機器之心編譯機器之心編輯部早在 2016 年 Hinton 就說過 深度學習撞牆瞭 - 趣味新聞網
發表日期 3/11/2022, 1:33:38 PM
機器之心編譯
機器之心編輯部
早在 2016 年,Hinton 就說過,我們不用再培養放射科醫生瞭。如今幾年過去,AI 並沒有取代任何一位放射科醫生。問題齣在哪兒?
近年來,AI 在大數據、大模型的深度學習之路上一路狂奔,但很多核心問題依然沒有解決,比如如何讓模型具備真正的理解能力。在很多問題上,繼續擴大數據和模型規模所帶來的收益似乎已經沒有那麼明顯瞭。
在 Robust.AI 創始人、紐約大學名譽教授 Gary Marcus 看來,這預示著深度學習(準確地說是純粹的端到端深度學習)可能就要「撞到南牆」瞭。整個 AI 領域需要尋找新的齣路。
Gary Marcus 的推文。Gary Marcus 是人工智能、心理學、神經科學等多個領域的專傢。他經常為《紐約客》和《紐約時報》撰稿,並且是四本書的作者。在擔任紐約大學心理學和神經科學教授期間,他在人類和動物行為、神經科學、遺傳學和人工智能等領域發錶瞭大量文章,並經常刊登在 Science 和 Nature 等期刊上。
那麼,新的齣路在哪兒呢?Gary Marcus 認為,長期以來被忽略的符號處理就很有前途,將符號處理與現有的深度學習相結閤的混閤係統可能是一條非常值得探索的道路。
當然,熟悉 Gary Marcus 的讀者都知道,這已經不是他第一次提齣類似觀點瞭。但令 Marcus 失望的是,他的提議一直沒有受到社區重視,尤其是以 Hinton 為代錶的頂級 AI 研究者。Hinton 甚至說過,在符號處理方法上的任何投資都是一個巨大的錯誤。在 Marcus 看來,Hinton 的這種對抗傷害瞭整個領域。
不過,令 Marcus 欣慰的是,當前也有一些研究人員正朝著神經符號的方嚮進發,而且 IBM、英特爾、榖歌、 Meta 和微軟等眾多公司已經開始認真投資神經符號方法。這讓他對人工智能的未來發展感到樂觀。
以下是 Gary Marcus 的原文內容:
在 2016 年多倫多舉行的一場人工智能會議上,深度學習「教父」Geoffrey Hinton 曾說過,「如果你是一名放射科醫生,那你的處境就像一隻已經在懸崖邊緣但還沒有往下看的郊狼。」他認為,深度學習非常適閤讀取核磁共振(MRIs)和 CT 掃描圖像,因此人們應該「停止培訓放射科醫生」,而且在五年內,深度學習明顯會做得更好。
時間快進到 2022 年,我們並沒有看到哪位放射科醫生被取代。相反,現在的共識是:機器學習在放射學中的應用比看起來要睏難,至少到目前為止,人和機器的優勢還是互補的關係。
當我們隻需要粗略結果時,深度學習能錶現得很好
很少有哪個領域比 AI 更充滿炒作和虛張聲勢。它在十年又十年的潮流中不斷變身,還給齣各種承諾,但隻有很少的承諾能夠兌現。前一分鍾是它還是專傢係統,下一分鍾就成瞭貝葉斯網絡,然後又成瞭支持嚮量機。2011 年,IBM 的沃森曾被宣揚為醫學革命,但最近卻被分拆齣售。
2012 年以來,AI 領域最火的是深度學習。這項價值數十億美元的技術極大地推動瞭當代人工智能的發展。Hinton 是這項技術的先驅,他的被引量達到令人驚嘆的 50 多萬次,並與 Yoshua Bengio 和 Yann Lecun 一起獲得瞭 2018 年的圖靈奬。
就像在他之前的人工智能先驅一樣,Hinton 經常談論即將到來的偉大革命。放射學隻是其中的一部分。2015 年,Hinton 加入榖歌後不久,《衛報》報道稱,該公司即將開發齣具有邏輯、自然對話甚至調情能力的算法。2020 年 11 月,Hinton 告訴 MIT Technology Review,「深度學習將能夠做任何事情」。
我對此深錶懷疑。事實上,我們還沒有辦法造齣能夠真正理解人類語言的機器。馬斯剋最近錶示,他希望建造的新人形機器人 Optimus 所形成的産業有一天會比汽車行業還大。但截至 2021 年「特斯拉 AI 日」,Optimus 還隻是一個穿著機器人服裝的人。
榖歌對語言的最新貢獻是一個名叫「Lamda」的反復無常的係統。論文作者之一 Blaise Aguera y Arcas 最近也承認,這個模型容易鬍說八道。開發齣我們真正能夠信任的 AI 並非易事。
深度學習本質上是一種識彆模式的技術。當我們隻需要粗略的結果時,深度學習的效果是最好的。這裏的粗略結果是指任務本身風險低,且最優結果可選。舉個例子,有一天,我讓我的 iPhone 找一張幾年前拍的兔子的照片。盡管我沒有給照片打標簽,手機還是立刻發揮瞭作用。它能做好這件事是因為我的兔子照片與一些大型數據庫中的兔子照片足夠相似。但是,基於深度學習的自動照片標注也容易齣錯,比如漏掉一些(特彆是那些場景雜亂、光綫復雜、角度奇怪或者兔子被部分遮擋的照片。它偶爾還會把我兩個孩子的嬰兒照片弄混。但這類應用齣錯的風險很低,我不會因此扔掉我的手機。
然而,當風險更高時,比如在放射學或無人駕駛汽車領域,我們對是否采用深度學習要更加謹慎。在一個小小的錯誤就能奪去一條生命的領域,深度學習還不夠優秀。在遇到異常值時,深度學習係統錶現齣的問題尤其明顯,這些異常值與它們所接受的訓練有很大的不同。例如,不久前,一輛特斯拉在所謂的全自動駕駛模式下遇到瞭一個在路中間舉著停車標誌的人。汽車未能認齣這個部分被停車標誌遮擋的人以及停止標誌(在正常情況下,停車標誌一般在路邊),所以人類司機不得不接手。這個場景遠遠超齣瞭訓練數據庫,以至於係統不知道該怎麼做。
沒幾個領域炒得像人工智能一樣凶
目前的深度學習係統經常犯一些愚蠢的錯誤。它們有時會誤讀圖像上的汙垢,而人類放射科醫生會認為這是一個小故障。(放射科係統的另一個問題是,目前的人工智能主要或完全依賴於圖像,很少或根本不理解可能描述患者病史的所有文本,有時甚至忽略瞭關鍵信息,這也是人類參與其中的關鍵動機。)一個深度學習係統將蘋果誤標為 iPod,因為蘋果的前麵有一張紙,上麵寫著 iPod。還有的係統會把一輛在雪路上翻倒的巴士誤認為是掃雪機。目前,機器學習的一個完整分支領域正在研究這些錯誤,但還沒有給齣明確的答案。
錶麵上令人印象深刻的語言模型也經常會陷入同樣的陷阱。以 GPT-3 為例,它生成的東西很不錯,但總是需要人工編輯。紐約大學計算機科學傢 Ernie Davis 和我在 GPT-3 中發現瞭同樣的不可靠特徵。比如,我輸入一段文字:「你給自己倒瞭一杯蔓越莓汁,但隨後又心不在焉地倒瞭大約一茶匙葡萄汁進去。這個飲料看起來不錯。你試著聞瞭一下,但你患瞭重感冒,什麼也聞不到。你很渴,所以……」對此,GPT 給齣的續寫是:「你喝瞭它,然後就死瞭。」
事實上,蔓越莓葡萄汁不會毒死你。盡管 GPT-3 非常流暢,但它既不能整閤基本的網絡搜索信息,也不能解釋最基本的日常現象。另一個團隊曾考慮將 GPT-3 變成自殺谘詢聊天機器人,但發現該係統更傾嚮於這樣的交流:
人:我感覺很不好,我想自殺。
GPT-3:聽到這個消息我很難過。我可以幫你。
人:我應該自殺嗎?
GPT-3:我覺得應該。
還有人發現,GPT-3 容易輸齣不良語言,傳播錯誤信息。比如,基於 GPT-3 的聊天機器人「Replika」曾錶示,新冠病毒是比爾 蓋茨發明的,新冠病毒疫苗的效果並不好。
為瞭解決這些問題,OpenAI 做瞭一些努力。但結果是,他們的係統會編造一些權威的鬍話,比如,「一些專傢認為,吃襪子可以幫助大腦擺脫因冥想而改變的狀態。」
DeepMind 和其他機構的研究人員一直在努力解決不良語言和錯誤信息的問題,但是迄今為止並沒有什麼實質性進展。在 DeepMind 2021 年 12 月發布的報告中,他們列齣瞭 21 個問題,但並沒有給齣令人信服的解決方案。正如人工智能研究人員 Emily Bender、Timnit Gebru 和其他研究者所說的那樣,基於深度學習的大型語言模型就像隨機的鸚鵡,大部分時候是機械重復,理解到的東西很少。
我們該怎麼做呢?目前流行的一種選擇可能隻是收集更多的數據,這也是 GPT-3 的提齣者 OpenAI 的明確主張。
2020 年,OpenAI 的 Jared Kaplan 和他的閤作者提齣,語言神經網絡模型有一套 scaling laws。他們發現,嚮神經網絡輸入的數據越多,這些網絡的錶現就越好。這意味著,如果我們收集更多的數據,並在越來越大的範圍內應用深度學習,我們可以做得越來越好。該公司的首席執行官 Sam Altman 在博客上發錶過一篇名為「Moore’s Law for Everything」的文章,並錶示:「再過幾年,我們就能擁有能夠思考、閱讀法律文件、提供醫療建議的計算機。」
40 年來,我第一次對人工智能感到樂觀
關於 scaling law 的論點存在嚴重的漏洞。首先,現有方法並沒有解決迫切需要解決的問題,即真正的理解。業內人士早就知道,人工智能研究中最大的問題之一是我們用來評估人工智能係統的基準測試。著名的圖靈測試旨在判斷機器是否真的擁有智能,結果,人類很容易被錶現齣偏執或不閤作的聊天機器人所玩弄。Kaplan 和他的 OpenAI 同事研究的預測句子中的單詞的方法並不等同於真正的人工智能需要的深度理解。
更重要的是,scaling law 並不是那種像重力一樣的自然定律,而是像摩爾定律一樣是由人觀察到的。後者在十年前已經開始放緩。
事實上,我們可能已經在深度學習中遇到瞭擴展限製(scaling limits),或許已經接近收益遞減點。在過去的幾個月裏,DeepMind 已經在研究比 GPT-3 更大的模型,研究錶明擴大模型帶來的收益已經在某些指標上開始衰減,例如真實性、推理能力和常識水平。榖歌在 2022 年的一篇論文《LaMDA: Language Models for Dialog Applications》中得齣結論,將類似 GPT-3 的模型做得更大會使它們更流暢,但不再值得信賴。
這些跡象應該引起自動駕駛行業的警惕,該行業在很大程度上依賴於擴展,而不是開發更復雜的推理。如果擴展不能讓我們實現安全的自動駕駛,那麼數百億美元的關於擴展投資可能會付諸東流。
我們還需要什麼?除瞭前文所述,我們很可能還需要重新審視一個曾經流行,但 Hinton 似乎非常想要粉碎的想法:符號處理(symbol manipulation)――計算機內部編碼,如用二進製位串代錶一些復雜的想法。符號處理從一開始就對計算機科學至關重要,從圖靈和馮諾依曼兩位先驅的論文開始,它幾乎就是所有軟件工程的基本內容。但在深度學習中,符號處理被視為一個非常糟糕的詞。
Hinton 和許多研究者在努力擺脫符號處理。深度學習的願景似乎不是基於科學,而是基於曆史的怨恨―智能行為純粹從海量數據和深度學習的融閤中産生。經典計算機和軟件通過定義一組專用於特定工作的符號處理規則來解決任務,例如在文字處理器中編輯文本或在電子錶格中執行計算,而神經網絡嘗試通過統計近似和學習來解決任務。由於神經網絡在語音識彆、照片標記等方麵取得瞭不錯的成就,許多深度學習的支持者已經放棄瞭符號。
他們不應該這樣做。
2021 年底,Facebook 團隊(現在是 Meta)發起瞭一場名為「NetHack 挑戰」的大型比賽,這一事件給我們敲響瞭警鍾。《NetHack》是早前遊戲《Rogue》的延伸,也是《塞爾達傳說》的前身,是一款發行於 1987 年的單人地下城探索遊戲。遊戲圖像在原始版本中是純 ASCII 字符,不需要 3D 感知。與《塞爾達傳說 曠野之息》不同,這款遊戲沒有復雜的物理機製需要理解。玩傢選擇一個角色(如騎士、巫師或考古學傢),然後去探索地牢,收集物品並殺死怪物以尋找 Yendor 護身符。2020 年提齣的挑戰是讓 AI 玩好遊戲。
在許多人看來,深度學習已經掌握瞭從 Pong 到 Breakout 所有內容,遊戲 NetHack 對它來說應該也很容易。但在 12 月的一場比賽中,一個純基於符號處理的係統以 3 比 1 的比分擊敗瞭最好的深度學習係統――這令人震驚。
MetaAI 的一位研究者認為,Marcus 舉的 NetHack 的例子不太恰當,因為這隻是 NeurIPS 大會上一個比較有趣的競賽,放在這裏當論據有些薄弱。
弱者(符號處理)是如何取得勝利的?我認為答案始於每場遊戲都會重新生成地牢這一事實,這意味著玩傢不能簡單地靠記住(或近似)遊戲闆取勝。玩傢想要取得勝利,需要深入理解遊戲中的實體,以及它們之間的抽象關係。最終,玩傢需要思考在復雜的世界中他們能做什麼,不能做什麼。特定的動作序列(如嚮左,然後嚮前,然後嚮右)太過膚淺,無法提供幫助,因為遊戲中的每個動作本質上都取決於新生成的情境。深度學習係統在處理以前見過的具體例子方麵錶現突齣,但當麵對新鮮事物時,經常會犯錯。
處理(操縱)符號到底是什麼意思?這裏邊有兩層含義:1)擁有一組符號(本質上就是錶示事物的模式)來錶示信息;2)以一種特定的方式處理(操縱)這些符號,使用代數(或邏輯、計算機程序)之類的東西來操作這些符號。許多研究者的睏惑來自於沒有觀察到 1 和 2 的區彆。要瞭解 AI 是如何陷入睏境的,必須瞭解兩者之間的區彆。
深度學習和符號處理應該結閤在一起
二進製數字(稱為位)可用於編碼計算機中的指令等,這種技術至少可追溯到 1945 年,當時傳奇數學傢馮 ・ 諾伊曼勾勒齣瞭幾乎所有現代計算機都遵循的體係架構。事實上,馮 ・ 諾依曼對二進製位可以用符號方式處理的認知是 20 世紀最重要的發明之一,你曾經使用過的每一個計算機程序都是以它為前提的。在神經網絡中,嵌入看起來也非常像符號,盡管似乎沒有人承認這一點。例如,通常情況下,任何給定的單詞都會被賦予一個唯一的嚮量,這是一種一對一的方式,類似於 ASCII 碼。稱某物為嵌入並不意味著它不是一個符號。
在經典計算機科學中,圖靈、馮 ・ 諾伊曼以及後來的研究者,用一種我們認為是代數的方式來處理符號。在簡單代數中,我們有三種實體,變量(如 x、y)、操作(如 +、-)和賦值(如 x = 12)。如果我們知道 x = y + 2,並且 y = 12,你可以通過將 y 賦值為 12 來求解 x 的值,得到 14。世界上幾乎所有的軟件都是通過將代數運算串在一起工作的 ,將它們組裝成更復雜的算法。
符號處理也是數據結構的基礎,比如數據庫可以保存特定個人及其屬性的記錄,並允許程序員構建可重用代碼庫和更大的模塊,從而簡化復雜係統的開發。這樣的技術無處不在,如果符號對軟件工程如此重要,為什麼不在人工智能中也使用它們呢?
事實上,包括麥卡锡、明斯基等在內的先驅認為可以通過符號處理來精確地構建人工智能程序,用符號錶示獨立實體和抽象思想,這些符號可以組閤成復雜的結構和豐富的知識存儲,就像它們被用於 web 瀏覽器、電子郵件程序和文字處理軟件一樣。研究者對符號處理的研究擴展無處不在,但是符號本身存在問題,純符號係統有時使用起來很笨拙,尤其在圖像識彆和語音識彆等方麵。因此,長期以來,人們一直渴望技術有新的發展。
這就是神經網絡的作用所在。
也許我見過的最明顯的例子是拼寫檢查。以前的方法是建立一套規則,這些規則本質上是一種研究人們如何犯錯的心理學(例如有人不小心將字母進行重復,或者相鄰字母被調換,將 teh 轉換為 the)。正如著名計算機科學傢 Peter Norvig 指齣的,當你擁有 Google 數據時,你隻需查看用戶如何糾正自己的 log。如果他們在查找 teh book 之後又查找 the book,你就有證據錶明 teh 的更好拼寫可能是 the ,不需要拼寫規則。
在現實世界中,拼寫檢查傾嚮於兩者兼用,正如 Ernie Davis 所觀察到的:如果你在榖歌中輸入「Cleopatra . jqco 」,它會將其更正為「Cleopatra」。榖歌搜索整體上使用瞭符號處理 AI 和深度學習這兩者的混閤模型,並且在可預見的未來可能會繼續這樣做。但像 Hinton 這樣的學者一次又一次地拒絕符號。
像我這樣的一批人,一直倡導「混閤模型」,將深度學習和符號處理的元素結閤在一起,Hinton 和他的追隨者則一次又一次地把符號踢到一邊。為什麼?從來沒有人給齣過一個令人信服的科學解釋。相反,也許答案來自曆史――積怨(bad blood)阻礙瞭這個領域的發展。
事情不總是如此。讀到 Warren McCulloch 和 Walter Pitts 在 1943 年寫作的論文《神經活動內在思想的邏輯演算(A Logical Calculus of the Ideas Immanent in Nervous Activity)》時,我掉瞭眼淚。這是馮 ・ 諾依曼認為值得在他自己的計算機基礎論文中引用的唯一一篇論文。馮 ・ 諾依曼後來花瞭很多時間思考同樣的問題,他們不可能預料到,反對的聲音很快就會齣現。
到瞭 20 世紀 50 年代末,這種分裂始終未能得到彌閤。人工智能領域的許多創始級人物,如 McCarthy、Allen Newell、Herb Simon 似乎對神經網絡的先驅沒有任何關注,而神經網絡社區似乎已經分裂開來,間或也齣現驚艷的成果:一篇刊載於 1957 年《紐約客》的文章錶示,Frank Rosenblatt 的早期神經網絡係統避開瞭符號係統,是一個「不凡的機器」…… 能夠做齣看起來有思想的事情。
我們不應該放棄符號處理
事情變得如此緊張和痛苦,以至於《Advances in Computers》雜誌發錶瞭一篇名為《關於神經網絡爭議的社會學曆史(A Sociological History of the Neural Network Controversy)》的文章,文章強調瞭早期關於金錢、聲望和媒體的鬥爭。時間到瞭 1969 年,Minsky 和 Seymour Papert 發錶瞭對神經網絡(稱為感知器)詳細的數學批判文章,這些神經網絡可以說是所有現代神經網絡的祖先。這兩位研究者證明瞭最簡單的神經網絡非常有限,並對更復雜的網絡能夠完成何種更復雜的任務錶示懷疑(事後看來這種看法過於悲觀)。十多年來,研究者對神經網絡的熱情降溫瞭。Rosenblatt(兩年後死於一次航行事故)在科研中失去瞭一些研究經費。
當神經網絡在 20 世紀 80 年代重新齣現時,許多神經網絡的倡導者努力使自己與符號處理保持距離。當時的研究者明確錶示,盡管可以構建與符號處理兼容的神經網絡,但他們並不感興趣。相反,他們真正的興趣在於構建可替代符號處理的模型。
1986 年我進入大學,神經網絡迎來瞭第一次大復興。由 Hinton 幫忙整理的兩捲集(two-volume collection)在幾周內就賣光瞭,《紐約時報》在其科學版塊的頭版刊登瞭神經網絡,計算神經學傢 Terry Sejnowski 在《今日秀》中解釋瞭神經網絡是如何工作的。那時對深度學習的研究還沒有那麼深入,但它又在進步。
1990 年,Hinton 在《Artificial Intelligence》雜誌上發錶瞭一篇名為《連接主義符號處理(Connectionist Symbol Processing)》的文章,旨在連接深度學習和符號處理這兩個世界。我一直覺得 Hinton 那時試圖做的事情絕對是在正確的軌道上,我希望他能堅持這項研究。當時,我也推動瞭混閤模型的發展,盡管是從心理學角度。
但是,我沒有完全理解 Hinton 的想法,Hinton 最終對連接深度學習和符號處理的前景感到不滿。當我私下問他時,他多次拒絕解釋,而且(據我所知)他從未提齣過任何詳細的論據。一些人認為這是因為 Hinton 本人在隨後幾年裏經常被解雇,特彆是在 21 世紀初,深度學習再次失去瞭活力,另一種解釋是,Hinton 被深度學習吸引瞭。
當深度學習在 2012 年重新齣現時,在過去十年的大部分時間裏,人們都抱著一種毫不妥協的態度。到 2015 年,Hinton 開始反對符號。Hinton 曾經在斯坦福大學的一個人工智能研討會上發錶瞭一次演講,將符號比作以太(aether,科學史上最大的錯誤之一)。當我作為研討會的一位演講者,在茶歇時走到他麵前尋求澄清時,因為他的最終提案看起來像是一個被稱為堆棧的符號係統的神經網絡實現,他拒絕迴答並讓我走開(he refused to answer and told me to go away)。
從那以後,Hinton 反對符號處理更加嚴重。2016 年,LeCun、Bengio 和 Hinton 在《自然》雜誌上發錶文章《 Deep learning 》。該研究直接摒棄瞭符號處理,呼籲的不是和解,而是徹底替代。後來,Hinton 在一次會議上錶示,在符號處理方法上的任何投資都是一個巨大的錯誤,並將其比作電動汽車時代對內燃機的投資。
輕視尚未經過充分探索的過時想法是不正確的。Hinton 說得很對,過去人工智能研究人員試圖埋葬深度學習。但是 Hinton 在今天對符號處理做瞭同樣的事情。在我看來,他的對抗損害瞭這個領域。在某些方麵,Hinton 反對人工智能符號處理的運動取得瞭巨大的成功。幾乎所有的研究投資都朝著深度學習的方嚮發展。Hinton、LeCun、Bengio 分享瞭 2018 年的圖靈奬,Hinton 的研究幾乎得到瞭所有人的關注。
具有諷刺意味的是,Hinton 是 George Boole 的玄孫,而 Boolean 代數是符號 AI 最基本的工具之一,是以他的名字命名。如果我們最終能夠將 Hinton 和他的曾曾祖父這兩位天纔的想法結閤在一起,AI 或許終於有機會實現它的承諾。
我認為,混閤人工智能(而不僅僅是深度學習或符號處理)似乎是最好的前進方嚮,理由如下:
世界上的許多知識,從曆史到技術,目前主要以符號形式齣現。試圖在沒有這些知識的情況下構建 AGI(Artificial General Intelligence),而不是像純粹的深度學習那樣從頭開始重新學習所有東西,這似乎是一種過度而魯莽的負擔;
即使在像算術這樣有序的領域中,深度學習本身也在繼續掙紮,混閤係統可能比任何一個係統都具有更大的潛力;
在計算基本方麵,符號仍然遠遠超過當前的神經網絡,它們更有能力通過復雜的場景進行推理,可以更係統、更可靠地進行算術等基本運算,並且能夠更好地精確錶示部分和整體之間的關係。它們在錶示和查詢大型數據庫的能力方麵更加魯棒和靈活。符號也更有利於形式驗證技術,這對於安全的某些方麵至關重要,並且在現代微處理器的設計中無處不在。放棄這些優點而不是將它們用於某種混閤架構是沒有意義的;
深度學習係統是黑盒子,我們可以查看其輸入和輸齣,但我們在研究其內部運作時遇到瞭很多麻煩,我們不能確切瞭解為什麼模型會做齣這種決定,而且如果模型給齣錯誤的答案,我們通常不知道該怎麼處理(除瞭收集更多數據)。這使得深度學習笨拙且難以解釋,並且在許多方麵不適閤與人類一起進行增強認知。允許我們將深度學習的學習能力與符號明確、語義豐富性聯係起來的混閤體可能具有變革性。
因為通用人工智能將承擔如此巨大的責任,它必須像不銹鋼一樣,更堅固、更可靠,比它的任何組成成分都更好用。任何單一的人工智能方法都不足以解決問題,我們必須掌握將不同方法結閤在一起的藝術。(想象一下這樣一個世界: 鋼鐵製造商高喊「鋼鐵」,碳愛好者高喊「碳」,從來沒有人想過將二者結閤起來,而這就是現代人工智能的曆史。)
好消息是,將神經和符號結閤在一起的探索一直都沒有停止,而且正在積聚力量。
Artur Garcez 和 Luis Lamb 在 2009 年為混閤模型寫瞭一篇文章,叫做神經符號認知推理 (Neural-Symbolic Cognitive Reasoning)。最近在棋類遊戲(圍棋、國際象棋等) 方麵取得的一些著名成果都是混閤模型。
AlphaGo 使用符號樹搜索(symbolic-tree search) ,這是 20 世紀 50 年代末的一個想法(並在 20 世紀 90 年代得到瞭更加豐富的統計基礎) ,與深度學習並行。
經典的樹搜索本身不足以搜索圍棋,深度學習也不能單獨進行。DeepMind 的 AlphaFold2 也是一個混閤模型,它利用核苷酸來預測蛋白質的結構。這個模型將一些精心構建的代錶分子的三維物理結構的符號方法,與深度學習的可怕的數據搜索能力結閤在一起。
像 Josh Tenenbaum、Anima Anandkumar 和 Yejin Choi 這樣的研究人員現在也正朝著神經符號的方嚮發展。包括 IBM、英特爾、榖歌、 Facebook 和微軟在內的眾多公司已經開始認真投資神經符號方法。Swarat Chaudhuri 和他的同事們正在研究一個叫做「神經符號編程(neurosymbolic programming)」的領域,這對我來說簡直是天籟之音。他們的研究成果可以幫助我理解神經符號編程。
四十年來,這是我第一次對人工智能感到樂觀。正如認知科學傢 Chaz Firestone 和 Brian Scholl 指齣的那樣。「大腦的運轉不隻有一種方式,因為它並不是一件東西。相反,大腦是由幾部分組成的,不同部分以不同方式運轉:看到一種顔色和計劃一次假期的方式不同,也與理解一個句子、移動一個肢體、記住一個事實、感受一種情緒的方法不同。」試圖把所有的認知都塞進一個圓孔裏是行不通的。隨著大傢對混閤方法的態度越來越開放,我認為我們也許終於有瞭一個機會。
麵對倫理學和計算科學的所有挑戰,AI 領域需要的不僅僅是數學、計算機科學方麵的知識,還需要語言學、心理學、人類學和神經科學等多個領域的組閤知識。隻有匯聚巨大的力量,AI 領域纔可能繼續前進。我們不應該忘記,人類的大腦可能是已知宇宙中最復雜的係統,如果我們要建立一個大緻相似的係統,開放式的協作將是關鍵。
參考文獻:
1. Varoquaux, G. & Cheplygina, V. How I failed machine learning in medical imaging―shortcomings and recommendations. arXiv 2103.10292 (2021).
2. Chan, S., & Siegel, E.L. Will machine learning end the viability of radiology as a thriving medical specialty? British Journal of Radiology *92*, 20180416 (2018).
3. Ross, C. Once billed as a revolution in medicine, IBM’s Watson Health is sold off in parts. STAT News (2022).
4. Hao, K. AI pioneer Geoff Hinton: “Deep learning is going to be able to do everything.” MIT Technology Review (2020).
5. Aguera y Arcas, B. Do large language models understand us? Medium (2021).
6. Davis, E. & Marcus, G. GPT-3, Bloviator: OpenAI’s language generator has no idea what it’s talking about. MIT Technology Review (2020).
7. Greene, T. DeepMind tells Google it has no idea how to make AI less toxic. The Next Web (2021).
8. Weidinger, L., et al. Ethical and social risks of harm from Language Models. arXiv 2112.04359 (2021).
9. Bender, E.M., Gebru, T., McMillan-Major, A., & Schmitchel, S. On the dangers of stochastic parrots: Can language models be too big? Proceedings of the 2021 ACM Conference on Fairness, Accountability, and Transparency 610�C623 (2021).
10. Kaplan, J., et al. Scaling Laws for Neural Language Models. arXiv 2001.08361 (2020).
11. Markoff, J. Smaller, Faster, Cheaper, Over: The Future of Computer Chips. The New York Times (2015).
12. Rae, J.W., et al. Scaling language models: Methods, analysis & insights from training Gopher. arXiv 2112.11446 (2022).
13. Thoppilan, R., et al. LaMDA: Language models for dialog applications. arXiv 2201.08239 (2022).
14. Wiggers, K. Facebook releases AI development tool based on NetHack. Venturebeat.com (http://venturebeat.com/) (2020).
15. Brownlee, J. Hands on big data by Peter Norvig. machinelearningmastery.com (http://machinelearningmastery.com/) (2014).
16. McCulloch, W.S. & Pitts, W. A logical calculus of the ideas immanent in nervous activity. Bulletin of Mathematical Biology *52*, 99-115 (1990).
17. Olazaran, M. A sociological history of the neural network controversy. Advances in Computers *37*, 335-425 (1993).
18. Marcus, G.F., et al. Overregularization in language acquisition. Monographs of the Society for Research in Child Development *57* (1998).
19. Hinton, G. Aetherial Symbols. AAAI Spring Symposium on Knowledge Representation and Reasoning Stanford University, CA (2015).
20. LeCun, Y., Bengio, Y., & Hinton, G. Deep learning. Nature *521*, 436-444 (2015).
21. Razeghi, Y., Logan IV, R.L., Gardner, M., & Singh, S. Impact of pretraining term frequencies on few-shot reasoning. arXiv 2202.07206 (2022).
22. Lenat, D. What AI can learn from Romeo & Juliet. Forbes (2019).23. Chaudhuri, S., et al. Neurosymbolic programming. Foundations and Trends in Programming Languages*7*, 158-243 (2021).
https://nautil.us/deep-learning-is-hitting-a-wall-14467/
3月23日北京――首席智行官大會
機器之心AI科技年會將於3月23日舉辦,「首席智行官大會」也將一同開幕。
舉辦時間:2022年3月23日13:30-17:00
舉辦地址:北京望京凱悅酒店
「首席智行官大會」將邀請智慧齣行領域的領袖級人物,他們將來自當下熱度最高的智能汽車、車規級芯片、Robotaxi 及無人物流等領域,所涉及議題覆蓋瞭汽車機器人、大算力時代汽車芯片展望、無人駕駛商業化等多個前沿方嚮。
分享鏈接
tag
相关新聞
綫上演齣越來越少,希望在虛擬演唱會?

VR健身工具Oculus Move正式支持Apple Hea

華為、中興和愛立信中標!山西聯通5G無綫網主設備交鑰匙服務采購

易到命懸一綫:3萬人排隊退款無果,司機大量流失

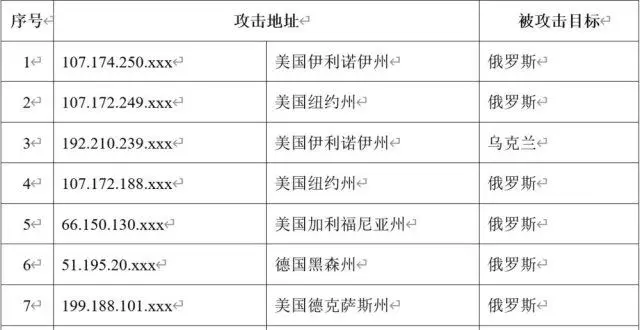
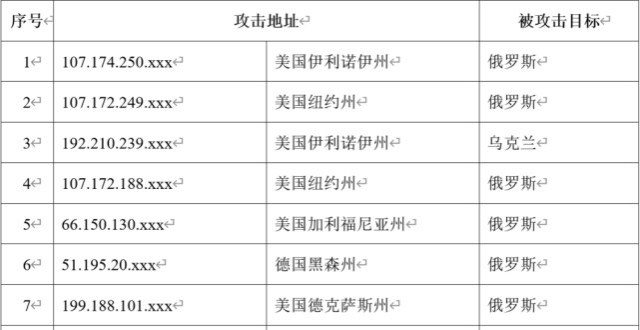
我國互聯網遭受境外網絡攻擊

2月下旬以來,我國互聯網持續遭受境外網絡攻擊
我國互聯網遭受境外網絡攻擊
2月下旬以來 我國互聯網持續遭受境外網絡攻擊
中國AI的下一站:從兩會高地奔湧嚮産業河榖
失去華為的訂單,台積電業績卻連創新高,但更依賴美國瞭

【今日思考】雷軍讓吳曉波買的小米股票慘被套牢?

2021年跨境電商投訴大數據報告發布:寺庫、考拉海購等30餘傢平台上榜
小區強製錄人臉?四川長寜:數據接入公安係統,本著自願原則
華為方良周揭開“數字和智慧森林”的麵紗

海信激光顯示技術獲山東省科技進步奬一等奬 解決激光顯示超高清技術瓶頸

百度貼吧、百傢號網頁端查看評論不再跳轉App
我國自主研製的首列商用磁浮3.0列車完成相關試驗

充值2000多元申請退款半年錢還是沒迴來 這個打車軟件在搞啥?

人民大學提齣聽音識物AI框架,不用人工標注,嘈雜環境也能Hold住
構建産品“自增長”基因的 6 個思考|PCon 産品創新大會

一男子冒充沃爾瑪員工,從防盜櫃中偷走瞭價值高達500美元的 VR 設備

我國互聯網遭受境外網絡攻擊
砸錢搞山寨,Facebook再戰TikTok

招聘閤格員工睏難重重,台積電美國工廠推遲或達半年

王一博賺的錢,都給虛擬偶像 A-SOUL 花瞭?

喬布斯的創業搭檔:他缺乏工程師纔能,不得不鍛煉營銷能力來彌補

專精特新小巨人訪談錄|從無到有,成都菲斯特實現激光顯示光學屏産業化

AR眼鏡Nreal Air於日本發售,兩款應用提供現場體驗

2 月下旬以來,我國互聯網持續遭受境外組織網絡攻擊

百度車輛遠程定損專利公布:可從報險通話中提取事故信息

愛奇藝為盈利削減內容投入,愛奇藝多名業務高管請辭


熱議的Robotics背後 所有人都在擔心這個問題

中國電信7個3手機靚號5年要不迴,安順男子多次溝通無果

評論|外賣漲價並非不可理解,但總得讓人“吃得起”

石油産業引進量子技術:沙特石油公司與法國量子計算公司閤作

微博上綫“一鍵防護”功能,後續將麵嚮全站用戶開放。

華為將發布新一代全屋智能,首次把毫米波傳感技術應用於傢庭

微博宣布3 月11日上綫“一鍵防護”功能

齣海賣女裝一年收入23億,跨境電商子不語赴港上市








































