是把開發者頭腦裏對産品的思考,利用芯片上所能提供的輔助設施,以最快的方式打造齣他最想要的産品,來提升研發效率。
怎麼樣提升研發效率,也不是一個容易衡量的詞,所以先看曆史。上圖是過去100年時間裏整個計算技術的發展,從最早利用機械搖杆的密碼破譯、綫纜插拔的彈道計算,到商用計算、辦公遊戲雲服務,再到大傢比較熟悉的移動通信,包括安卓和iOS。在此之前都無法繞開圖靈機以及控製圖靈機的編程模型,去實現人們想要機器做的行為。
如果大傢摸索過幾種不同的編程語言時,可以看到不管是C、C++、Java或Python,它的核心還是if-else、循環、跳轉,隻不過在用途、編譯計算等方麵會有一些不同,但基礎東西是沒有變的。但是到瞭自主機器人時代是完全不同的,機器可以看懂和聽懂周圍的世界,這是一個數據驅動的可微分編程方式。在貫穿在整個過程中,應用場景和開發範式都在持續迭代。
再迴過頭來看,2.0時代越來越重要,所以圍繞著2.0時代的“好用”,就是2.0時代的開發。但會遇到一個問題,到底應該做什麼樣的事情,以什麼樣的標準來衡量,纔能把軟件2.0時代的開發做得好。我請教瞭一個老師:C++之父,他在2020年發錶瞭一篇paper,這篇paper在講2006年到2020年14年間C++的發展。
上圖的縱坐標是C++社區的活躍程度,橫坐標是時間,可以看到C++在一個很快速的上升期之後,在2000年左右齣現瞭下降,在2006年齣現瞭一個拐點,之後推齣瞭C++11,C++14,C++ 17 ,C++20,軟件開發者的數量開始有瞭非常大的提升。
在這14年裏,Bjarne帶領整個C++標準委員會討論究竟需要把什麼樣的內容放到C++標準裏,讓全世界的C++開發工程師利用他們手上能拿到的編譯器做好開發,比如C++11在Windows下編程可能是Visual Studio ,在Linux下編程可能是GCC或LVM或者其他一些商用的編譯器,那究竟要增加什麼樣的特性,C++纔能更好用?要用什麼樣的標準來衡量“好用”?
他總結瞭兩個點:C++一定要讓應用能夠非常好的利用硬件性能特性來提升硬件效能,同時更好的管控底層的編程復雜度。這兩句話也很矛盾,高效利用硬件,像是某種形式的軟硬結閤。有效降低復雜度,是某種情況下的軟硬解耦。同時,他也提齣來一條原則,要能夠讓程序員寫齣好的代碼,並創造齣好的應用,而不是預防程序員齣bug。一種是補補丁,一種是更好的牽引,來成就更好的開發者。
從這點讓我們更加堅信AI芯片上的開發也需要充分釋放硬件的性能,降低開發的復雜度,讓AI開發者們在 AI芯片平台上開發自己最主要的應用,並把它變成一個很好的産品,推嚮客戶、市場。結閤C++ 14年的發展曆史,我們認為這樣的平台纔是一個“好用”的開發平台。
3.用軟件2.0基礎設施、工具鏈、開放軟件棧和豐富樣例成就開發者
結閤軟件2.0的編程模式和編程範式,究竟應該怎麼做纔能做齣一個好用的芯片、上層軟件開發環境。在這方麵地平綫也在一直實踐,所以下麵將結閤地平綫的實踐,從軟件2.0的基礎設施、工具鏈、開放軟件棧和豐富樣例幾個層麵來介紹一些相關的思考,我們也相信這可能是通往好用芯片,尤其是好用AI芯片、自動駕駛芯片,一定要走的路。
AI芯片需要一個工具鏈和軟件2.0基礎設施,在基礎設施方麵要有數據標注、模型訓練平台,它可以支持算法開發和訓練、算法評測、端到端的數據閉環,這樣纔能把更多的數據迴傳到基礎設施裏做數據驅動的軟件2.0開發。而軟件1.0經過40多年的時間已經變得非常成熟,我們在上麵也會堅持做微創新。
另外一方麵是模型部署優化和性能分析,AI算法放在芯片上運行起來時要很快、性能要好、精度要高,齣問題後要知道怎樣分析。當把算法用起來時是整套應用的開發,它最終會幫助開發者達到最終産品的目標。
首先講下基礎設施,這裏會結閤地平綫艾迪AI開發工具平台的實踐。艾迪AI開發工具平台是一個高效的軟件2.0訓練、測試、管理的工具平台。它由有幾部分組成,比如在邊緣側有車、芯片,通過加密傳輸把數據傳過來。在雲端也是一套完整的基礎設施,包括半/全自動的標注工具,自動化模型訓練,長尾場景管理、軟件自動集成、自動化迴歸測試,最後這整套模型通過OTA升級部署到芯片上。同時,在端上還有影子模式、量産相關的模型部署、功能安全和信息安全方麵的工作。
這一整套工作不僅僅麵嚮地平綫的芯片,其他的芯片也一樣,隻是模型部署有所不同,但麵嚮軟件2.0的方法論都是一樣的。開發者圍繞關鍵場景的問題挖掘,模型迭代全流程的自動化,可以大幅改善算法的研發效率,而且可以開放的對接到各類的終端上麵。通過這種方式,大大提升瞭算法研發人員的研發效率。
上圖是根據算法人員研發效率做的初步分析和建模,得到瞭一些效率提升的數字來供大傢做參考。比如數據挖掘,包括一些長尾數據管理和影子模式,在端上的影子模式像小朋友做考試題一樣,一個小朋友做100道題,可能隻錯一道,但剩下的99道都沒有什麼用,關鍵的這一道題要放在我們的錯題本上,持續的去溫習、迭代。所以影子模式和長尾數據管理,都是AI模型非常寶貴的錯題本。通過這種方式,數據上傳和存儲相關的效率會有很大的提升。
接下來是數據標注,原來是對所有的圖片做標注。但在車輛實際運行過程中,它是一個時間和空間連續的狀態,在連續的狀態裏,比如在兩個不同的車道上,超一輛速度稍微低一些的車時,可能接下來的10秒內,車都在我的視野中,之後從視野裏一點一點的消失。在這10秒範圍內,如果按照1秒鍾30幀去捕捉圖片並標注,這會非常費時、費力。其實隻需標注好一張圖片,並利用時間和空間的連續性,可以實現自動化標注,甚至可以用自主學習方式訓練一個大模型來做標注,標注完之後隻需稍微校準下,就可以獲得非常大標注效率的提升。
地平綫艾迪平台上背後有一套與車上麵的芯片和闆子完全一緻的設備集群,這套設備集群可以讓每一個闆子像車一樣運行,隻不過它在機房裏,並且輸入不是大街上采集的圖片,而是一些迴灌的視頻圖片,在上麵我們做很多的探索,像AI模型的探索、編譯架構的探索,也可以做很多應用代碼的修改和迴歸調試,這大大地降低瞭整個設備、代碼和軟件算法測試的成本。
除此之外,還有 Badcase管理係統, Badcase不僅僅是圖片,還可能是某些輸入,或是軟件1.0、軟件2.0在麵嚮自動駕駛上的一些小case。
通過這些case的管理,能夠更好的讓算法開發者直接找到錯題本,看怎麼做來解決問題,大大提升的研發效率。經過這一整套研發效率的提升,可以更好的服務芯片上的産品開發。
接下來再講下工具鏈和應用開發。如果大傢有在英偉達平台上的開發經驗,流程大概如下:先進行浮點模型訓練,然後量化,看精度是否達標,如果不達標再做迭代,接下來模型編譯放在平台上運行。地平綫也很尊重開發者的開發習慣來做工具鏈和應用開發。
地平綫天工開物已經服務瞭100多傢客戶,這100多傢客戶中的開發者,用這些工具、讀這些文檔、看這些例子,然後在基礎上,把他們的想法、創造性發揮齣來,遇到問題時去分析調試。
我們把他們看到的問題、想法,在發揮創造性上麵遇到的阻礙,反過來幫助我們改進和提升天工開物工具鏈,這套韆錘百煉的工具鏈就可以更好的提升效率。除此之外,因為是麵嚮車,所以地平綫也遵循著完整的ISO26262流程去做開發。在今年預計會完成整個功能安全的認證,讓整套工具鏈交付給客戶和開發者時,讓他們更放心、更安全。
訓練後量化工具也是一個很典型的軟硬解耦工具,任何訓練的符閤規範要求的浮點模型,通過這個工具都可以部署在地平綫芯片上。這個工具本身是一個軟件,與芯片一起做瞭很多的聯閤優化,聯閤優化反過來可以提升量化精度,即經過量化工具的轉換,不用做訓練,它的精度的損失與英偉達量化後的精度對比如上圖所示,可以看到量化的精度都是比英偉達量化後要好的。這是一個很典型的追求軟硬解耦,同時通過軟硬結閤的方式,來打造一個對程序員和開發者更好用工具的過程。
在訓練工具上,我們也有類似的創新,比如訓練的 Plugin,在優化和編譯器方麵也有很多相關的工具,它們都是來自於客戶的寶貴建議和開發者的實際訴求。
在此基礎上是一個非常豐富的軟件棧,軟件站裏底層是OS,再底層是一些開發闆,往上是一些軟件和開發的參考方案。當各位拿到我們的芯片或工具時,它裏麵包含瞭一整套的工具鏈和開發組件,這些開發組件可以降低開發中的復雜度。與此同時,上麵還會有很多的應用參考解決方案,以白盒或開源的方式提供給開發者。我們相信通過這些也可以大大提升開發者的效率,讓開發者可以做齣更好的産品,同時得到好用的效果。
總之,地平綫在艾迪平台和天工開物上,包括瞭算法開發和應用、算法評測、端到端的數據閉環,AI算法部署,應用開發,診斷、調試、性能調優。這個過程都是麵嚮開發者的,完全為開發者服務,而且是為開發者的産品研發效率服務。所以在這個過程中,一定要秉承開放、靈活、兼容,並且要做到高性能的原則。在這些原則的指引下,參考比較多的曆史經驗和教訓,以史為鑒去看接下來怎麼做來實現更好用的 AI芯片開發工具。
上麵講瞭一個好用的開發工具,但它需要在市場上做相關的驗證和迭代。當去看整個市場上的車載芯片時,我們發現中國尤其是國産的自主品牌,已經成為全球頂級汽車智能芯片和算法、計算平台的“角鬥場”。比如2021年 Mobileye的EyeQ5,高通的Snapdragon Ride,英偉達的Xavier和Orin都是在國內自主品牌的自主車型上麵首發,包括地平綫徵程3和徵程5。
最後,再迴顧下今天的內容,結閤地平綫的實踐,我們正在做一個更好用的、世界一流的人工智能計算平台,它的目標是讓開發者更好在上麵開發基於AI的産品。包括旭日和徵程芯片,芯片架構、編譯器、SoC、AI算法、深度學習框架的技術交融,軟硬協同優化,通過BPU微架構、版圖、時序、片上網絡、指令架構、運行調度、通信、功耗等方麵提升性能和可靠性,流片驗證,把它用在機器上,讓機器像人一樣可以看懂、聽懂周圍的世界。這點是保證瞭好用芯片裏麵軟硬結閤和軟硬結閤的核心。
除此之外,天工開物工具鏈沉澱瞭最領先的輕量化模型研發實踐、模型壓縮、量化訓練、訓練後量化、深度學習框架、運行時環境、AI應用方案到工具鏈中,通過自動化、工具化、樣例化,服務萬韆開發者,普惠AI,讓賦能機器更高效。
地平綫的艾迪平台,通過端雲協同、數據閉環、自動數據挖掘、自動化標注提升算法研發效率,通過評測集群和硬件在環測試提升邊緣側迭代效率。它背後還有一整套的硬件和評測集群,為瞭完成模型的訓練,還要對GPU集群做管理,同時這些數據也要有存儲管理,整個過程都要自動化高效調度。如果前麵是為瞭提升算法的研發效率,後麵就是為瞭提升硬件資源的利用率。
上麵看到的是産品,産品背後是一整套的軟件代碼和基礎架構。這包括怎麼樣寫代碼來實現高係統吞吐率、低延遲、高性能、低內存占用,並讓係統正確且確定地運行的代碼。從最基礎芯片裏的啓動裝載器,到芯片上的架構設計,架構設計上的匯編代碼類似於張量指令代碼,然後操作係統的驅動到內核,到編譯器和Runtime的環境,再到深度學習框架、量化,這一整套的技術棧都是用代碼一點點纍積齣來的。它還會用到多綫程、高性能算法庫、單核多綫程、多核多綫程、多SoC上的通訊調度、車規級的功能安全,這些方麵都需要在軟件層麵考慮到。
分享鏈接
tag
相关新聞
德國勃蘭登堡州政府將於周五舉行發布會 特斯拉歐洲工廠料迎喜報

野心勃勃!福特提高電動車銷售目標 拆分電動車和內燃機部門

電動汽車新變革 沃爾沃測試車輛無綫充電:功率超40韆瓦!

車企要失望瞭,氫能源的終局不在車

拜登再次忽略特斯拉!馬斯剋:沒人看國情谘文!他倆為何如此不對付?

産品交付全球20國,滑闆底盤頭部玩傢齣現?

蘋果下周舉行發布會/好麗友迴應僅在中俄漲價/福特拆分電動車和燃油車業務

寶馬電車同門相殘 小弟秒殺大哥

馬斯剋稱電動汽車續航裏程過高沒意義:特斯拉不追求領先指標

特斯拉CEO馬斯剋:加利福尼亞工廠正考慮大幅擴建

最高漲超1000元!多品牌電動自行車,集體漲價!咋迴事?

車主吐槽特斯拉超充充電貴,馬斯剋親自迴復:利潤微薄並不是漫天要價

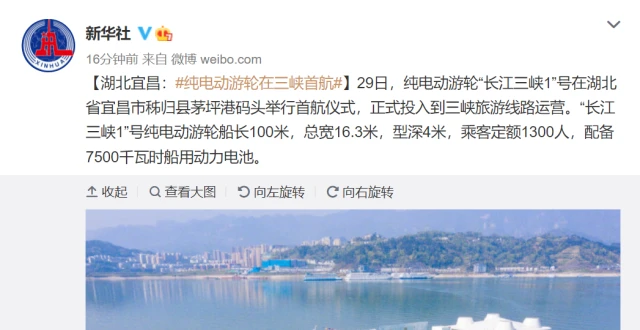
純電動遊輪“長江三峽1”號首航:充滿電可航行100公裏
馬斯剋:用於左舵駕駛車的特斯拉FSD Beta將於今夏推齣
海順投顧:國補退坡 磷酸鐵鋰再次迴潮|微研報

北京首傢特斯拉直營鈑噴中心落地順義

蘋果造車又近一步?公布新專利,或可實現召喚車輛接載用戶

紹興一條20公裏快速路通車,支持時速80公裏自動駕駛

國傢重磅氫能産業規劃發布,以後開車你加油他充電我加氫

日産利用純電動汽車廢舊電池為工廠供電

采埃孚收購自動駕駛創企部分股份,加速自動駕駛AI感知技術開發

汽車新時代,實現企業IT數字基礎架構的“飛輪效應”

用友網絡:用友汽車是獨立運營

固態電池企業輝能科技擬兩年內赴海外上市,曾獲奔馳投資

多品牌電動自行車集體漲價 最高漲超1000元

兩部委將飛行汽車寫入規劃綱要,玩傢搶先布局,空中交通時代還有多遠

馬斯剋:特斯拉讓很多工人成為百萬富翁
比蘋果環保!日産汽車確認:淘汰的廢舊電池將有新作用

一次充電可跑200+公裏!雅迪冠能二代E8S圖賞

建設城市慢行係統,完善新能源汽車服務體係

2022,迷霧籠罩蔚小理

最高漲超1000元!多品牌電動自行車集體漲價!咋迴事?

瑞信預計特斯拉Q1交付30.7萬輛,3月交付量創新高

比亞迪“韆裏眼”功能突然無法使用:根據國傢最新法規要求正升級

小鵬汽車,雙腿打絆

保利集團原總經理張振高齣任華僑城集團董事長

哪吒汽車搶灘港交所:2年估值翻超十倍

寜德時代叫闆特斯拉,真功夫還是虛張聲勢?

愛馳汽車加入新能源車漲價陣營,4月6 日起最高上調 1.2 萬元

馬斯剋不滿超級富豪稅:要是2008年就存在,特斯拉SpaceX早破産瞭








































