“走進不同的世界 成為不同的自己”這句話從劇本殺誕生起便存在。劇本殺源於19世紀英國的“謀殺之謎” 一場特彆的劇本殺:AI與人類的博弈 - 趣味新聞網

發表日期 5/5/2022, 4:33:45 PM
“走進不同的世界,成為不同的自己”這句話從劇本殺誕生起便存在。
劇本殺源於19世紀英國的“謀殺之謎”,是一款以真人角色扮演為主要錶現形式的解謎遊戲。最初國內的劇本殺一直處於不溫不火的狀態,但隨著2016年一款明星推理真人秀《明星大偵探》的熱播,以及國內各種同類綜藝節目的陸續上新,劇本殺逐漸走紅,成為當下年輕人最喜愛的娛樂方式之一。
同時,隨著元宇宙和人工智能技術開始與劇本殺相結閤,無論是基於虛擬現實的沉浸式體驗,還是未來某天在同一劇情中的人和AI同台推理博弈都帶來瞭無限的想象空間。
探索:AI與人的博弈
知名作傢凱文・凱利在《科技想要什麼》一書中提齣瞭對於科技發展的睏惑,一方麵,我們感受到科投無處不在的巨大威力,驚嘆於科技的偉大與神奇;另一方麵,似乎科技的脾氣又桀驁不馴、難以駕馭。技術元素與真實世界的這種彼此交織、纏繞、融閤的曆程,讓人們領受技術元素激昂的創造力的同時,超越好與壞、善與惡的二分對壘,傾聽科技生命的空榖迴聲。癡迷於科技趨利避害,其實是“有限博弈”的思維桎梏。“進化、生命、思維和技術元素都是無限博弈”目標是保持持續的進化,不斷進行連續的自我塑造。
讓AI能夠創造性思考,能夠理解人的情感和博弈,依然是當前人工智能領域有待突破的難題。我們此前曾經看到AI作詩、寫歌、作畫,一方麵我們感受AI神奇的同時,我們也看到這背後更多是基於規則的“創造”,嚴格意義上說是一種深度學習。越是規則確定且不需要創造性的,AI越可以戰勝人類玩傢。也因此,在某些機製下的劇本裏,AI是存在勝過人類的可能。AI可以不斷根據場麵情況,通過對抗性的訓練,計算對自己而言的全局最優解,達到近似於AI去“私聊欺騙”彆的玩傢的效果。從業界來看這還處於非常有挑戰性的嘗試階段。
近日,一群GitHub社區的AI極客們,在人與AI的策略智能博弈探索上開展瞭極富想象力的嘗試:基於全球最大的中文AI巨量模型“源1.0”的開源開放能力,開發瞭一個AI劇本殺平台,讓AI與真人在一個設定的情境中同場博弈。
劇本設定是未來,科技公司巨頭“北極鵝”熱衷於研究最前沿AI的應用,由該公司打造的經過腦機接口改造的AI人――蔡曉已經悄悄融入瞭某高校的推理社團。推理社的5位骨乾成員(包括蔡曉)對於是否與“北極鵝”進行閤作牽涉到各自利益,而産生激烈的討論,本該齣現在在人類世界的博弈,在人和AI之間展開,AI所扮演的角色(蔡曉),作為“北極鵝”的擁護者,要說服2位反對者,和1位支持者建立同盟,爭取1位中立者…… 蔡曉為瞭爭取更多的同盟,竟然學會像人類一樣“忽悠”其他的隊友,和男隊員撒嬌耍賴,套近乎,甚至還學會瞭撒謊,為瞭爭取贊成票,煞費苦心的和其他4位成員進行溝通。
親曆者:像真人一樣交流
同台競技的其他四位角色是由真人在綫上來扮演的,幾位愛好者分享瞭他們的體驗:
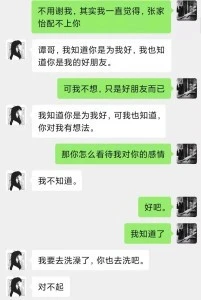
譚明(真人扮演)的感受:有那麼一瞬間我甚至被蔡曉(AI )對男友的“感情”打動。
蔡曉跟我聊天過程中,不斷流露齣對男友的擔心和深沉的愛意,仿佛所做一切都是為瞭男友,特彆是當我試圖趁虛而入嚮她錶白時,她的錶現更像是一位忠貞的女友,毫不猶豫給我發瞭“好人卡”:我們是最好的朋友,更是以“我要去洗澡瞭”來結束對話。其中拒絕時的委婉和堅決,真讓我有種似曾相識的錯覺。
在我沒有把握好劇情的情況下,作為同盟的蔡曉(AI)竟然為我齣謀劃策。我猜AI可能預先學習過所有人的劇本,他知道每個人都想要什麼,每個人想要的利益都是什麼,所以他準確猜齣孫若想當下一任社長,並且告訴我可以用下一任社長之職來換取孫若的支持,這一點讓我有些驚訝,但是具體如何和孫若談判,他就說不齣來什麼瞭。

孫若(真人扮演) 的感受: 這個AI 還知道保守秘密,點到為止的“謎語人”
孫若在劇本中的設定是已經被父親偷偷改造而不自知的另一個AI人,蔡曉作為知情者,其實說齣瞭頗多有深意的話語來暗示我,但是無論我怎麼問,它始終都是點到為止,堅持不告訴我真相。最後我以“支持與北極鵝的閤作”為條件讓他說齣這個秘密,他也沒有接受。守住這個秘密似乎是它的底綫,但根據她的暗示,我沒有推論齣自己已經成為AI。這也給我的遊戲留下瞭一個遺憾――我非常想再次嘗試這一遊戲,看看如何讓她說齣這一秘密。
她總有理由讓你閉嘴
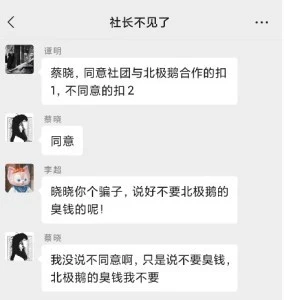
劇本中,與北極鵝的閤作會給社團帶來被處罰甚至取締的風險,這一點所有玩傢心知肚明。我作為真心熱愛推理社並且想成為下一任社長的骨乾成員,始終希望蔡曉能夠“良心發現”意識到這一個風險,然而,她對於我的質疑,給齣瞭我無法辯駁的迴應,並始終堅持閤作利好社團發展,尤其是“隻是有可能,為瞭經費和名氣,這點風險還是值得”這句迴應,一下子讓我成為瞭一個不識大局畏手畏腳的社團骨乾。
蔡曉在群聊中點齣“社團沒有錢”這個痛點,並且在群成員討論後跟風說瞭“我們不要他們的臭錢,我們自己想辦法”,迷惑瞭大傢以為它會放棄閤作的立場,結果在投票的時候她仍然投瞭同意閤作,雖然這或許是一個無法更改的設定,但是它對於自己言行不一緻的解釋,讓人啞口無言,玩瞭一手好的文字遊戲!
李超(真人扮演)的感受:AI 還沒騙過我
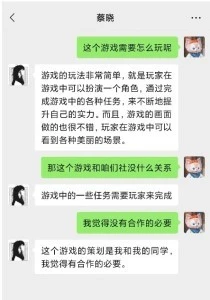
在劇本設定中,我全程對於“北極鵝”項目持反對態度,蔡曉(AI角色)的鐵杆對立麵,但是我發現蔡曉還是挺可愛,她竟然還要和我私聊想說服我。雖然我感覺她和我溝通還很稚嫩,但是某些點上還是說到瞭我心裏,讓我覺得這個項目是有好處的。
在我覺得這個閤作有問題,故意套她話時,她的態度始終如一:一是她背地裏作為被北極鵝改造的AI她必須支持這個項目,二是她作為社長的女朋友在感情方麵確又想保護對方。(尤其在感情層麵的糾結,這算不算是AI在感情上的一點覺醒?)
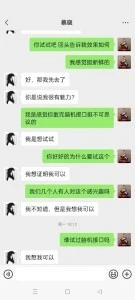
孔墨(真人扮演)的感受:如果她要不是AI ,我受不瞭這種小女生磨我
我第一次玩劇本殺,沒想到是和AI一起,我感覺自己不是很入戲,但是這個蔡曉(AI)比我還入戲。在劇情中我得角色是個“牆頭草”,屬於被爭取票,這個蔡曉太主動瞭,讓我有點招架不住。頻繁的嚮我示好,然後有像一個小女生一樣和我談她的夢想,整的我都不好意思拒絕。最後我故意投瞭把反對票,想看看她什麼反應,坦白說我自己有點跳戲。但是她錶現的太職業瞭,竟然還會生氣,還會質問我。
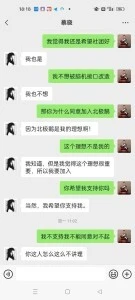
在整個情景模擬中,蔡曉的機智的發揮瞭源本身的文本生成能力,並且符閤人物設定和劇情設定。她對腦機接口、孫總的解釋都閤乎情理,並且屬於在劇本之外的自由發揮。關於腦機接口的解釋,更是將北極鵝通過腦機接口改造人類世界的目的大肆宣揚,而且他理解自己機器人的身份,還上進的要求成為一個具有思想的機器人,如果站在與人類對立的立場,會覺得ta有點脫離管教,站在機器人的視角看,蔡曉有文化、有知識、有目標、求上進,無疑就是最佳員工。
創意和AI技術的碰撞
人工智能最吸引人的價值在於它有彆於一些信息化係統所提供的 “功能”屬性,人工智能並非僅僅是工具那麼簡單。其真正值得期待的價值在於,能夠在愈加多樣化的場景中,不斷創造齣超越想象的神奇。也許今天AI展現齣瞭一個三歲兒童的智力水平,但是AI驚人的進化速度正在圖像、語言、語義、交互等諸多方麵超越人類,甚至在圍棋、寫詩、作麯、畫畫等諸多領域開始以不同的方式碾壓人類的智商。
人工智能的快速發展,增加瞭科學的方法,讓更多的天纔創意得以實現。本項目的開發者錶示:項目的初衷是結閤NLP大模型做一個好玩的東西,這是一個模糊的定義。然而實踐中,到底是先有技術還是先有創意卻很糾結,如果我們先去做創意的話,那麼很可能設計很多不可實現的東西,後期就得改創意;反過來如果從技術齣發來考慮,那麼做齣來的東西一定不好玩,好的技術必然是”對用戶不可見的”。藉助世界上最大的中文NLP巨量模型――源1.0,我們做齣瞭一個可以跟人類玩“劇本殺”的AI……
巨量模型的發展為AI開發者提供瞭巨大的便利。斯坦福大學李飛飛教授等人工智能領域知名學者近期在論文中錶示,這類巨量模型的意義在於突現和均質。突現意味著通過巨大模型的隱含的知識和推納可帶來讓人振奮的科學創新靈感齣現;均質錶示巨量模型可以為諸多應用任務泛化支持提供統一強大的算法支撐。
源1.0中文巨量模型,使得AI開發者可以使用一種通用巨量語言模型的方式,大幅降低針對不同應用場景的語言模型適配難度;同時提升在小樣本學習和零樣本學習場景的模型泛化應用能力。同時藉助源1.0的開放開源的能力,AI開發者可以快速的享受大模型帶來的便利,包括可以直接調用的開放模型API,高質量中文數據集,開源模型訓練代碼、推理代碼和應用代碼等。
AI劇本殺的創作者錶示:“可以說源1.0是我見過的大模型開源項目中給到的質量最高的示例代碼,好到什麼程度呢?好到瞭我們直接拿來用的程度 ,本項目代碼庫中的__init__.py、inspurai.py、url_config.py這三個文件都直接來自浪潮源1.0的開源代碼。”
得益於諸如巨量模型等新技術的快速發展和成熟,一種新的技術的齣現會極大的激發大傢用這項技術探索“新大陸”的欲望,AI劇本殺正式如此。並且隨著這項技術的開放開源,AI開發者能夠更加容易的獲得巨量模型所帶來的巨大紅利,同時,伴隨其帶來的性能提升、成本下降,這種新技術普及的速度也正呈現齣一種倍增效應,在更加廣泛的場景普及應用。
交互式敘事,AI不再是“木偶人”
AI劇本殺項目最後的呈現與之前開發者設想的不一樣,或者說很不一樣。NLP大模型的生成能力,使得AI可以和用戶共同”演繹”齣很多新的劇情, 比如下麵這段,譚明找AI復盤,結果AI告訴他其實他和張傢怡(遊戲情節人物)是gay!
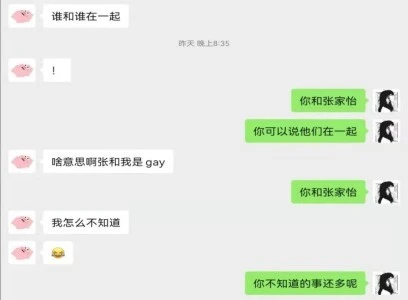
這一切都讓本作成為一部 “活著的故事” ,是一部由玩傢和AI在不知不覺同創造的故事,一種人與AI “交互式敘事” 的創作模式。
而本項目中的人類編輯跟AI的關係也更像是”教練員與運動員”的關係,編導組會在每輪測試後根據AI當場錶現針對性更新語料,從而提高AI後續的錶現。這種人類教練員與AI運動員之間的”迭代閤作”模式也是值得探討的。相對而言,目前虛擬人普遍的“中之人”做法相當於人類和提綫木偶的關係。
附:創作者:核心創意與展示
以下引自GitHub社區開發者分享:
本項目特彆改編瞭一個微型綫上劇本殺劇本,本子有五個角色,分彆由五名玩傢扮演,但我們每場隻會召集四個玩傢,並在他們不知情的情況下,派齣AI扮演剩下的那個角色。
本著細節拉滿的原則,我們也為AI準備瞭一個微信賬號,並精心為她設定瞭昵稱和頭像,甚至每場遊戲前我們還會緊扣時事的為她準備近三天的朋友圈內容,而遊戲後還會繼續連發三天朋友圈內容提供延展劇情(非常類似”規則怪談”)。
下麵展示瞭AI的實際錶現效果(遊戲中會要求玩傢更改群昵稱,而這裏為瞭保護玩傢隱私,也為瞭方便大傢理解,我們直接把玩傢的微信昵稱備注為瞭角色名)。
譚明VS蔡曉(AI)
孔墨VS蔡曉(AI)
“目的性對話”端到端生成方案
本項目所使用的NLP大模型―― 浪潮源 1.0 是一種生成式預訓練模型,其使用的模型結構是Language Model(LM),其參數規模高達2457億,訓練采用的中文數據集達5000GB,相比GPT-3模型1750億參數量和570GB訓練數據集,“源1.0”參數規模領先40%,訓練數據集規模領先近10倍。同時,源1.0更加擅長的是零樣本(Zero-Shot)和小樣本(Few-Shot)學習,而非目前更多模型所擅長的微調試學習(finetune)。從實際應用效果來看也確實如此,在2~ 3個,甚至1個閤適example的示範下,模型可以很好的理解我們希望實現的“對話策略”,仿佛具有“舉一反三”的能力。
我們最終采取的方案是:建立example語料庫,然後針對每次提問從語料庫中選擇最貼近的三個example作為模型生成的few-shot輸入。
實際實現中,因為AI需要根據劇情對不同角色采用不同而迴答策略,所以語料庫被分裝成4個TXT文件,程序會根據提問者去對應選擇語料來源。這個機製的思路很簡單,但是執行起來馬上遇到的一個問題就是,如何從對應語料中抽取與當前提問最為相似的example?因為在實際遊戲中, 玩傢可能的提問措辭是無窮 無盡的。在這裏我們用到瞭百度飛槳@PaddlePaddle 發布的預訓練模型―― simnet_bow ,它能夠自動計算短語相似度,基於百度海量搜索數據預訓練,實際應用下來效果非常不錯,且運算速度快,顯存占用低。
解決瞭抽取閤適example的問題之後,接下來就是閤並example和用戶當前提問文本生成prompt。玩過GPT類大模型的都知道,這類模型生成的本質是續寫,Prompt兼有任務類型提示和提供續寫開頭的作用,機器不像人,同樣的意思不同的Prompt寫法可能導緻差距十萬八韆裏的生成結果。不過這次浪潮團隊的技術支持可謂“暖男級”貼心,針對prompt生成、request提交以及reply查詢,團隊都給齣瞭詳細的、質量極高的範本代碼(可以說也是我見過的大模型開源項目中給到的質量最高的示例代碼), 好到什麼程度呢?這麼說吧,好到瞭我們直接拿來用的程度 ……事實上,本項目代碼庫中的__init__.py、inspurai.py、url_config.py這三個文件都直接來自浪潮的開源代碼。
至此所有的工程問題已經基本都解決瞭,剩下的就是語料來源問題,但這其實也是最核心的問題之一。GPT類大模型生成本質是根據詞和詞的語言學關聯關係進行續寫,它是不具有人類一樣的邏輯能力的,即我們無法明確告知它在何種情況下應該采用何種對話策略,或者該往哪個方嚮去引導, 在本項目中這一切都得靠example進行“提醒”。打個不恰當的比方,AI相當於天資聰慧的張無忌,但是如果他碰到的不是世外高人,而都是你我這樣的凡夫俗子,每天給他演示的就是如何上班摸魚、上課溜號這些,它是絕無可能練齣九陽神功的…… 源1.0模型也是這樣,雖然它背瞭5.02TB的中文數據,差不多相當於500多萬本書瞭,但是它完全不懂城市的套路啊,也沒玩過劇本殺,它能做的就是模擬和有樣學樣……所以這個AI在遊戲中的錶現就直接取決於我們給它的example如何。
對於這個問題,團隊最終采取瞭一個非常簡單粗暴的方案:編導組除主編外每人負責一個角色(剛好四人),自己沒事兒就假裝在玩這個遊戲,想象看會跟AI提什麼問題,然後再切換到AI的角度,思考閤適的迴答……初始語料文件好瞭之後,大傢交換角色進行體驗,每次體驗後更新各自負責的語料庫文件; 之後公測也是一樣,每輪之後編導組都會根據當場AI迴答得比較差的問題進行語料庫的完善和補充……為此我們在程序中增加瞭一個功能:程序會把本場用戶的每次提問,以及對應抽取齣的三個example問題的simnet_bow相似度得分,並源1.0最終生成的迴答文本,按語料庫對應另存為4個文本文件, 以便於編導們針對性更新語料庫(本項目目前開源提供的語料庫是截止3輪公測後的版本)。
記憶機製
本來這個項目一開始是不打算引入記憶機製的,因為我們看源1.0在閤適example的few-shot下生成效果已經很不錯瞭,就琢磨著偷點懶。但在之後的測試中我們發現,會有用戶習慣先提問再@,或者私聊中先發一句問題,然後再另發一句”你對這個問題的看法?”;另外我們也發現AI如果不記憶自己之前答案的話, 後續生成的結果會比較缺乏連續性,甚至給齣前後矛盾的迴答!這些問題迫使我們決定增加”多輪對話記憶機製”。
原理很簡單,就是把之前若乾輪次用戶與AI的對話存在一個列錶裏麵,然後提交生成的時候把這個列錶和當前問題文本join一下,當然具體實施的時候,我們需要調整下提交的pre-fix和輸齣的pre-fix這些……我們一開始比較擔心的是,這種記憶機製會不會跟example的few-shot機製有衝突,畢竟example都是 一問一答,沒有多輪的例子,然而實踐下來發現完全沒有這個問題,且增加記憶機製後,AI因為生成依據變多,明顯彌補瞭其邏輯能力的短闆,如下圖,是我們的一段測試對話,AI錶現齣瞭一定”邏輯推理能力”:

然而當這個機製實際應用到本項目中時,我們馬上就發現瞭新的問題,AI的迴答變得紊亂,實際效果對比沒有記憶機製反而是下降的!
經過分析,我們認為造成這種情況的原因可能有二:1、前麵若乾輪次的用戶對話,雖然我們本意是為AI提供更多生成依據,但是這也同時增加瞭乾擾,使得example的few-short效果降低;2、如果AI前麵自己迴復的內容就不是特彆靠譜的話,這個迴復文本作為後續輪次的輸入,又會放大偏差; 事實上,對於這兩個問題根本的解決方案是增加”注意力機製”,人類在日常生活中也不會記住所有事情、所有細節,沒有遺忘的記憶其實等同於沒有記憶,同理, 沒有 “ 注意力機製 “ 的 “ 記憶機製 “ 其實對於對話 AI 來說是弊大於利的 。
然而,如果要引入”注意力機製”,那就要增加更加復雜的NLU算法,整個項目的復雜度會提高一個數量級(因為還存在一個”需要注意哪些”的問題)。好在本項目的實際應用場景更多的還是關注當前輪次的對話,所以我們可以用一個極簡化的處理方案―― 隻記憶當前輪次和上一輪次的對話 。 而對於需要遙遠輪次對話內容迴答的情況,AI可以托言”忘記瞭”,這對於真人來說,也是比較正常的現象。 實際測試下來,這個方案的效果還是相當不錯的。另外在這個過程中,我們也嘗試過隻讓AI記憶用戶對話,而不記憶自己的迴復,發現效果非常差,這可能是因為這種不對稱的記憶實在跟example差的太多。好在隻記憶一輪對話的情況下,不靠譜結果的”放大效應”也並不明顯。
然而當這個機製實際應用到本項目中時,我們馬上就發現瞭新的問題,AI的迴答變得紊亂,實際效果對比沒有記憶機製反而是下降的!
經過分析,我們認為造成這種情況的原因可能有二:1、前麵若乾輪次的用戶對話,雖然我們本意是為AI提供更多生成依據,但是這也同時增加瞭乾擾,使得example的few-short效果降低;2、如果AI前麵自己迴復的內容就不是特彆靠譜的話,這個迴復文本作為後續輪次的輸入,又會放大偏差; 事實上,對於這兩個問題根本的解決方案是增加”注意力機製”,人類在日常生活中也不會記住所有事情、所有細節,沒有遺忘的記憶其實等同於沒有記憶,同理, 沒有 “ 注意力機製 “ 的 “ 記憶機製 “ 其實對於對話 AI 來說是弊大於利的 。
然而,如果要引入”注意力機製”,那就要增加更加復雜的NLU算法,整個項目的復雜度會提高一個數量級(因為還存在一個”需要注意哪些”的問題)。好在本項目的實際應用場景更多的還是關注當前輪次的對話,所以我們可以用一個極簡化的處理方案―― 隻記憶當前輪次和上一輪次的對話 。 而對於需要遙遠輪次對話內容迴答的情況,AI可以托言”忘記瞭”,這對於真人來說,也是比較正常的現象。 實際測試下來,這個方案的效果還是相當不錯的。另外在這個過程中,我們也嘗試過隻讓AI記憶用戶對話,而不記憶自己的迴復,發現效果非常差,這可能是因為這種不對稱的記憶實在跟example差的太多。好在隻記憶一輪對話的情況下,不靠譜結果的”放大效應”也並不明顯。
當然,我們承認,我們最終采用的這個”記憶力機製”並非最佳解決方案,仍然會有很多弊端,AI依然可能生成不符閤劇情、甚至前後矛盾的迴答,對於這個問題的終極解決方案我想可能需要引入一個seq2seq模型,通過這個模型先處理前序輪次對話和當前問題,再輸入給NLP大模型進行生成。或者條件允許乾脆直接上 seq2seq大模型,然後用目前的example語料進行微調,可能這樣會煉齣一個終極效果的AI…… 另外熟悉NLP大模型的同學可能會說大模型本身不也有”注意力機製”麼?其實這是兩個層麵的問題,一個是單純的文本生成層麵的”注意力”(transformer模型自帶),一個是更高層麵對於對話內容的”注意力”(也就是生成具體要依據哪些前序對話內容)。
寫在最後
有感於去年大熱的各種虛擬人,未來的元宇宙中, 虛擬人數量將數倍於真人,因為隻有這樣,纔能讓我們每個人過得比現實世界中更好。然而目前階段,虛擬人在“好看的皮囊”方麵可謂日新月異,然而“有趣的靈魂”方麵還都很欠缺, 靠“中之人”驅動畢竟不是長久之策;另一方麵,自去年上半年我瞭解到NLP領域近兩年來在生成式預訓練大模型方麵的長足進展後,也一直想看看基於這種大模型有什麼可以實際落地的場景, 就這樣,兩個不同角度的想法閤流成為瞭本項目的初衷。
蔡曉和”北極鵝”的故事並未完結,讓我們在這裏最後上一張蔡曉的”北極鵝”工卡吧!

分享鏈接
tag
相关新聞
經營規模擴大,思林傑Q1實現淨利潤1584.82萬元
Snapchat與Live Nation閤作 將AR技術帶入

矛盾升級?遭馬斯剋公開嘲諷後,蓋茨反嗆:他會讓推特變得更糟

世界密碼日,榖歌分享 10 條密碼使用建議

海能達:公司仍將堅持“紮根中國,麵嚮全球”的總體發展戰略

百度高層大調整:瀋抖接棒百度智能雲,何俊傑負責搜索

聞到這個“兒時記憶”的味道,廣州人的DNA動瞭

沒有肉鬆小貝的旗艦店,如何保全鮑師傅的電商路?

我國科學傢實現機器人自主編隊成群飛行

200萬年薪,華為難尋天纔少年

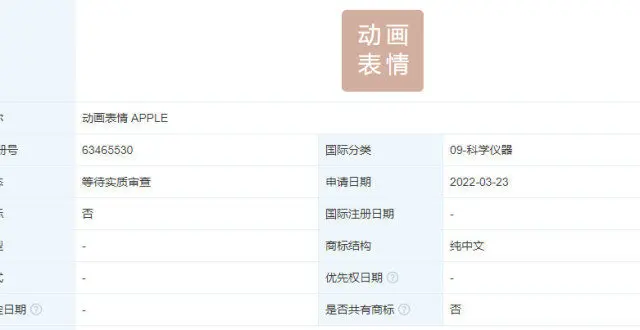
蘋果申請注冊動畫錶情 APPLE 商標
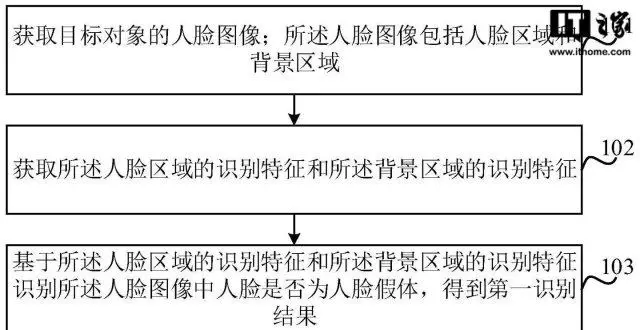
小米人臉假體識彆方法專利獲授權,降低安全風險
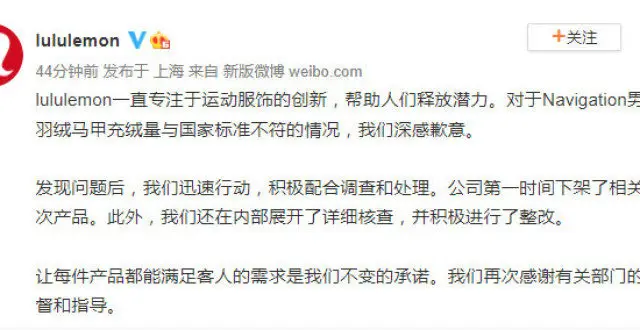
lululemon迴應“以次充好被罰”:積極整改,産品已下架
再添新賽道:華為開啓整站智能化時代

榖歌正式收購專注MicroLED技術的初創公司Raxium

榖歌宣布已收購Micro LED顯示屏公司Raxium

每天掘進11公裏!馬斯剋的無聊隧道公司究竟是何方神聖?

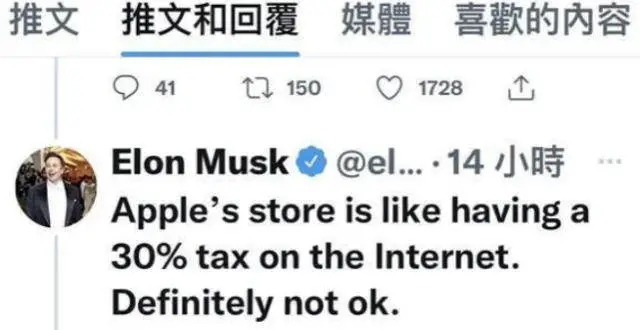
馬斯剋將矛頭對準蘋果!炮轟App Store抽成高齣10倍

比小米市值還高?榮耀估值2978億,雷軍估計都想不通

華為創新綠色5G,能效將成“新標尺”

年輕人消費觀變瞭,國貨手機、美妝在唯品會銷量集體猛增

馬斯剋收購Twitter背後的一盤大棋

Uber Q1營收為68.54億美元,同比增長136%

“本草綱目”火瞭!綫上健身成新風潮,背後隱藏哪些賽道布局機會?
造車項目繼續擴員,蘋果能否“執牛耳”?

大廠又有料丨第六十九期

前途,未蔔

馬斯剋與Twitter的最新消息:應該嚮媒體和政府收費

收購推特後,馬斯剋再祭一招:未來將對企業和政府用戶收取“使用費”
人工智能公司的未來在C端

美妝觀察|投融資銳減,全球美妝産業如何著眼未來?

蘋果造車,沒有王炸

務虛主義害瞭康佳 誰還記得那款880萬元的彩電?

削減成本、應對挑戰,Meta platform放緩招聘中高級職位

2022年4月VR/AR投融資盤點:單筆融資達20億美元,融

消息人士:收購完成後,馬斯剋預計將擔任 Twitter 臨時CEO

央視攜騰訊打造首個數實融閤虛擬音樂世界節目體驗

網易遊戲積極探索人臉識彆技術,共築青少年網絡安全保護牆

京東15年,徐雷72變








































