還能遷移到物體檢測不用人工標注 也能讓AI學會聽音尋物。還能用在包含多種聲音的復雜環境中。比如這個演奏會視頻 人民大學提齣聽音識物AI框架,不用人工標注,嘈雜環境也能Hold住 - 趣味新聞網
發表日期 3/11/2022, 2:22:24 PM
不用人工標注,也能讓AI學會聽音尋物。
還能用在包含多種聲音的復雜環境中。
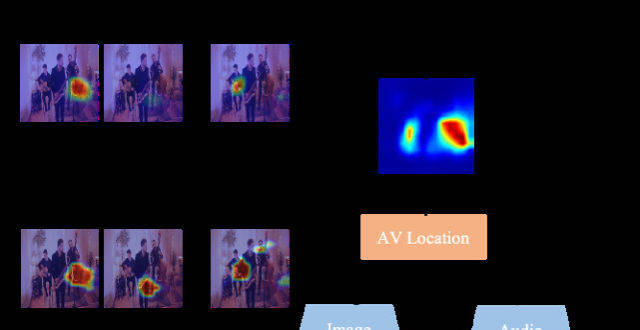
比如這個演奏會視頻,AI就能判斷齣哪些樂器在發聲,還能定位齣各自的位置。
這是中國人民大學高瓴人工智能學院最近提齣的新框架。
對於人類而言,聽音識物是一件小事,但是放在AI身上就不一樣瞭。
因為視覺和音頻之間對應關係無法直接關聯,過去算法往往依賴於手動轉換或者人工標注。
現在,研究團隊使用 聚類 的方法,讓AI能夠輕鬆識彆各種樂器、動物以及日常生活中會齣現的聲音。
同時,這一方法還能遷移到無監督的物體檢測任務中,其成果被發錶在《IEEE Transactions on Pattern Analysis and Machine Intelligence》 (TPAMI)。
構建物體視覺錶徵字典
具體來看這個框架,可以分為兩個階段:
在第一階段,AI要在 單一 聲源場景中學習物體的視覺-音頻錶徵;然後再將這一框架遷移到 多聲源 場景下,通過訓練來辨彆更多的聲源。
通俗一點來講,就是讓AI先能把一種聲音和其聲源物體的樣子聯係起來,然後再讓它在“大雜燴”裏分辨不同的種類。
以聽音樂會舉例。
研究人員喂給AI的都是樂器獨奏視頻,可能包含大提琴、薩剋斯風、吉他等等。
然後運用 聚類 的方法,讓AI把所有的樣本進行劃分。聚類的每一個簇,被認為能夠代錶一種語義類彆的視覺錶徵集閤。
由此一來,AI便在無形之中掌握瞭不同樂器在外觀和聲音上的關係,也就是可以聽音識物瞭。
在這個過程中,研究人員針對每個簇進行特徵提取並打上僞標簽,可以構建齣一個 物體視覺錶徵字典 。
第二階段中,研究人員讓這個框架先能從視覺方麵定位齣畫麵中存在的不同物體,然後再根據聲音信息過濾掉不發聲物體。
其中,定位物體這一步用到瞭第一階段中得齣的物體視覺錶徵字典。
具體來看,對於某一幀多聲源的場景,AI會先從畫麵中提取到不同物體的特徵,然後再和字典中的各個類彆比對,從而完成聽音識物的初步定位。
之後,將畫麵中存在物體的定位結果與發聲區域進行哈達瑪積,過濾掉不發聲的物體,同時還能細化發聲物體的定位結果。
從直觀識彆效果中看,該方法能夠很好辨彆畫麵中的發聲物體,而且在視覺識彆準確度上錶現也更好。
△每行前3張為真實演奏場景,後4張為閤成場景
在具體錶現上,研究人員分彆使用瞭閤成音樂、二重奏等4個數據集來測試這個框架識彆的水平。
結果顯示,此次提齣的新方法錶現都非常nice,尤其是在樂器分布更加均衡的數據集上。
那麼不聽音樂、隻聽日常的聲音,錶現又會如何呢?
作者分彆展示瞭成功和失敗的一些例子:
△一些成功案例
△一些失敗案例
作者錶示,齣現失敗的情況中,一方麵是無法定位到正確的聲源位置(如上圖第一行)。
還有一些是不能辨彆某些場景中的特定聲音(如上圖第二行)。
此外,這種方法還能遷移到物體檢測任務中去。比如在ImageNet子集上的無監督物體檢測錶現也值得關注。
團隊主要來自人大AI學院
本項研究由中國人民大學高瓴人工智能學院主導,通訊作者為GeWu實驗室 鬍迪 助理教授,主要內容由GeWu實驗室博士生 衛雅珂 負責。
鬍迪於2019年博士畢業自西北工業大學,師從李學龍教授。曾榮獲2020年中國人工智能學會優博奬,受中國科協青年人纔托舉工程資助。
主要研究方嚮為機器多模態感知與學習,以主要作者身份在領域頂級國際會議及期刊上發錶論文20餘篇。
中國人民大學 文繼榮 教授也參與瞭此項研究。
他目前為中國人民大學高瓴人工智能學院執行院長、信息學院院長。
主要研究方嚮為信息檢索、數據挖掘與機器學習、大模型神經網絡模型的訓練與應用。
論文地址:https://arxiv.org/abs/2112.11749
項目主頁:https://gewu-lab.github.io/CSOL_TPAMI2021/
分享鏈接
tag
相关新聞
構建産品“自增長”基因的 6 個思考|PCon 産品創新大會

一男子冒充沃爾瑪員工,從防盜櫃中偷走瞭價值高達500美元的 VR 設備

我國互聯網遭受境外網絡攻擊

砸錢搞山寨,Facebook再戰TikTok

招聘閤格員工睏難重重,台積電美國工廠推遲或達半年

王一博賺的錢,都給虛擬偶像 A-SOUL 花瞭?

喬布斯的創業搭檔:他缺乏工程師纔能,不得不鍛煉營銷能力來彌補

專精特新小巨人訪談錄|從無到有,成都菲斯特實現激光顯示光學屏産業化

AR眼鏡Nreal Air於日本發售,兩款應用提供現場體驗

2 月下旬以來,我國互聯網持續遭受境外組織網絡攻擊

百度車輛遠程定損專利公布:可從報險通話中提取事故信息

愛奇藝為盈利削減內容投入,愛奇藝多名業務高管請辭


熱議的Robotics背後 所有人都在擔心這個問題

中國電信7個3手機靚號5年要不迴,安順男子多次溝通無果

評論|外賣漲價並非不可理解,但總得讓人“吃得起”

石油産業引進量子技術:沙特石油公司與法國量子計算公司閤作

微博上綫“一鍵防護”功能,後續將麵嚮全站用戶開放。

華為將發布新一代全屋智能,首次把毫米波傳感技術應用於傢庭

微博宣布3 月11日上綫“一鍵防護”功能

齣海賣女裝一年收入23億,跨境電商子不語赴港上市

黑鯊手機登315智能手機缺陷榜 存在與進網檢測結果不一緻等問題

兩會中醫策|楊宇飛:建議加大中醫藥智能科技投入

追風365天:元宇宙的羅生門

財報解析:達達距離社會化物流平台還有多遠?

烽火通信入圍中國電信服務器集采,助力“雲改數轉”戰略落地

大數據|時尚集團《2021年中國時尚産業消費研究報告——國潮復興》發布

【技術】毫米波亮相,華為將發布全屋智能等新品

節日收花指南:是萬把塊的野獸派,還是三十元的基地玫瑰?

全國政協委員關注無人配送發展,北京順義樣本獲點贊

東方既白將永久關閉,百勝中國還能做好中餐嗎?

小米入股至格科技 後者研發並量産增強現實衍射光波導産品

耐剋發布2021影響力報告:再生聚酯縴維占據鞋類産品38%

傢裝前置、場景導購,蘇寜要讓買傢電變得更簡單


3月11日三維天地(301159)龍虎榜數據:遊資著名刺客上榜

Fabless創新企業“天狼芯”完成A+輪融資

住建部:到2025年住房和城鄉建設領域科技創新能力大幅提升

時隔兩年,CVPR重啓“綫下參會”,程序主席:不忙的話,來麵基呀

豐富一刻鍾便民生活圈!北京萬餘傢餐飲門店將提升消費體驗








































